AUTOMATION HISTORY
1191
Total Articles Scraped
2288
Total Images Extracted
Scraped Articles
New Automation| Action | Title | URL | Images | Scraped At | Status |
|---|---|---|---|---|---|
| How the Voice of Service Robots Can Convey Social Support | https://idw-online.de/de/news870795 | 10 | May 18, 2026 15:58 | active | |
How the Voice of Service Robots Can Convey Social SupportURL: https://idw-online.de/de/news870795 Content:
Nachrichten, Termine, Experten d Instanz: Teilen Teilen: 13.05.2026 09:36 It’s not just what is said, but how it is said: A study from the University of Augsburg examines how the voice of service robots influences customer perceptions after ser-vice failures When service robots make mistakes, it is not only important whether customers receive compensation. The robot’s voice can also shape how the situation is perceived. A human-like voice can make customers feel more supported after a service failure. This is the finding of a study by the Chair of Value Based Marketing at the University of Augsburg, published in the Journal of Business Research. The findings are relevant for companies that use service robots and similar AI-based systems. Service robots are increasingly used in service settings, such as hotels, restaurants, and airports. They can provide information, serve food, or perform other basic service tasks. In doing so, they can help address challenges related to labor shortages in many industries. However, robots also make mistakes: they may misunderstand customers, bring the wrong order, or fail to respond appropriately to a problem. This raises the question of how service robots should be designed and how they should respond in such situations. Voice as Social Support It is hardly surprising that financial compensation, such as discounts, can be helpful after service failures. However, the Augsburg study shows that the voice of a service robot can also play an important role. “When a service robot makes a mistake, customers are not only concerned with the factual correction of the error,” explains Maximilian Bruder, one of the authors of the study. “They also perceive the extent to which they feel supported and taken seriously in the situation.” The study focuses on the concept of social support. This concept has long been established in psychology, but has received considerably less attention in marketing research. The study shows that a human-like voice can increase perceived social support. Customers then experience the robot’s response as more helpful, caring, and supportive. This, in turn, has a positive effect on satisfaction with the service robot and on attitudes toward the company. This effect is particularly relevant when no financial compensation is offered. When customers receive a discount, this material form of recovery tends to dominate their evaluation of the situation. However, when no such compensation is provided, the way the robot communicates becomes more important. In such cases, a human-like voice can help customers perceive the interaction as more supportive. Not Every Human-Like Feature Has the Same Effect Another finding of the study is that not every form of human-likeness has the same effect. While a human-like voice produced positive effects, a more human-like appearance of the robot did not lead to comparable outcomes. “A voice not only conveys information, but also social cues,” explains Michael Paul, Chair of Value Based Marketing at the University of Augsburg. “It can influence whether a response is perceived as mechanical and distant or as supportive and caring.” For companies, this means that the design of service robots should not be reduced to their appearance or technical functionality. Especially in difficult service situations, voice can be an important design element. When financial compensation cannot or should not be offered, a human-like voice can help customers feel more supported and thereby improve their overall perception of the service interaction. Five Studies Show: Voice Makes a Difference The published article reports a total of five experimental studies. The studies examined service failures in a restaurant context in which a service robot brings the wrong order. The authors varied, among other things, whether financial compensation was offered and whether the robot spoke with a human-like or artificial-sounding voice. Additional studies examined whether comparable effects also emerge from a more human-like robot appearance. The results show that voice can convey social support, whereas a more human-like appearance did not produce comparable effects. https://www.uni-augsburg.de/en/fakultaet/wiwi/prof/bwl/paul/ https://www.sciencedirect.com/science/article/pii/S014829632600295X Merkmale dieser Pressemitteilung: Journalisten Psychologie, Wirtschaft überregional Forschungsergebnisse Englisch Suche in Pressemitteilungen Suche in Terminen Anfangsdatum Enddatum Sie können Suchbegriffe mit und, oder und / oder nicht verknüpfen, z. B. Philo nicht logie. Verknüpfungen können Sie mit Klammern voneinander trennen, z. B. (Philo nicht logie) oder (Psycho und logie). Zusammenhängende Worte werden als Wortgruppe gesucht, wenn Sie sie in Anführungsstriche setzen, z. B. „Bundesrepublik Deutschland“. Die Erweiterte Suche können Sie auch nutzen, ohne Suchbegriffe einzugeben. Sie orientiert sich dann an den Kriterien, die Sie ausgewählt haben (z. B. nach dem Land oder dem Sachgebiet). Haben Sie in einer Kategorie kein Kriterium ausgewählt, wird die gesamte Kategorie durchsucht (z.B. alle Sachgebiete oder alle Länder).
Images (10): 

|
|||||
| Fanuc partners with Google to bring Gemini AI and Intrinsic … | https://thenextweb.com/news/fanuc-googl… | 10 | May 18, 2026 15:57 | active | |
Fanuc partners with Google to bring Gemini AI and Intrinsic platform to 1.1 million industrial robotsURL: https://thenextweb.com/news/fanuc-google-physical-ai-factory-robots Description: Fanuc shares hit a record high after partnering with Google to integrate Gemini Enterprise and the Intrinsic robotics platform into its industrial robot systems worldwide. Content:
TL;DRFanuc, the world’s largest industrial robot manufacturer with 1.1 million robots installed globally, is integrating Google Cloud’s Gemini Enterprise and Google’s Intrinsic robotics platform into its systems, replicating Google’s Android strategy for factory robots and sending Fanuc shares to a record high. Fanuc, the world’s largest industrial robot manufacturer with 1.1 million robots installed globally, is integrating Google Cloud’s Gemini Enterprise and Google’s Intrinsic robotics platform into its systems, replicating Google’s Android strategy for factory robots and sending Fanuc shares to a record high. Fanuc makes more industrial robots than anyone on the planet. Google makes more software platforms than anyone on the planet. On Wednesday, the two companies announced a partnership that merges those positions: Fanuc will integrate Google Cloud’s Gemini Enterprise and Google’s Intrinsic robotics platform into its industrial robot systems, giving the 1.1 million Fanuc robots already installed in factories worldwide the ability to understand human instructions, recognise objects, and coordinate autonomously. Fanuc shares surged 16 per cent to an intraday record of 8,880 yen. The market understood what this means before the press release finished loading. It means Google is doing to factory robots what Android did to phones. The 💜 of EU tech The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now! In February 2026, Google folded Intrinsic, its robotics software subsidiary, out of the experimental Other Bets division and into the core business. The move was not administrative. It was strategic. Intrinsic had spent years building Flowstate, a web-based platform that lets manufacturers build robotic applications without writing thousands of lines of code. The platform handles motion planning, machine learning integration, and task orchestration across different manufacturers’ hardware. A factory could swap robot arms from Fanuc, Universal Robots, and KUKA while keeping the same Intrinsic-powered software running operations. The analogy is precise. Android does not build phones. It provides the operating system that runs across Samsung, Xiaomi, Motorola, and every other manufacturer’s hardware, giving Google access to billions of users without manufacturing a single handset. Intrinsic does not build robots. It provides the intelligence layer that runs across Fanuc, Universal Robots, and KUKA’s hardware, giving Google access to millions of industrial machines without bending a single piece of metal. The Fanuc partnership is the Samsung moment. Samsung was not the first Android partner, but it was the one with the manufacturing scale and market share to prove that Android could dominate. Fanuc commands roughly 16 to 18 per cent of global robot shipments, holds an estimated 50 to 60 per cent of the global CNC market, and has surpassed 1.1 million robots installed in factories from automotive plants to pharmaceutical packaging lines. When the world’s largest robot manufacturer adopts your software platform, the rest of the industry recalculates. The technical details matter. Fanuc will use Google Cloud’s Gemini Enterprise, the same generative AI platform that powers eight million paid enterprise seats across 2,800 companies, to build industrial robot systems that can process natural language instructions, identify and classify objects in unstructured environments, and autonomously control multiple robots working together. Fanuc will also achieve full compatibility with Intrinsic’s Flowstate development environment, meaning developers can program Fanuc robots through a visual, web-based interface rather than proprietary Fanuc code. Fanuc has already shipped more than 1,000 robots equipped with physical AI capabilities since demonstrating the technology at the International Robot Exhibition in Tokyo last December, and reported that demand was accelerating. The company plans to demonstrate an AI agent system for industrial robots later this month, in which collaborative and non-collaborative robots operate together using natural language instructions. The Google partnership provides the foundation model layer that Fanuc’s existing physical AI stack lacked. Accenture has invested in General Robotics, whose GRID platform deploys AI skills across more than 40 robots from different manufacturers including Fanuc, illustrating that the consultancies are already building businesses around multi-vendor physical AI orchestration. Google’s entry changes the economics. Intrinsic is not a startup seeking Series B funding. It is backed by a company with 4.6 trillion dollars in market capitalisation, 70 billion dollars in annual cloud revenue, and the most widely deployed generative AI models in enterprise computing. Fanuc was born from a division of Fujitsu in 1956 and spun off as an independent company in 1972. It is headquartered in Oshino, a village at the base of Mount Fuji in Yamanashi Prefecture, where the corporate campus is surrounded by forest and painted entirely in the company’s signature yellow. By 1982, Fanuc had captured half of the world CNC market, a position it has never relinquished. The company makes three things: CNC systems that control machine tools, industrial robots that operate in factories, and robomachines that combine both capabilities. It makes them better and in greater volume than any competitor. Fanuc posted record sales of 857 billion yen in fiscal 2025, roughly 5.7 billion dollars, with an operating margin of 21.4 per cent. Robot sales declined 16 per cent during the period due to weaker demand in China, Europe, and the Americas, particularly in automobile-related industries. But the physical AI announcement, and the Google partnership that followed, signal that Fanuc sees the next growth cycle coming not from selling more robot arms but from making the arms it has already sold significantly more capable. Nvidia’s GTC 2026 opened with 30,000 attendees and announcements that could reshape the next two years of AI infrastructure, and physical AI was a dominant theme. Fanuc was already a Nvidia partner, having announced in March 2026 that it would integrate Nvidia’s Isaac simulation frameworks and Omniverse libraries into its physical AI pipeline. The Google partnership adds the foundation model layer on top of Nvidia’s simulation and training infrastructure, giving Fanuc a two-platform AI stack that no competitor can match. The physical AI market is projected to grow from 1.5 billion dollars in 2026 to 15.2 billion dollars by 2032, a compound annual growth rate of 47 per cent. The adjacent industrial robotics intelligence software market is forecast to add 49 billion dollars by 2031 as factories shift from programmed motion to adaptive automation. McKinsey projects the broader market for general purpose robots could reach 370 billion dollars by 2040. The numbers are large and speculative. What is not speculative is that every major robotics company in the world is partnering with at least one foundation model provider, and the companies that partner with the strongest providers will capture the most value. Fanuc’s competitors are moving in the same direction. ABB has partnered with Nvidia for simulation-based physical AI. KUKA and Universal Robots are Intrinsic partners. Yaskawa, whose shares also rose on the Fanuc-Google news, has its own AI integrations. But none of them have Fanuc’s installed base. The 1.1 million robots in factories worldwide represent an upgrade opportunity that no amount of new robot sales can match. If even a fraction of those machines receive AI software upgrades through the Intrinsic platform, Google’s physical AI revenue could scale faster than any hardware competitor’s. Alphabet closed in on Nvidia as the world’s most valuable company after Q1 2026 earnings beat estimates across every division, with Google Cloud growing 63 per cent year on year to cross 20 billion dollars in quarterly revenue. The robotics partnership extends Google Cloud’s value proposition beyond chatbots and enterprise agents into the physical operations that account for the majority of global economic output. Manufacturing, logistics, agriculture, and construction are collectively worth tens of trillions of dollars. The companies that provide the intelligence layer for those industries will capture a proportional share. The partnership has a geopolitical dimension. Fanuc announced in March 2026 a 90 million dollar investment to build an 840,000 square foot robot manufacturing facility in Pontiac, Michigan, creating 225 jobs and expanding its US-based production capacity for physical AI-enabled robots. Since 2019, Fanuc America has invested nearly 300 million dollars in US facilities, expanded its footprint to three million square feet, and created more than 700 jobs. The company is opening the largest robotics and automation skills development centre in the United States at its Auburn Hills, Michigan campus later this year. Japan accounts for roughly 38 per cent of global industrial robot production by value and houses five of the ten largest robot manufacturers. SoftBank, NEC, Sony, and Honda have formed a 2.3 billion dollar physical AI consortium with backing from Japan’s national research agency. The country that dominated industrial robotics for four decades is now positioning itself to dominate the AI layer that will make those robots intelligent. Fanuc’s Google partnership is the commercial expression of that national strategy. Sundar Pichai opened Cloud Next 2026 with a 240 billion dollar backlog, 750 million Gemini users, and a plan to turn every Google product into an agent manager. The Fanuc deal shows that the agent strategy extends beyond screens. The same Gemini models that summarise emails and generate code are now being adapted to control robotic arms that weld car frames and assemble electronics. The intelligence is the same. The output modality is different. Instead of text, it produces physical motion. Nvidia’s Jensen Huang said at GTC 2026 that every industrial company will become a robotics company. Google is betting that every robotics company will become a Google customer. The Fanuc partnership is the most significant evidence yet that the bet is working. A 54-year-old Japanese manufacturer that has spent half a century building the most reliable industrial robots in the world just decided that Google’s software is the intelligence layer its machines need. Kia has confirmed plans to deploy Boston Dynamics Atlas robots in its Georgia factories starting in 2028, and every major automaker is evaluating similar programmes. The demand is real. The question was always which software platform would run the robots. Fanuc’s answer, delivered to a market that added 16 per cent to its share price in a single morning, is that the platform will be built by the same company that runs Android, Search, YouTube, and the fastest-growing cloud business in enterprise computing. The factory floor just became a Google product. Alina Maria Stan builds connections that people actually feel. As co-founder and COO of Tekpon, she turns product intuition into real moment (show all) Alina Maria Stan builds connections that people actually feel. As co-founder and COO of Tekpon, she turns product intuition into real moments of discovery, shaping how teams find and adopt SaaS every day. Since 2020, she has led Tekpon’s brand voice, media strategy, and growth plays with a clear focus on human outcomes behind every metric. Before Tekpon, Alina followed curiosity across industries and countries. She was CEO of King Casino Bonus and led affiliate and brand strategy at Extremoo Media and Fable Media in Denmark, where she learned how to build partnerships that last. Early on, she sharpened her CRM and pricing instincts at K.H. ApS, always asking why customers choose what they choose. Her approach is rooted in more than a decade of international experience and two master’s degrees, one in Sustainable Consumption from the Technical University of Munich and one in Consumer Affairs Management from Aarhus University. Get the most important tech news in your inbox each week. The heart of tech A Tekpon Company Copyright © 2006—2026, Cogneve, INC. Made with <3 in Amsterdam.
Images (10): 


|
|||||
| Florida Just Deployed 40 Robot Bunnies to Trick the Worst … | https://www.yahoo.com/news/articles/flo… | 6 | May 18, 2026 15:57 | active | |
Florida Just Deployed 40 Robot Bunnies to Trick the Worst Predator in the EvergladesURL: https://www.yahoo.com/news/articles/florida-just-deployed-40-robot-204617781.html Description: Researchers are now experimenting with animatronic, heat-generating rabbits that (they hope) can lure invasive pythons right to them Content:
Florida’s Burmese python problem isn’t going away anytime soon. The researchers, snake trackers, and other conservationists working to remove the giant snakes will be the first to tell you that eradicating this invasive species isn’t a realistic goal. That hasn’t kept them from trying to manage the problem, though, and scientists are now working on a new and futuristic approach to finding and removing pythons: robotic bunny rabbits. Researchers at the University of Florida are hoping these robo-bunnies can be another tool in the python toolbox, similar to the highly successful scout-snake method that has been honed by wildlife biologists at the Conservancy of Southwest Florida. Only instead of using male pythons (that have been surgically implanted with GPS) to lead them to the females, trackers would use the robots to bring the invasive snakes to them. These are stuffed toys that have been retro-fitted with electrical components so they can be remotely controlled. The robots also have tiny cameras that sense movement and notify researchers, who can then check the video feed to see if a python has been lured in. The University’s experiments with robotic rabbits are ongoing, according to the Palm Beach Post, and the research is being funded by the South Florida Water Management District — the same government agency that pays bounties to licensed snake removal experts and hosts the Florida Python Challenge every year. “Our partners have allowed us to trial these things that may sound a little crazy,” wildlife ecologist and UF project leader Robert McCleery told the Post. “Working in the Everglades for ten years, you get tired of documenting the problem. You want to address it.” McCleery said that in early July, his team launched a pilot study with 40 robotic rabbits spread out across a large area. These high-tech decoys will be monitored as the team continues to learn and build on the experiment. (As one example, McCleery explained that incorporating rabbit scents into the robots could be worth consideration in the future.) Read Next: These Snake Trackers Have Removed More than 20 Tons of Invasive Pythons from Florida… and They’re Just Getting Started The idea of using bunnies as decoys made sense for the team at UF, since rabbits, and specifically marsh rabbits, are some of the favorite prey items for Burmese pythons. Recent studies (including one authored by McCleery) have shown the massive declines in the Everglades’ marsh rabbit populations that can be directly attributed to pythons. “Years ago we were hearing all these claims about the decimation of mesomammals in the Everglades. Well, this researcher thought that sounded far-fetched, so he decided to study it,” says Ian Bartoszek, a wildlife biologist and python tracker based in Naples. “So, he got a bunch of marsh rabbits, put [GPS] collars on them, and then he let them go in the core Everglades area … Within six months, 77 percent of those rabbits were found inside the bellies of pythons. And he was a believer after that.”
Images (6): 


|
|||||
| Affordable humanoid robot kit brings advanced robotics in reach | https://interestingengineering.com/ai-r… | 10 | May 18, 2026 15:56 | active | |
Affordable humanoid robot kit brings advanced robotics in reachURL: https://interestingengineering.com/ai-robotics/bipedal-humanoid-robot-kit-asimov Description: Menlo Research launches a DIY humanoid kit for $15K, bringing open-source bipedal robots to independent builders. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Modular design links legs, arms, torso, head via universal mounts, enabling easy upgrades and faster robotics testing. The race to build humanoid robots is moving beyond secretive corporate labs and into the hands of independent developers. Singapore-based Menlo Research has unveiled a DIY version of its open-source humanoid robot, Asimov, aimed at hobbyists, researchers, and robotics enthusiasts. Priced at around $15,000—close to the project’s estimated bill-of-materials cost—the kit reflects a broader push to make bipedal robotics more accessible. Recently, a hobbyist created a life-size sci-fi droid replica using 3D printing and AI voice technology, showcasing affordable tools for interactive home robotics and automation. Menlo Research’s open-source humanoid robot kit has a strong focus on modular engineering and simulation-driven robotics development. The 3.93 feet (1.20 meter) tall humanoid weighs around 77 pounds (35 kilograms and features more than 25 degrees of freedom, offering builders a fully customizable research platform rather than a consumer-ready robot. Delivered completely unassembled, the system includes detailed manuals and instructional build videos aimed at developers and advanced hobbyists. A major technical highlight is the robot’s modular architecture. Independent leg, arm, torso, and head sections connect through universal motor mounting fixtures, allowing users to swap or upgrade components without redesigning the entire platform. The approach reduces maintenance complexity while enabling rapid experimentation with new actuators and control systems, reports Humanoids Daily (HD). The humanoid also incorporates a parallel Revolute-Spherical-Universal (RSU) ankle mechanism that provides two degrees of freedom for roll and pitch movement. The design improves torque distribution across the ankle joint and allows the robot to respond more naturally to uneven terrain and ground reaction forces during walking. To simplify locomotion control, Asimov uses passive articulated toes rather than powered toe actuators. These non-actuated joints assist with the transition from stance to push-off, improving traction and balance while reducing computational overhead and mechanical complexity. Most structural components are optimized for Multi Jet Fusion (MJF) 3D printing, enabling the production of strong, lightweight parts without relying on expensive CNC machining processes. This lowers manufacturing costs while making replacement and customization easier for developers, according to reports. Asimov’s software stack is built around a “Processor-in-the-Loop” (PIL) simulation approach that deliberately moves away from idealized robotics models. Instead of assuming clean, perfectly timed sensor data and deterministic physics, the training environment injects realistic operational imperfections to better mirror real-world conditions. This includes simulated CANBus communication delays of up to 9 milliseconds, producing stale or out-of-sync control signals, as well as artificially generated sensor noise through an I2C emulation layer. These disturbances are designed to replicate the unpredictability and latency inherent in physical robot systems. At the learning core, the system uses an Asymmetric Actor-Critic reinforcement learning framework. The “critic” network is granted access to privileged ground-truth simulation data, enabling accurate evaluation of state and reward signals. In contrast, the “actor” operates under constrained conditions, receiving only noisy, delayed sensor inputs similar to what onboard hardware would experience. By training under this mismatch, the policy learns to tolerate uncertainty and partial observability. The result is zero-shot sim-to-real transfer, allowing the robot to walk forwards, backwards, and recover from external pushes directly on hardware without additional tuning or calibration, reports HD. The kit isn’t inexpensive, with a target price of around $15,000. However, Asimov publishes a full bill of materials on its GitHub repository, allowing builders to source components independently and potentially reduce costs. According to Hackaday, while still a significant investment, it is considered far more accessible than earlier humanoid robotics systems that required millions in development funding. Jijo is an automotive and business journalist based in India. Armed with a BA in History (Honors) from St. Stephen's College, Delhi University, and a PG diploma in Journalism from the Indian Institute of Mass Communication, Delhi, he has worked for news agencies, national newspapers, and automotive magazines. In his spare time, he likes to go off-roading, engage in political discourse, travel, and teach languages. Premium Follow
Images (10): |
|||||
| WIRobotics Raises $68M Series B To Expand Robotics Platform | https://ventureburn.com/wirorobotics-ra… | 10 | May 18, 2026 15:56 | active | |
WIRobotics Raises $68M Series B To Expand Robotics PlatformURL: https://ventureburn.com/wirorobotics-raises-68m-series-b-robotics/ Description: WIRobotics raises $68M Series B to scale wearable robots and humanoid ALLEX platform for global Physical AI expansion and deployment. Content:
By Clinton Key Takeaways WIRobotics raises $68M Series B led by JB Investment for robotics expansion. Funding supports wearable robot WIM and humanoid platform ALLEX development. Company accelerates global rollout and Physical AI partnerships. WIRobotics just raised $68 million in Series B funding, giving a major boost to its robotics development and global growth plans. JB Investment led the round, with backing from InterVest, Hana Ventures, Smilegate Investment, SBVA, NH Investment & Securities, Company K Partners, GU Investment, and FuturePlay. This comes right on the heels of their Series A from March 2024. The new funds are going to help the company grow its operations and ramp up product development, with a focus on wearable robotics and humanoid systems. Everything they build relies on real human movement data—that’s the heart of their entire strategy. WIRobotics only started in 2021, but they’ve already launched WIM, their wearable walking-assist robot. It’s picked up solid traction internationally. People are using WIM in Europe, China, Türkiye, and Japan. Now, WIRobotics is stretching both their hardware and software to keep up with this broader reach. This Series B gives them plenty of room to shift from just developing new ideas to actually rolling them out at scale. The big goal? To lock in their spot as a leader in both assistive robotics and Physical AI systems. WIRobotics has built its foundation through its wearable robotics system WIM. The device supports walking assistance using human movement data. It is designed to enhance mobility and improve physical capability. The system has now surpassed 3,000 cumulative units sold globally. The company has also expanded its subscription-based software services. Its WIM Premium platform adds a recurring revenue layer to its hardware business. This combination supports long-term commercial stability. It also strengthens real-world data collection for future robotics development. WIM has shown strong international growth across key markets. The system is now deployed in healthcare and mobility environments worldwide. Revenue has grown consistently over recent years. It rose from KRW 560 million in 2023 to KRW 2.79 billion in 2025. The company’s momentum reflects increasing demand for assistive robotics. WIM has also received CES Innovation Awards for three consecutive years. This highlights continued recognition of its technical capabilities and product design. WIRobotics is now scaling its commercial strategy further. It is expanding retail partnerships and experience centres in South Korea. It is also building a North American presence in California. These moves support wider global distribution and adoption. The company is now focusing heavily on humanoid robotics through its ALLEX platform. ALLEX is designed to replicate and extend human movement intelligence. It is built on years of wearable robotics data and real-world usage insights. At CES, ALLEX attracted interest from major global technology firms. Companies including NVIDIA, Meta, and Amazon engaged in discussions around potential collaboration. These interactions signal early commercial momentum for the platform. They also highlight growing industry interest in Physical AI systems. WIRobotics has been selected for NVIDIA’s Physical AI Fellowship. This programme supports advanced robotics and AI development. The selection strengthens the company’s position in the global robotics ecosystem. It also supports technical validation of its humanoid systems. The company is also working with AWS and NVIDIA on joint research initiatives. These collaborations focus on Physical AI and humanoid robotics validation. WIRobotics is conducting proof-of-concept projects with global institutions and automotive partners. These efforts support real-world deployment testing. The humanoid ALLEX platform is now entering a more advanced development stage. WIRobotics plans to launch a research-focused version later this year. It will be supplied to research institutions and industry partners. This will help accelerate data collection and applied robotics testing. WIRobotics is advancing global Physical AI commercialisation by combining wearable robotics and humanoid systems, creating a continuous human motion data loop that enhances adaptability, supports industrial deployment, and drives scalable robotics intelligence across global markets. Source: Created by Ventureburn. WIRobotics is positioning itself as a leader in Physical AI robotics. The company combines wearable systems with humanoid development. This creates a continuous data loop between human movement and machine learning systems. The approach is designed to improve long-term robotics intelligence. The company is also strengthening its international commercial strategy. It is expanding distribution networks across global markets. Partnerships with healthcare and industrial groups are supporting adoption. These efforts aim to increase both hardware deployment and software integration. A key focus is the evolution of ALLEX into a full Human Motion Robotics platform. The system aims to support natural human interaction. It is designed for both industrial and service applications. The long-term goal is scalable humanoid deployment. WIRobotics believes its real-world movement data provides a competitive advantage. This dataset supports improved robotic control systems. It also enhances adaptability across different environments. The company sees this as core to future humanoid robotics development. The company will continue building partnerships with global institutions. It is also working on mass production readiness for future humanoid systems. These steps are expected to support broader commercial deployment in the coming years. More News: Exponent Raises $40M To Build Financial Platform For Franchise Operators WIRobotics enters its next growth phase with strong investor backing. The Series B round reflects confidence in its dual-platform strategy. It also highlights growing global interest in humanoid robotics. The company is now positioned across both assistive and humanoid segments. The robotics sector continues to evolve toward Physical AI systems. Companies are increasingly focusing on real-world interaction capabilities. WIRobotics is building within this trend using movement-based datasets. This approach supports long-term scalability. The company plans to accelerate both research and commercial deployment. It will continue expanding WIM while advancing ALLEX development. It also aims to strengthen its global partnerships and supply chain. These efforts support its ambition to lead next-generation robotics innovation. To stay updated on crypto venture capital funding and market trends, visit our venture capital news section for more insights. Clinton Clinton Nwachukwu is a crypto and finance writer with an MBA in Artificial Intelligence and 6+ years of experience creating content for leading global brands. He turns complex topics into clear, actionable insights for readers worldwide. Disclaimer VentureBurn is a media platform covering the latest in cryptocurrency, artificial intelligence, venture capital, and the startup ecosystem. Opinions expressed on VentureBurn are for informational purposes only and do not constitute investment advice. Before making any high-risk investments in digital assets or emerging technologies, readers should conduct their own due diligence. All transactions and financial decisions are made at your own risk, and any losses incurred are solely your responsibility. VentureBurn does not endorse or recommend the buying or selling of any digital assets and is not a licensed investment advisor. Please note that VentureBurn may participate in affiliate marketing programs. Editor's Choice 10 Best Decentralized Crypto Exchanges (DEXs) in 2026 12 Crypto Exchanges with the Lowest Fees Comparison 13 Best Crypto Card Options in 2026: Debit & Credit Ranked Cowboy Space Corporation Raises $275M in Funding Round 10 Easiest Crypto to Mine: Best Profitable Coins In May 2026 Table of Contents Related articles Fractile Raises $220M To Advance AI Inference Chip Development Outmarket AI Raises $17M To Scale Insurance Workflow Automation Mind Robotics Raises $400M To Expand AI Industrial Robotics Platform Exaforce Raises $125M Series B To Scale AI Native Security Operations Platform Embat Raises €30M To Scale AI Treasury Management Platform Latest crypto news Join the Binance EDGE Trading Competition Now To Share in $100K Rewards. Contest Guide Join the Binance Wallet On-Chain Trade & Win Season 3 Win Up To 15 BNB or 88 SOL How Ethereum Casinos Are Driving Payment Innovation Exponent Raises $40M To Build Financial Platform For Franchise Operators Crew Carbon Raises $25M To Scale Wastewater Decarbonisation Technology GovWell Secures $25M Series A From Insight Partners Novella Raises $21M to Scale AI Insurance Brokerage Cash App’s Strategy Shifts And Its Help In Company Growth GridCARE Raises $64M to Launch AI Energy Category Synthetic Raises $10M Seed Funding For AI Bookkeeping Platform VentureBurn is a global news and insights platform covering the latest trends and developments across the technology landscape – including cryptocurrency, artificial intelligence, venture capital, and startups. Our mission is to empower entrepreneurs, investors, and tech enthusiasts with high-quality journalism, practical guides, and expert analysis to navigate and thrive in the rapidly evolving innovation economy. Category About Subcribe to our newletter Top tech news & guides in crypto, AI, VC, and startups — weekly in your inbox.
Images (10): 


|
|||||
| Unitree unveils optionally manned transformer robot GD01 | https://interestingengineering.com/ai-r… | 10 | May 18, 2026 15:28 | active | |
Unitree unveils optionally manned transformer robot GD01Description: Unitree unveils a manned transformable mecha robot capable of switching between bipedal and quadruped modes. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. GD01 features stable bipedal walking, strong force to topple walls, and quick switch to quadruped mode for rough terrain movement. China’s robotics giant Unitree has unveiled the GD01, a mecha-style machine that can switch between two-legged and four-legged configurations. It resembles a real-life Autobot from the Transformers franchise and is built from high-strength alloy for civilian transport applications. According to the Hangzhou-based firm, it weighs 1102 pounds (500 kilograms) with a pilot on board and has a starting price of 3.9 million yuan (US$573,674). Recently, Unitree launched a low-cost upper-body humanoid robot starting at 26,900 yuan ($ 4290), featuring modular bases and up to 31 degrees of freedom. Unitree’s GD01 demonstration video shows the mecha carrying a pilot in a torso-mounted cockpit as it walks in a humanoid stance, strikes a stack of bricks, and then reconfigures its chassis into a four-legged configuration. The system is presented as a transformable civilian vehicle. The company states the vehicle weighs about 1102 pounds (500 kilograms) with a passenger on board. Founder Wang Xingxing is shown seated inside the cockpit during the demonstration, highlighting a sharp size contrast between operator and machine. In upright mode, the robot reaches roughly 1.6 times the height of an average adult, reports 36Kr. It demonstrates stable bipedal walking, high force output capable of toppling a brick wall, and a rigid structure that remains steady under impact. The system can fold its legs, adjust its center of gravity, and transition into a quadruped form within seconds, continuing movement without external assistance across uneven terrain. The one-minute video was shared on social media platforms, with the company releasing limited technical specifications. Unitree also issued a safety notice urging users not to attempt hazardous modifications or extreme tests, noting that humanoid robotics remains in an early experimental stage with functional limitations for personal users. The company shared no additional specifications publicly yet. The GD01 adds to the Unitree portfolio amid rapid growth in China’s humanoid robotics industry. In April, the company released an upper-body bipedal humanoid robot starting at 26,900 yuan, designed with modular deployment options including a fixed base and mobile chassis for use in research, light industry, and service applications. According to research firm Omdia, Chinese companies accounted for nearly 90 percent of global humanoid robot sales in 2025. Unitree reportedly shipped more than 5,500 humanoid robots in the previous year, while US companies such as Tesla, Figure AI, and Agility Robotics each shipped around 150 units during the same period, reports the South China Morning Post (SCMP). Chinese humanoid robots are also priced lower than many Western alternatives. Unitree’s entry-level humanoid R1 costs about US$6,000, while rival AgiBot offers a model priced around US$14,000. Tesla CEO Elon Musk has estimated that the future cost of the Optimus humanoid robot could fall between US$20,000 and US$30,000. Unitree sells its R1, G1 humanoids, and Go2 robot dog internationally via Alibaba’s AliExpress platform, targeting markets in North America, Europe, and Japan. Chinese humanoid robots have also begun appearing in airports and logistics operations, including trials by Japan Airlines using systems from Unitree and UBTech Robotics at Tokyo’s Haneda Airport, reports SCMP. In March, Unitree filed for an IPO on Shanghai’s STAR Market, planning to allocate about 85 percent of its 4.2 billion yuan ($61 million) fundraising target to research and development, including over 2 billion yuan ($29 million) for robotics model development. Jijo is an automotive and business journalist based in India. Armed with a BA in History (Honors) from St. Stephen's College, Delhi University, and a PG diploma in Journalism from the Indian Institute of Mass Communication, Delhi, he has worked for news agencies, national newspapers, and automotive magazines. In his spare time, he likes to go off-roading, engage in political discourse, travel, and teach languages. Premium Follow
Images (10): |
|||||
| Unitree GD01 mecha unveiled as company files for $7 billion … | https://thenextweb.com/news/unitree-gd0… | 9 | May 18, 2026 15:27 | active | |
Unitree GD01 mecha unveiled as company files for $7 billion IPO after outselling Tesla on humanoid robotsURL: https://thenextweb.com/news/unitree-gd01-mecha-humanoid-robot-ipo Description: Unitree Robotics unveiled a $650,000 transformable mecha and is filing for a $7 billion IPO. The Chinese company shipped more humanoid robots than Tesla in 2025. Content:
TL;DRUnitree Robotics unveiled the GD01, a 2.8-metre transformable mecha priced from $650,000, but the real story is the company behind it: Unitree shipped more humanoid robots than Tesla in 2025, holds 70% of the quadruped market, grew revenue 335% to $235 million, has been profitable since 2020, and is filing for a $7 billion IPO on the Shanghai Stock Exchange. Unitree Robotics unveiled the GD01, a 2.8-metre transformable mecha priced from $650,000, but the real story is the company behind it: Unitree shipped more humanoid robots than Tesla in 2025, holds 70% of the quadruped market, grew revenue 335% to $235 million, has been profitable since 2020, and is filing for a $7 billion IPO on the Shanghai Stock Exchange. Unitree Robotics has unveiled a 2.8-metre transformable mecha that a human pilot climbs inside and operates from an open cockpit in the torso. The GD01 walks on two legs, folds into a quadruped configuration in seconds, weighs roughly 500 kilograms with a passenger, and is priced from 3.9 million yuan, approximately 650,000 dollars. It can also operate unmanned. Unitree calls it the world’s first production-ready manned mecha. It is a civilian vehicle, the company says, built for transport across rough terrain, exploration, and rescue operations where a tall vantage point helps. The GD01 is a spectacle. It is also a brand statement from a company that has earned the right to make one. TNW City Coworking space - Where your best work happens A workspace designed for growth, collaboration, and endless networking opportunities in the heart of tech. Unitree was founded in 2016 by Wang Xingxing, who built his first quadruped robot as a master’s thesis project at Shanghai University and left a job at DJI to start the company in a 50-square-metre office in Hangzhou. A decade later, Unitree holds roughly 70 per cent of the global quadruped robot market, having shipped more than 23,700 units in 2024 across its Go, A, and B series. In 2025, it shipped more than 5,500 humanoid robots, more units than any other manufacturer including Tesla. Revenue reached 1.71 billion yuan, approximately 235 million dollars, in 2025, representing 335 per cent year-on-year growth. The company has been profitable every year since 2020. Humanoid robots overtook quadrupeds as the primary revenue driver in 2025, contributing roughly 52 per cent of total revenue in the first three quarters. Unitree filed for an initial public offering on the Shanghai Stock Exchange in March 2026, seeking to raise 4.2 billion yuan, approximately 610 million dollars, at a target valuation of seven billion dollars. The investor list reads like a directory of Chinese technology capital: Alibaba, Tencent, China Mobile, Geely Capital, Ant Group, Jinqiu Capital (ByteDance’s investment arm), and HongShan Capital, formerly Sequoia China. Every major Chinese technology conglomerate has money in the company that dominates the market for robots that walk. Unitree’s commercial significance has nothing to do with the GD01. It rests on a product line that spans the market from consumer to industrial at prices that undercut every Western competitor by an order of magnitude. The Go2 consumer quadruped starts at 1,600 dollars. The G1 humanoid, a research and light industrial platform, sells for 13,500 to 27,000 dollars. The H2, a full-size industrial-grade humanoid, is priced at 29,900 dollars. The B2-W, a wheeled quadruped variant, handles inspection, patrol, and fire rescue. Unitree Robotics unveiled the GD01, source: Unitree For context, Figure AI’s Figure 02 industrial humanoid is being piloted at BMW at costs that have not been publicly disclosed but are estimated to be multiples of Unitree’s pricing. Boston Dynamics has begun commercial production of its electric Atlas, with every 2026 unit already committed to Hyundai. Tesla’s Optimus remains in research and development with no productive factory deployments as of the first quarter of 2026. Unitree is the only company simultaneously shipping consumer, research, and industrial humanoid robots at scale. China’s humanoid robot boom faces a commercialisation reality check, with more than 150 companies chasing a market where only 23 per cent of buyers report satisfaction with the robots they have purchased. Unitree’s answer to the satisfaction problem is iteration speed and price. If the first robot disappoints, the replacement costs less than a competitor’s pilot programme. The company treats humanoid robots the way Chinese smartphone manufacturers treated handsets a decade ago: ship fast, price aggressively, iterate on customer feedback, and let volume drive down cost. The GD01 transforms between bipedal and quadrupedal modes by folding its legs and shifting its centre of gravity, a process that takes a few seconds. In bipedal mode, it walks upright at nearly three metres tall. In quadruped mode, it lowers its profile for stability on rough terrain. The machine uses LiDAR, depth cameras, an inertial measurement unit, and pressure sensors for stability and navigation. It runs on Unitree’s self-developed high-torque motors. Demonstration videos show it walking through urban environments, smashing through brick walls, and carrying a pilot across uneven ground. Unitree has been explicit about safety. The company has asked users to refrain from dangerous modifications and noted that humanoid robotics remains in an early experimental stage with functional limitations. The 650,000 dollar price is described as a preliminary reference; the final production version may be adjusted depending on performance optimisation. The machine is not a toy. It is also, unmistakably, not yet a product with a clear commercial market beyond high-net-worth buyers and demonstration events. What it is, precisely, is a capability demonstration. The GD01 proves that Unitree can build large-scale bipedal systems with transformation mechanics, high-torque actuation, and manned operation. Those capabilities feed back into the company’s commercial product line. The motors, sensors, control algorithms, and structural engineering developed for a 500-kilogram mecha are directly applicable to the next generation of industrial humanoids that will carry loads, navigate construction sites, and operate in environments too dangerous for human workers. Tesla has explored using its Shanghai Gigafactory for Optimus humanoid robot mass production, a decision that would place the world’s most valuable car company’s robotics programme inside China’s manufacturing ecosystem. The irony is instructive. Tesla, the American company, would build its humanoid robot in China because Chinese manufacturing infrastructure, supply chains, and cost structures are the most efficient in the world for producing complex electromechanical systems at scale. Unitree already has that infrastructure. The components that go into a humanoid robot, precision motors, sensors, thermal management systems, lightweight structural materials, and battery cells, are the same components that Chinese factories produce at scale for smartphones, electric vehicles, and drones. Morgan Stanley forecasts China’s humanoid robot sales will reach 28,000 units in 2026, a 133 per cent year-on-year increase, with material costs falling 16 per cent as supply chain efficiencies from consumer electronics manufacturing carry over into robotics production. Chinese electric vehicles are flooding American social media despite 100 per cent tariffs, driven by consumer demand that trade barriers cannot fully suppress. The pattern for robotics is likely to follow the same trajectory. Unitree’s quadrupeds already sell globally. Its humanoids are priced at a fraction of Western alternatives. The GD01, whatever its practical utility, ensures that the Unitree brand is visible in every robotics conversation on the planet. Unitree’s Shanghai Stock Exchange filing is the first major humanoid robotics IPO. Boston Dynamics, owned by Hyundai, has been valued between 21 and 28 billion dollars by Korean securities firms, with bullish IPO projections reaching 100 billion dollars. Figure AI raised one billion dollars at a 39 billion dollar valuation in September 2025. But neither has gone public. Unitree, the company from the 50-square-metre Hangzhou office, would be the first pure-play robotics company to list. Cerebras, the AI chipmaker, is targeting a 40 billion dollar IPO valuation in what would be the first major AI hardware listing of 2026. Unitree’s seven billion dollar target is more modest, but the company has something Cerebras does not: profitability. Unitree has been profitable every year since 2020. In a market where AI and robotics companies routinely burn capital at extraordinary rates, a profitable robotics manufacturer filing for a public listing is an anomaly. UBTech, one of Unitree’s Chinese competitors, has offered 18 million dollars to hire a chief AI scientist, a figure that illustrates the talent arms race in Chinese robotics. Unitree’s advantage is not a single hire. It is a decade of iteration from Wang Xingxing’s thesis project to a product line that covers the market from 1,600-dollar consumer quadrupeds to 650,000-dollar pilotable mechs, all manufactured in China at costs that Western competitors cannot match. The GD01 will not sell in volume. A 650,000 dollar mecha does not have a mass market. What it has is attention. Every technology publication in the world covered the announcement. The videos went viral. The brand registered. And behind the spectacle, Unitree’s actual business, the one generating 335 per cent revenue growth and filing for a seven billion dollar IPO, continued shipping robots that walk, run, and work at prices that make every competitor recalculate their cost structure. Wang Xingxing built his first walking robot in a university lab in 2013. Thirteen years later, the company he founded from that project sells more humanoid robots than Tesla, holds 70 per cent of the quadruped market, counts every major Chinese technology company as an investor, and just unveiled a vehicle that transforms from a walking machine into a crawling one with a human inside. The GD01 is not the product. The product is the company that could build it. Alina Maria Stan builds connections that people actually feel. As co-founder and COO of Tekpon, she turns product intuition into real moment (show all) Alina Maria Stan builds connections that people actually feel. As co-founder and COO of Tekpon, she turns product intuition into real moments of discovery, shaping how teams find and adopt SaaS every day. Since 2020, she has led Tekpon’s brand voice, media strategy, and growth plays with a clear focus on human outcomes behind every metric. Before Tekpon, Alina followed curiosity across industries and countries. She was CEO of King Casino Bonus and led affiliate and brand strategy at Extremoo Media and Fable Media in Denmark, where she learned how to build partnerships that last. Early on, she sharpened her CRM and pricing instincts at K.H. ApS, always asking why customers choose what they choose. Her approach is rooted in more than a decade of international experience and two master’s degrees, one in Sustainable Consumption from the Technical University of Munich and one in Consumer Affairs Management from Aarhus University. Get the most important tech news in your inbox each week. The heart of tech A Tekpon Company Copyright © 2006—2026, Cogneve, INC. Made with <3 in Amsterdam.
Images (9): 


|
|||||
| Unitree unveils $4,290 humanoid robot with upper-body-only design | https://interestingengineering.com/ai-r… | 10 | May 18, 2026 15:27 | active | |
Unitree unveils $4,290 humanoid robot with upper-body-only designURL: https://interestingengineering.com/ai-robotics/china-unitree-humanoid-robot Description: Unitree launches a low-cost upper-body humanoid robot with modular design and precision control for research and industry. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Combines binocular vision, a 4-array mic, and voice interaction to enable real-time visual perception and speech-based control in one system. Chinese robotics firm Unitree has introduced a low-cost bipedal humanoid robot with an upper-body-only design. According to the Hangzhou-based firm, with prices starting at 26,900 yuan ($ 4290), it significantly lowers entry barriers in the sector. The robot replaces the traditional full-body structure with modular deployment options, including a fixed base or mobile chassis. It offers flexible configurations with 5 or 7 degrees of freedom per arm, for a total of up to 31 degrees of freedom. Last week, Unitree showcased its G1 humanoid gliding on skates, performing spins, turns, and flips using coordinated wheel-leg balance control. The bipedal robot replaces a full-body design with modular deployment options, offering either a fixed base or mobile chassis for varied applications. Each arm is available in 5-DOF or 7-DOF configurations, with total system DOF ranging from 15 to 31. The waist rotates ±150°, while the head supports ±115° yaw and ±36° pitch. Its gripper achieves ±0.1 mm repeatability and supports interchangeable dexterous hands, with each arm handling payloads up to 4.4 pounds (2 kilograms), reports EU.36KR. The base system integrates binocular vision, a 4-array microphone, and voice interaction, enabling combined visual perception and speech-based control. It is powered by dual 8-core high-performance CPUs, while the head vision module provides up to 10 TOPS of AI compute, supporting real-time perception tasks. The standard model includes 5-degree-of-freedom robotic arms, with an optional 7-DOF upgrade for enhanced manipulation. Mechanically, the platform is modular, offered in both fixed-base and wheeled configurations, allowing deployment across lab, industrial, and service environments. The system supports interchangeable components and exposes low-level interfaces for secondary development, enabling researchers to customize control, perception, and task execution. Weighing between 24 pounds (11 kilograms) and 70 pounds (32 kilograms), the robot supports both external and vehicle-mounted power supplies, balancing endurance with deployment flexibility. Its architecture is designed for rapid iteration, making it suitable for applications ranging from assembly and training to mobile service tasks such as guided interaction and warehouse assistance. Unitree is applying its proven playbook from quadruped robots to dual-arm humanoid systems. Experts point out that its earlier Go series succeeded by delivering capable legged robots at prices far below competing platforms, attracting a broad developer base and fostering an ecosystem around its SDK and control stack. A similar momentum could emerge in manipulation robotics if this approach translates effectively, reports Startup Fortune (SF). Last year, Unitree also unveiled the R1, a humanoid robot with 26 joints, at just 39,999 yuan (about US $5,900). However, the competitive landscape is more crowded. Companies like Boston Dynamics bring strong engineering depth, established enterprise ties, and brand trust, factors that matter in industrial deployments. Unitree’s lower-cost strategy may face limits in markets where reliability, support, and reputation outweigh price advantages. Experts say affordability is key for researchers and developers. Access to capable hardware lowers barriers, speeds iteration, and enables real-world testing beyond simulations, accelerating progress in embodied AI, especially in manipulation and applied robotics. The real signal will emerge from how developers use these systems. Open-source projects, academic work, and early-stage startups building on accessible platforms will shape the next phase of innovation more than high-end demonstrations, reports SF. Jijo is an automotive and business journalist based in India. Armed with a BA in History (Honors) from St. Stephen's College, Delhi University, and a PG diploma in Journalism from the Indian Institute of Mass Communication, Delhi, he has worked for news agencies, national newspapers, and automotive magazines. In his spare time, he likes to go off-roading, engage in political discourse, travel, and teach languages. Premium Follow
Images (10): |
|||||
| Unitree Robotics G1 robot skates on ice and Rollerblades with … | https://www.foxnews.com/tech/unitree-g1… | 10 | May 18, 2026 15:27 | active | |
Unitree Robotics G1 robot skates on ice and Rollerblades with ease | Fox NewsURL: https://www.foxnews.com/tech/unitree-g1-humanoid-robot-ice-skates-rollerblades Description: Unitree Robotics' G1 humanoid robot glides on ice skates and Rollerblades, performing spins and flips while maintaining balance through wheel and leg control. Content:
This material may not be published, broadcast, rewritten, or redistributed. ©2026 FOX News Network, LLC. All rights reserved. Quotes displayed in real-time or delayed by at least 15 minutes. Market data provided by Factset. Powered and implemented by FactSet Digital Solutions. Legal Statement. Mutual Fund and ETF data provided by LSEG. Fox News Flash top headlines are here. Check out what's clicking on FoxNews.com. We've seen robots walk, run, climb stairs and even recently finish a half-marathon. What we haven't seen until now is a robot gliding across the ice like an Olympic skater or spinning on one leg on Rollerblades without losing balance. That is exactly what Unitree Robotics just showed with its G1 humanoid robot. In newly released footage, the robot moves on Rollerblades and ice skates while keeping its posture steady through coordinated wheel and leg control. It's pretty amazing to watch. Sign up for my FREE CyberGuy Report ELON MUSK TEASES A FUTURE RUN BY ROBOTS Unitree’s G1 humanoid robot glides on wheels, Rollerblades and ice skates, showing off sharp balance, spins and even a flip. (Unitree Robotics) When you actually watch the video, a few moments really stand out. It starts with the robot leaning into the motion, almost stepping as it propels itself forward on two wheels, shifting its weight from side to side as if one wheel is leading the next. Its arms move up and down to stay balanced, giving it a rhythm that feels closer to walking than rolling, like it's constantly adjusting in real time. Then it pulls off a series of spins and an impressive flip, landing clean on two wheels and continuing without missing a beat. No hesitation. Next, it switches to Rollerblades and moves with the same level of control. It glides, does some fancy footwork, changes direction and even lifts one leg while spinning and staying balanced like it's second nature. That alone would be impressive. But the real wow moment comes at the end. On ice, the robot starts doing smooth twirls, almost like it’s figure skating, while holding its posture without slipping. That’s when you start to see how far these humanoid robots have come. Most humanoid robots face the same problem. Staying upright while doing anything dynamic pushes the limits of control systems. The G1 changes that equation by blending two approaches. It combines wheeled efficiency with legged adaptability. That means it can roll when speed matters and step when terrain gets tricky. In the demo, the robot transitions smoothly between these modes. It executes continuous motion instead of stopping to rebalance. You see 360-degree turns, controlled spins and even front flips, all without a visible pause. That level of fluidity points to improvements in real-time control, balance correction and motion planning. These are areas that have held humanoid robots back for years, until now. ROBOTS LEARN 1,000 TASKS IN ONE DAY FROM A SINGLE DEMO The Unitree G1 performs spins, turns and a clean flip while riding on wheels and Rollerblades. The demo offers a striking look at how far humanoid robots have come. (Unitree Robotics) The hardware behind the G1 explains why it can pull this off. Unitree designed the system as a full-stack platform for AI training and deployment. That means the robot collects its own data, learns from simulation and applies those lessons in the real world. The robot comes in two main versions. The Standard model focuses on stationary tasks. The Flagship version adds a wheeled base that can reach about 3.3 feet per second. Both variations share a humanoid structure with up to 19 degrees of freedom. Each arm has seven degrees of freedom and can handle about 6.6 pounds. A flexible waist allows wide motion ranges, which helps with balance during dynamic movement. Vision comes from a binocular camera in the head, along with wrist cameras for close-up work. The system can use different grippers, including dexterous hands for more precise tasks. At the core, the Flagship model runs on an NVIDIA Jetson Orin NX module with up to 100 TOPS of compute. That level of onboard processing supports real-time decision-making during complex movement. Battery life can stretch up to six hours, depending on how hard the robot is working. For years, robotics has leaned in two directions. Wheeled machines move efficiently but struggle with obstacles. Legged robots handle complex environments but use more energy and move more slowly. Unitree's approach tries to merge both. By adding wheels to a humanoid frame, the G1 can move quickly across flat surfaces and still adapt when conditions change. That hybrid design also reduces wear on joints and improves energy efficiency over long distances. It also opens the door to new types of tasks. A robot like this could move through a warehouse, switch to precise manipulation at a workstation and then roll to the next job without slowing down. Take my quiz: How safe is your online security? Think your devices and data are truly protected? Take this quick quiz to see where your digital habits stand. From passwords to Wi-Fi settings, you’ll get a personalized breakdown of what you’re doing right and what needs improvement. Take my Quiz here: CyberGuy.com. NEW MOBILE ROBOT HELPS SENIORS WALK SAFELY AND PREVENT FALLS The Unitree R1 humanoid robot runs on a flat surface. The model is noted for its affordability at $5,900. (Unitree Robotics) The skating is what grabs you first. It is fun to watch and hard to ignore. What stands out after a few seconds is how steady the robot stays the whole time. It keeps moving, keeps adjusting and never looks close to losing control. That is a big change from the stop-and-go motion we are used to seeing. If this keeps improving, and I know it will, you are going to see robots that can move through real environments without slowing down or needing constant input. CLICK HERE TO DOWNLOAD THE FOX NEWS APP So here is the question. If robots can move this fluidly today, how long before they start working alongside you without missing a step and are you OK with that? Let us know by writing to us at CyberGuy.com. Sign up for my FREE CyberGuy Report Copyright 2026 CyberGuy.com. All rights reserved. Kurt "CyberGuy" Knutsson is an award-winning tech journalist who has a deep love of technology, gear and gadgets that make life better with his contributions for Fox News & FOX Business beginning mornings on "FOX & Friends." Got a tech question? Get Kurt’s free CyberGuy Newsletter, share your voice, a story idea or comment at CyberGuy.com. Get a daily look at what’s developing in science and technology throughout the world. Subscribed You've successfully subscribed to this newsletter! This material may not be published, broadcast, rewritten, or redistributed. ©2026 FOX News Network, LLC. All rights reserved. Quotes displayed in real-time or delayed by at least 15 minutes. Market data provided by Factset. Powered and implemented by FactSet Digital Solutions. Legal Statement. Mutual Fund and ETF data provided by LSEG.
Images (10): 




|
|||||
| Sergey Levine: General robotic foundation models may outperform narrow solutions, … | https://cryptobriefing.com/sergey-levin… | 10 | May 14, 2026 16:00 | active | |
Sergey Levine: General robotic foundation models may outperform narrow solutions, the future of medicine involves autonomous robots, and the importance of understanding physical interactions | Invest Like the BestDescription: General robotic models could revolutionize robotics by enhancing adaptability and efficiency across diverse applications. Content:
Searching... General robotic models could revolutionize robotics by enhancing adaptability and efficiency across diverse applications. Share Sergey Levine is an Associate Professor in the Department of Electrical Engineering and Computer Sciences at UC Berkeley and co-founder of Physical Intelligence. He earned his PhD in Computer Science from Stanford University in 2014 and joined UC Berkeley faculty in 2016. His research pioneered deep reinforcement learning algorithms for robotics, enabling end-to-end training of neural network policies that combine perception and control. General robotic models could revolutionize robotics by enhancing adaptability and efficiency across diverse applications. Share Sergey Levine is an Associate Professor in the Department of Electrical Engineering and Computer Sciences at UC Berkeley and co-founder of Physical Intelligence. He earned his PhD in Computer Science from Stanford University in 2014 and joined UC Berkeley faculty in 2016. His research pioneered deep reinforcement learning algorithms for robotics, enabling end-to-end training of neural network policies that combine perception and control. All content is for informational purposes only and does not constitute investment advice. CryptoBriefing does not provide recommendations to buy, sell, or hold any asset or contract. See our Disclaimer & Risk Disclosure. © Decentral Media and Crypto Briefing® 2026. Sign in to your account Create your account Already have an account? Sign In Forgot your password? Sign In Daily news, analysis & market insights delivered free.
Images (10): 
|
|||||
| Researchers Build Light-Powered AI Chips That Let Robots Learn Autonomously | https://www.techjuice.pk/researchers-bu… | 10 | May 14, 2026 16:00 | active | |
Researchers Build Light-Powered AI Chips That Let Robots Learn AutonomouslyDescription: Researchers develop light-powered photonic chips that enable faster and more energy efficient AI learning. Content:
Researchers at Xidian University in China have demonstrated a light-powered computing chip capable of running reinforcement learning tasks entirely within the optical domain, a breakthrough that eliminates a fundamental limitation that has held back light-based AI hardware for over a decade. The findings, published in the journal Optica, point toward a future where autonomous vehicles and robots learn directly from their environments using chips that are dramatically faster and more energy-efficient than today’s electronic processors. Photonic spiking neural systems have long been considered a promising path toward AI hardware that outpaces conventional electronics. These systems mimic how biological neurons communicate by using rapid pulses of light rather than electrical signals, which travel faster and consume far less energy. The problem has always been in the learning step. “Photonic spiking neural systems use brief optical pulses, or spikes, to emulate neural signaling, but they can typically only process the linear parts of computation using light,” said research team leader Shuiying Xiang from Xidian University. Every previous attempt to build such systems ran into the same wall: the nonlinear operations that actually make learning and decision-making possible required converting signals back into electrical form for processing. “Previously, the nonlinear steps that make learning and decision making possible required the signal to be converted back into electronic signals. This adds delay and undercuts the speed and energy advantages of photonics,” Xiang explained. The new design removes that conversion step entirely, keeping all computation, both linear and nonlinear, inside the optical domain. The researchers designed a programmable photonic neuromorphic platform built from two chips working in tandem. The first is a 16-channel photonic neuromorphic processor containing 272 trainable parameters, capable of handling multiple optical signals simultaneously. The second features a distributed feedback laser array with a saturable absorber component that enables low-threshold nonlinear optical spiking, which is the key element that allows learning to happen without electronics. To test the system’s practical capability, the team used reinforcement learning, the same AI training approach that underlies many modern robotic and autonomous systems, where a machine learns through repeated trial and error rather than labelled training data. “We used this system to demonstrate reinforcement learning, supported by a hardware and software collaborative framework that trains and runs the neural network. The system was able to learn quickly through trial and error, showing potential as a fast, low-latency solution that could be used for applications such as autonomous driving and embodied intelligence,” Xiang said. The results were tested against two standard control benchmarks. One required balancing a pole on a moving cart, the classic CartPole task used widely to evaluate reinforcement learning systems. The other required stabilising an inverted pendulum. Hardware decisions closely matched the software model in both tests, with accuracy dropping only 1.5% on CartPole and 2% on the pendulum challenge. On raw computing metrics, the photonic linear processing reached 1.39 tera operations per second per watt. Nonlinear computation achieved nearly 988 giga operations per second per watt. On-chip computing latency measured just 320 picoseconds, a speed advantage that conventional electronic processors cannot approach. The current prototype operates with 16 optical channels. The team has announced plans to scale the architecture to a 128-channel photonic spiking neural chip, which would support more complex reinforcement learning tasks closer to real-world deployment conditions. The researchers also aim to build compact hybrid photonic systems suitable for edge computing, where low power consumption and fast local processing are both critical requirements. If the architecture scales successfully, photonic AI hardware could offer a credible alternative to electronic GPU clusters for the class of applications, including robotics, autonomous vehicles, and real-time environmental adaptation, where latency and energy consumption are the binding constraints on what machines can do. You can read the research here. Abdul Wasay explores emerging trends across AI, cybersecurity, startups and social media platforms in a way anyone can easily follow. Google and SpaceX negotiate to launch orbital data centers revolutionizing AI computing infrastructure. Google’s Project Suncatcher aims for 2027 prototype satellites with TPUs. SpaceX pitches. Grok app downloads fell nearly 60% to 8.3 million in April from January peak of 20 million according to AppMagic data reported by Wall Street. OpenAI launched Daybreak cybersecurity initiative on May 11 using GPT-5.5 models and Codex Security to find vulnerabilities before exploitation. The platform competes with Anthropic’s Claude. The provincial government of Punjab has approved a government GPU cloud project, establishing the first local artificial intelligence platform for official and academic use. As. Premier Pakistan technology news website with special focus on startups, entrepreneurship and consumer products. © 2026 TechJuice.PK – All rights reserved.
Images (10): 




|
|||||
| Disney trains robots to fall, roll, and land safely without … | https://interestingengineering.com/ai-r… | 10 | May 14, 2026 16:00 | active | |
Disney trains robots to fall, roll, and land safely without damageURL: https://interestingengineering.com/ai-robotics/disney-builds-smart-robot-system Description: Disney researchers have developed a new system that lets robots turn uncontrolled falls into safe and controlled landings. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. The team used reinforcement learning with thousands of simulated tumbles to teach robots how to protect sensitive parts during a fall. A new research effort by Disney experts and university engineers shows how robots can now manage controlled landings when they fall. The project answers a key question in robotics about what happens when bipedal machines lose balance and hit the ground. The team studied why robots fall, what damage happens, where it occurs most, when the worst impacts take place, and who can prevent it. Their results show a system that lets a robot drop from a shove or slide and then choose a safe landing pose that protects vital parts. Robots that walk on two legs often move well on uneven surfaces or around obstacles. Yet gravity still wins and brings them down without warning. Traditional robots hit the ground with stiff joints or uncontrolled flailing that breaks sensors and cracks shells. Repair bills rise fast in labs and warehouses. Disney researchers decided to stop fighting gravity. Their goal was to let robots roll into a safe position instead of resisting the fall. The team set out to build a method that absorbs the impact and saves fragile parts such as heads and battery packs. They wanted a robot that could fall, shift its limbs during the drop, and land in a stable pose. The approach focused on the prevention of damage rather than strict balance control. The project used reinforcement learning to teach the robot safe tumbling skills. Thousands of virtual robots fell inside a simulator. Each digital fall generated data about what worked and what did not. The robot studied those results and learned a sequence of moves that reduced damage. The system awarded points when the robot reduced the impact force or protected sensitive areas. It removed points when motions became wild or off target. The researchers built a scoring system that tracked every twist of a joint from the moment the fall started. As the robot dropped, it tried to keep the landing smooth. When it neared the ground, it shifted into a final pose designed to shield important parts. The simulator included many types of falls. These ranged from sideways slips at 2 meters per second [about 6.5 feet per second] to fast forward tumbles with spinning hips. Velocities were randomized in every episode, so the robot never learned a single fixed path. To expand the library of outcomes, the team created 24,000 stable poses and dropped the robot models from waist height. The simulator relied on physics to determine which ones worked. Ten of the final poses came from artists who built creative positions such as crouches or wide, dramatic flops. These poses had to stay within the limits of real joints and motors. The team also added random noise to the simulations so the robot could handle small, unpredictable nudges. Training ran for two days on strong graphics cards. 4,000 virtual robots fell at the same time. A small neural network processed joint angles, body orientation, and motion data. It sent commands fifty times per second. The method used proximal policy optimisation to adjust the robot’s behavior step by step without sudden leaps. The simulator reduced contact pressure and set different sensitivity levels for each body part. The legs stayed soft while the head needed more protection. After the training, the robot could shift from a loose sprawl to a tight protective curl in an instant. The policy was then placed in a real metal robot. It weighed sixteen kilograms [about 35 pounds] and stood on two spring legs with mechanical arms. A motion capture system tracked its motion and fed updates back to the controller. The tested system showed that robots do not need to fear sudden collapse. Instead of turning into piles of broken parts, they can fall with control. The research was published in the journal arXiv. A versatile writer, Sujita has worked with Mashable Middle East and News Daily 24. When she isn't writing, you can find her glued to the latest web series and movies. Premium Follow
Images (10): |
|||||
| Disney Research Demonstrates “ReActor,” a New System That Could Help … | https://wdwnt.com/2026/05/disney-resear… | 10 | May 14, 2026 16:00 | active | |
Disney Research Demonstrates “ReActor,” a New System That Could Help Robots Move More Like Humans - WDW News TodayDescription: The motion-learning technology demonstrated in this project could mark a significant improvement for robotic movement across any application. Content:
Austin Haughton Published: May 10, 2026 Last Updated On: May 11, 2026 Disney Research has shared a new video demonstrating “ReActor,” a research project focused on transferring human motion to robots with very different body shapes and movement capabilities. The motion-learning technology demonstrated in this project could mark a significant improvement for robotic movement across any application. A portion of the abstract for the full research paper reads as follows: Retargeting human kinematic reference motion onto a robot’s morphology remains a formidable challenge. Existing methods often produce physical inconsistencies, such as foot sliding, self-collisions, or dynamically infeasible motions, which hinder downstream imitation learning. We propose a bilevel optimization framework that jointly adapts reference motions to a robot’s morphology while training a tracking policy using reinforcement learning … We validate our method in simulation and on hardware, demonstrating challenging motions for morphologies that differ significantly from a human, including retargeting onto a quadruped. In simpler terms: the existing methods used to teach robots humanlike movement tend to fall short when aiming for smooth, 1:1 human motion. A proposed system from Disney Research offers a new layered learning method, where the program takes the original source motion and analyzes how to best match the movement if the source body more closely matched the target robot’s design. The project, formally titled “ReActor: Reinforcement Learning for Physics-Aware Motion Retargeting,” was developed by researchers David Müller, Agon Serifi, Sammy Christen, Ruben Grandia, Espen Knoop, and Moritz Bächer, a team from Disney Research in Switzerland. The video from the team offers a visual demo of human motion being adapted to multiple robotic forms, including two humanoid robots and a quadruped robot, using multiple targeting methods compared against Disney’s ReActor method. The overall goal is to preserve the nuanced qualities of a human performance while making the resulting motion physically plausible for machines with different sizes, proportions, degrees of freedom, and joint limitations. Existing methods that work toward this goal have historically encountered issues overcoming technical errors in translating motion from human sources to robots or simulated models. These can include foot sliding, self-collisions, ground penetration, floating feet, or movements that are not physically achievable for the target robot. Disney’s ReActor addresses those issues by combining reinforcement learning with physics simulation, allowing the system to adapt the motion while also training a control policy to track it. The system uses what the researchers describe as a “bilevel optimization” framework. The method adjusts the reference motion at one level while simultaneously training the robot to follow that motion at another level. Rather than requiring extensive manual tuning, the system requires fewer body-part links between the source and target, such as matching relevant human body segments to comparable parts of the robot. As demonstrated in the video and according to the full paper, the method performed better than baseline approaches in several areas, including its success in avoiding all of the technical errors described earlier. The researchers also note that the system was validated both in simulation and on physical hardware, as shown with the live robot demo toward the end of the video. Check out the full demonstration from Disney Research on YouTube: While the project itself is dense and highly technical, the broader implications are easy to understand for Disney fans: the work could eventually support more lifelike robotic characters, interactive entertainment figures, or performance-driven animatronics, which have traditionally required more arduous fine-tuning for believable humanlike movement. The work on ReActor is still brand new, so there are no official comments from the company regarding its potential use in the future. Regardless, the project continues the company’s long-running interest in robotics, animation, and character performance technology. You can check out the full paper from Disney Research posted on arxiv.org. Do you have any experience in the fields of robotics or animation? What are your thoughts on this work coming out of Disney Research? Join the discussion with us on social media. For the latest Disney Parks news and info, follow WDW News Today on Twitter, Facebook, and Instagram. Previous Next © 2026 WDW News today
Images (10): 


|
|||||
| Efficient robot navigation inspired by honeybee learning flights | Nature | https://www.nature.com/articles/s41586-… | 10 | May 14, 2026 08:00 | active | |
Efficient robot navigation inspired by honeybee learning flights | NatureDescription: Navigation is a crucial capability for both animals and robots. Although tiny flying insects can robustly navigate over long distances1, state-of-the-art robot navigation methods are computationally expensive and therefore restricted to large robots2,3. Here we propose ‘Bee-Nav’, a highly efficient navigation strategy inspired by the visual learning flights of honeybees4–6. In equivalent robotic learning flights, a tiny neural network is trained to map omnidirectional images to a home vector based on path integration. After learning, the robot can fly far away from home, come straight back using path integration and cancel integration drift using the visual homing network. Simulations showed that, for realistic path integration accuracies, the neural network requires training on only approximately 0.25–10.00% of the total flight area. In real-world indoor and outdoor experiments, a small drone successfully returned to within 0.5 m of home for 100% of 30–110-m flights and 70% of 200–600-m flights in windy conditions, using 3.4-kB and 42-kB neural networks, respectively. The proposed navigation strategy will be vital for resource-constrained robots that perform tasks while travelling from and to a home location. Furthermore, it provides new perspectives on the neuroethology of insect navigation, from how visual learning shapes homing trajectories to the nature of cognitive maps. A highly efficient navigation strategy taking inspiration from the visual learning flights of honeybees is described, which enables drones to quickly return from longer flights by means of path integration and uses a neural network as a view memory to reach the home location. Content:
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript. Advertisement Nature (2026) Cite this article Navigation is a crucial capability for both animals and robots. Although tiny flying insects can robustly navigate over long distances1, state-of-the-art robot navigation methods are computationally expensive and therefore restricted to large robots2,3. Here we propose ‘Bee-Nav’, a highly efficient navigation strategy inspired by the visual learning flights of honeybees4,5,6. In equivalent robotic learning flights, a tiny neural network is trained to map omnidirectional images to a home vector based on path integration. After learning, the robot can fly far away from home, come straight back using path integration and cancel integration drift using the visual homing network. Simulations showed that, for realistic path integration accuracies, the neural network requires training on only approximately 0.25–10.00% of the total flight area. In real-world indoor and outdoor experiments, a small drone successfully returned to within 0.5 m of home for 100% of 30–110-m flights and 70% of 200–600-m flights in windy conditions, using 3.4-kB and 42-kB neural networks, respectively. The proposed navigation strategy will be vital for resource-constrained robots that perform tasks while travelling from and to a home location. Furthermore, it provides new perspectives on the neuroethology of insect navigation, from how visual learning shapes homing trajectories to the nature of cognitive maps. Small robots are at present deprived of the autonomous navigation capabilities necessary for real-world applications. Resource-restricted robots, such as lightweight flying drones7,8, can simply not carry or power the required computational systems for high-precision, map-based autonomous navigation2,3. Despite efforts towards improved computational efficiency, navigation based on detailed metric maps still requires a high-end laptop9 or a GPU-enabled embedded computer10. Efficiency can be improved by sacrificing map accuracy, storing it as a topological graph with nodes as places and edges as paths11,12. However, the robot still needs to recognize where it is and adjust the map accordingly, leading to increased computational requirements for larger trajectories11,13. This limits the navigation range of the most efficient map-based robot navigation methods. The state of the art is a tiny flying robot that uses 500 kB of memory on a low-power AI chip for navigating in a 4 × 5-m area14. Nature shows that extremely resource-efficient, long-range navigation is possible. Small insects such as honeybees robustly navigate up to several kilometres from their hive1. Their impressive navigation capabilities rely on two components15. The first is path integration16, which allows insects to estimate their position with respect to a starting point by integrating the directions and distances travelled. Because path integration is subject to increasing drift, insects also rely on a second component called view memory, which is the act of recalling visual landmarks and their relation to places of interest17. Path integration is well understood by now, even to the neuronal level18. By contrast, the precise working of view memory and its interplay with path integration is less clear. Lured by the navigational feats of insects, roboticists have proposed various insect-inspired navigation strategies. The predominant strategy is route-following, which typically relies on view memory to retrace the outbound trajectory during the return journey19,20,21,22,23,24. Route-following is a suitable strategy for navigating in highly cluttered environments, but in open areas, it can make the return journey unnecessarily long. Indeed, insects such as honeybees and desert ants tend to return home with a new straight path, even after long tortuous outbound journeys25,26 (Fig. 1a). During the return journey, insects rely initially on path integration and then increasingly on view memory when nearing their home26,27,28. a, Before foraging, honeybees first perform ‘learning’ flights (dark-grey line) close to home (star). Subsequently, they can fly out far away from home (teal line) and come back in an almost straight line (orange and red lines). Scale bar, 100 m. b, In Bee-Nav, the robot also first performs a learning flight, capturing omnidirectional images while using path integration for maintaining a vector (orange arrows) pointing to the home location. A neural network is trained to map the images to the home vectors. The trained network encodes an implicit view memory within the learned homing area (LHA) enclosing the learning flight trajectory (dashed circle). c, After learning, the robot can execute a long outbound flight to perform a task of interest (teal line), while maintaining a home vector based on path integration. It can then perform a straight inbound flight (orange line) using path integration until it supposedly arrives home. If the robot is inside the LHA, it can cancel the accumulated path integration drift by performing visual homing with its neural network (red line). It does this by making subsequent ‘steps’ along the homing vectors of the network. d, The robot in this study performs path integration based on velocity from optical flow and laser-based height measurements and a heading based on gyro integration. e, The view memory of the robot consists of a small feedforward convolutional neural network that maps an unwrapped omnidirectional image to a home vector. The centre of the view corresponds to the heading of the robot (solid black line) and the home direction is predicted by the neural network (vertical red line). Because the learning targets are imperfect path-integration-based home vectors, the neural network estimates are typically close but not identical to the home direction (vertical dashed black line). The idea of combining path integration and view memory in this manner formed the basis for the seminal work on ‘Sahabot 2’, a mobile ground robot that navigated in the desert28. However, separate experiments were performed for path integration and visual homing28, and subsequent studies did not explore their combined use. For path integration, it has been shown that accuracy benefits from combining several sensory cues with a motion model, including proprioception, optical flow, airflow sensors and polarization sensors29,30. The accuracy reached with bioinspired mechanisms can be impressive: for example, 1.5 m drift per 100 m for a flying robot31. In terms of view memory, there has also been substantial progress32, in which vision algorithms moved from landmark recognition28,33, through the matching of snapshots19,22,34, to neural networks for interpreting natural scenes35,36,37,38. Neural networks hold the potential to compress the view memory for a large visual homing area in a small parameter space. In a recent robotics study, a small 9-kB neural network enabled visual homing for distances up to 18 m in an outdoor environment39. The neural network transformed images directly to right or left steering commands. Learning was performed online with a biologically plausible neural network structure and learning mechanism, inspired by the insect mushroom body32. The learning targets consisted of the angles from the robot to the home as obtained with the Global Positioning System (GPS)39. For independence of external infrastructure, the targets could be obtained from path integration. Despite these advances, a critical gap remains: how to integrate the complementary mechanisms of path integration and view memory into a unified strategy for efficient, long-range navigation. To address this gap, we introduce a robot navigation strategy inspired by honeybee learning flights. Honeybees perform one to several such short flights before they depart on longer exploration or foraging trips4,5,6 (Fig. 1a). After learning flights, honeybees can immediately forage far away, while flying back in an almost straight line. On the basis of our preliminary simulation study40, we have developed a navigation strategy, named Bee-Nav, which is both highly efficient and suitable for long-range robot navigation. In the strategy, a robot first performs a learning flight (Fig. 1b), during which it trains a small on-board neural network to map its visual inputs directly to a home vector. This vector represents the direction and distance home from the point of view of the robot (Fig. 1d,e). The learning is self-supervised, as the target vector is determined with path integration. Self-supervised learning is a form of associative learning that is quick and requires only a few sample images and target vectors. However, because path integration drifts over time, the target vectors increasingly deviate from the true home vectors. We study the effects of this deviation on the resulting visual homing behaviour. The trained neural network represents a view memory, allowing the robot to visually estimate the home location within an area circumscribing the learning flight trajectories. We refer to this area as the learned homing area (LHA) and approximate it with a home-centred circle. After learning, the robot can fly far away from home and come back along a straight trajectory based on path integration (Fig. 1c, orange line). As long as the robot ends up in the LHA, it can cancel any accrued path integration drift with its onboard visual homing neural network (Fig. 1c, red line). The efficiency of Bee-Nav depends on the LHA being small compared with the total flight area. In simulation, we investigated how large the LHA needs to be for different amounts of path integration noise. The simulated robot used path integration while flying 1,000 different outbound trajectories, following a block-wave pattern that could be useful for a search mission (Fig. 2a). Each outbound flight was followed by a straight inbound trajectory back home based on noisy path integration, leading to an end point offset from the home location. We used a Gaussian noise model, which assumed the heading to drift over time. Specifically, noise was added to the heading estimate after each time step in the simulation from the normal distribution \({\mathcal{N}}(0,t{\sigma }_{\psi }^{2})\), with t in seconds. The distance estimation noise was modelled as \({\mathcal{N}}(0,d{\sigma }_{d}^{2})\), with d the distance covered during the time step in metres. We fit the parameters of the noise model to the real robot’s straightforward path integration method (Supplementary Information Section 11): a tiny downward-looking optical flow sensor and laser for estimating velocity and gyro measurements for updating the heading estimate. a, Results of 1,000 simulated foraging flights, in which a robot used path integration while first flying a search pattern outbound trajectory and then a straight inbound trajectory home (star). Teal and orange dots represent end points of the outbound and inbound flights, respectively. The dashed teal circle contains 99% of the outbound flight end points, whereas the dashed grey circle contains 99% of the inbound end points. For the expected robot path integration noise, the area of the inner circle is 3.84% of the area of the outer circle. b, Effect of path integration noise level on the relative area of the LHA with respect to the total flight area for methods with and without a compass. c, Image of the artificially generated landscape used in the simulation learning flight and homing experiments. d, Visual homing results in ten different simulated forest environments. The radius factor represents the distance of initial positions from the home location, with factor one corresponding to the edge of the LHA (10 m, dashed vertical line). Light-blue lines show the success percentages of the proposed Bee-Nav strategy per environment, averaged over 16 runs per circle radius, with the dark-blue line indicating the median over all environments. The shading indicates the 25th to 75th percentile. The results in red are for a snapshot-based homing method34 and those in green for the perfect memory method51,52. e, Example trajectories starting from a 20-m circle radius. Green and red lines show successful and failed homing trajectories, respectively, light-green circles are tree locations and the small arrows are the predicted home direction. f, Histograms of the distance and absolute angular errors for the home vector estimation for the test set images of the LHA of one environment. Figure 2b shows the percentage of the LHA with respect to the total flight area for various amounts of path integration noise. Even with the substantial path integration drift of the robot, the LHA only needs to be 3.84% of the total flight area to capture 99% of the journey end points (Fig. 2b, σψ = 0.63, σd = 0.10). The lines represent different scaled versions of the robot’s noise (both standard deviations multiplied by a factor ranging from 0.1 to 1.5). Moreover, the LHA was 0.74% when odometry noise was similar to that of a more advanced, computationally more expensive method for visual odometry, SVO+GTSAM41. Finally, the noise model was fit to a bioinspired odometry method with a magnetometer heading measurement31 for more precise path integration42, resulting in an LHA percentage of only 0.24%. Insects also exploit absolute heading measurements to reduce integration drift, for example, through the polarization of sky light. A coarse approximation of the path integration accuracy of desert ants27 and honeybees43 led to LHA percentages of 7.6% and 3.4%, respectively (Supplementary Information Section 11). A small LHA implies that the neural network can also be small, enabling inference on limited, energy-efficient computing hardware. To quantify the visual homing performance, we performed further experiments in the visually realistic NVIDIA Isaac simulator with a small 42.3-kB attention neural network (Fig. 2c). The learning flight trajectory (Supplementary Information Section 6) fits in a 10-m-radius circle around the home location. The simulated robot performed visual homing, following the vectors output by the network, starting at various distances from the home location. Figure 2d shows the results of 800 simulated visual homing runs in ten different randomly generated forests. The success rate of the proposed strategy was 100% within the LHA radius and, depending on the environment, generalized even up to 2.5 times the LHA radius. This generalization beyond the LHA is supported by our theoretical analysis (Supplementary Information Sections 1–5). Figure 2e shows 16 visual homing runs of Bee-Nav, starting at two times the LHA radius. The visual homing runs that failed typically got stuck in local minima outside the LHA, close to trees that obstructed the view. Within the LHA, the angular errors of the network were smaller than about 40° and the distance errors were smaller than 2 m (Fig. 2f). Visual homing will generally be successful if angular errors stay below 90°. We compared the visual homing of Bee-Nav with two alternative approaches (Fig. 2d). First, we compared it with a snapshot-based approach34 that relies on comparing views around the current position with a single snapshot taken at the home location (red lines). It started to deteriorate as soon as the view became too different from the home snapshot. Second, we devised a ‘perfect memory’ approach that stored all of the images and target vectors gathered during the learning flight as snapshots. During navigation, the simulated robot compared the current image with all stored snapshots. It selected the k = 3 best-matching snapshots and followed the average of their target vectors. The visual homing of Bee-Nav is substantially more efficient and more accurate than the alternative approaches. We expect that the better performance outside the LHA compared with perfect memory is because of the ability of the neural network to attend to relevant landmark objects, even if they are further away and hence smaller in image size. Finally, a comparison was made with a biologically plausible mushroom-body-inspired approach39. Although showing great promise, it does not yet achieve similar performance to Bee-Nav (Supplementary Information Section 12). We successfully implemented Bee-Nav on a small flying drone, performing real-world experiments in different environments (Figs. 3 and 4). The drone was fitted with an omnidirectional camera and a Raspberry Pi 4 for executing the small neural networks for visual homing. In our experiments, we used two types of network: a ‘compact’ 3.4-kB five-layer neural network and a slightly larger, 42.3-kB eight-layer ‘attention’ neural network (Methods). Because our main interest was to verify the performance of the proposed strategy in various environments, we predominantly trained the neural networks after the learning flight on an Apple MacBook Air ground station laptop (offline, offboard training). For most real-world applications, offboard learning will be acceptable. However, onboard learning would improve the robot’s degree of autonomy. Hence, we also tested onboard, offline learning and onboard, online learning (that is, after and during the learning flight, respectively). a, Time-lapse image of one experimental set-up showing four visual homing flights in a scene containing obstacles, such as screens and poles, inside the LHA. Each flight begins at a different position at the edge of the arena with a varying heading, moving towards home (located at the centre, indicated by the red cross on the ground) using the output from the homing network at each step (Supplementary Video 5). b, In a different environment set-up, a top-view plot showing eight visual homing trajectories reaching 0.5-m areas around home (dashed grey lines) starting from different starting locations (grey pentagons). The trajectories are guided by models trained in each of the six learning set-ups: attention network and compact network trained offboard, offline (cyan and blue); attention network and compact network trained onboard, offline (purple and red); and attention and compact network trained onboard, online (green and yellow). c, Comparison of distributions of absolute angle prediction and distance prediction errors at each step over all considered homing trajectories (nhoming-flights = 8 per learning set-up). a, Time lapses of all four phases of the proposed navigation strategy performed by the robot flying in a 30 × 40-m indoor hall at Unmanned Valley, Valkenburg (UVV), that is, the large indoor area. b, GPS trajectory of an outdoor robotic navigation experiment at the 400 × 500-m UVV testing grounds (the large outdoor area), indicating the different phases of the flight. Scale bar, 50 m. c, Homing success percentages in the experimental environments (Extended Data Fig. 6). Satellite basemap imagery provided by Esri World Imagery; sources: Esri, i-cubed, USDA, USGS, AEX, GeoEye, Getmapping, Aerogrid, IGN, IGP, UPR-EGP and the GIS User Community. Available at https://services.arcgisonline.com/ArcGIS/rest/services/World_Imagery/MapServer. First, we tested the neural-network-based visual homing in a 10 × 10-m indoor flight arena (Fig. 3a). Despite real-world path integration noise on the learning targets, the drone successfully ended up within 0.5 m of the home location in 100% of the 48 homing flights (Fig. 3b and Supplementary Video 1). Direction errors were predominantly below 40° and distance estimation errors below 1.5 m (Fig. 3c). All manners of learning led to successful homing (Fig. 3b). Notably, onboard, online learning performed slightly better than onboard, offline learning. This is probably because of the different angle resolution when performing data augmentation (Extended Data Table 1). Still, offline, offboard learning, which uses more learning iterations and data augmentation, gave the most accurate predictions and the shortest homing paths. Hence, we used this way of learning for the remainder of the experiments. Subsequently, we applied the full navigation scheme to larger environments, using the compact neural network. Time lapses of one of those experiments in a 30 × 40-m indoor hall, with all of the phases of Bee-Nav, show successful homing even under large drift (Fig. 4a and Supplementary Video 2). We made the robot meander during the outbound flight to cover a large distance during this flight phase. The uniformly textured floor posed challenges to visual odometry, occasionally resulting in a substantial displacement after the path-integration-based phase of the inbound flight. The subsequent visual homing effectively cancelled path integration drift. Moreover, we performed long-range flights at a large, wide-open outdoor test terrain with a permissible flight area of 400 × 500 m (Fig. 4b). This resulted in new challenges. For example, the presence of strong wind led to large compensatory attitude angles, requiring algorithmic adaptations to compensate for the resulting camera tilt (Methods). Other challenges included quickly changing lighting conditions and the absence of close-by landmarks. Hence, at this location, we added several objects to the ground to serve as landmarks (Extended Data Fig. 6f). Because the compact network did not reach sufficient prediction accuracy in this environment, we used the attention network for homing (Supplementary Information Section 13). The robotic experiments confirm the effectivity and efficiency of Bee-Nav. For most environments, with outbound flight distance in the range 30–110 m, the homing success was 100% (Fig. 4c). Only for the largest outdoor environment, with flight distances in the range 200–330 m, homing success reduced to 80% during days with low wind conditions and 50% in high winds (mean wind speeds Uwind > 5 m s−1, with wind gusts > 10 m s−1; Supplementary Video 3). The reduced success percentage was mainly because of factors such as sun glare and the wind causing the camera to tilt, thus worsening the visual homing accuracy when further away from the learning flight trajectory. Still, in that environment, learning a 10-m-radius area with the 42.3-kB attention neural network sufficed to fly up to 600 m away and come back along an almost straight 150-m path (Supplementary Video 4 and Extended Data Fig. 8f). We expect our work to have implications for both robotics and biology. For robotics, it brings long-range navigation in reach of small, resource-constrained robots. At present, robotic navigation mainly relies on creating detailed 3D maps of the environment. These maps have as advantages in that they (1) allow for optimal trajectory planning to any place in the environment and (2) may be of interest to the end user. Bee-Nav purposely sacrifices these advantages to substantially reduce computational requirements. The small visual homing neural networks use up to 42.3 kB of memory, which is approximately three orders of magnitude less than the memory required by high-precision maps (hundreds of MBs for modestly sized environments2,3; Supplementary Information Section 9). Moreover, the networks are computationally efficient: they easily run on the robot’s Raspberry Pi 4 and could even be suitable for microcontroller processors. This implies substantially reduced mass, power and economic cost of computing hardware. Despite its present limitation to a single home location, Bee-Nav already enables robots to move in an area of interest, perform tasks there and occasionally return home for recharging or bringing back data or objects. This will enable swarms of small, lightweight robots to perform applications such as monitoring crops in greenhouses or tracking inventory in warehouses. For real-world application, the inherent passive safety brought by lightweight robots44 will be essential, because it ensures the safety of human workers. The computational and memory efficiency of Bee-Nav can also bring benefits for larger autonomous robots, but this will not extend to all robot scales and tasks. We identify five research avenues to further improve and characterize the approach. First, the visual homing of the robot should be followed by the recognition of the home, which could be a recharging station, and a subsequent precision landing. Second, in the case that visual homing fails, the robot might improve its chances of still arriving home by executing a structured search—just as insects do28. Third, path integration in outdoor environments could be improved by including a magnetometer or sun detection system for better heading estimation. This will substantially extend the navigation range for a given LHA size (Fig. 2b). Fourth, the visual homing networks could output not only a home vector but also a measure of uncertainty. This would enable the robot to start homing immediately when it starts recognizing the LHA, combining information from path integration and view memory27. Moreover, the robot could use its uncertainty to trigger a new learning flight if the environment around the home changes substantially, for example, if an important visual landmark is removed. Fifth, it would be beneficial to perform a deeper investigation of the environments and conditions in which visual homing neural networks can successfully learn to predict home vectors. Given the high capacity of deep neural networks, we expect that they will be able to exploit relevant visual landmark information, even if it is scarce. Nevertheless, it remains an open question how large a deep neural network needs to be to extract the visual homing information in a given environment and for a specific size of the LHA. Our experiments show that very small neural networks (3.4–42.0 kB) may already suffice for LHAs on the order of about 20–120 m2 in different real-world environments. However, there may be environments for which these networks do not have sufficient capacity. A robot would be able to detect this by itself, because it would lead to a high training error. The robot could then automatically scale up the complexity of the network. Still, there are environments with scarce visual landmarks, such as long office corridors with many similar-looking places or large, wide-open terrains. This would also lead to a high training error, but scaling up the network would not improve performance. In real applications, either end users or the robots themselves could choose home locations to ensure the presence of identifiable, close-by landmarks. Other conditions could have an influence on successful learning, such as opaque or dynamic objects. Dynamic objects that only occupy a small part of the image (such as the experimenter at some distance from the drone) have a negligible influence on the predictions (Supplementary Information Section 8). However, dynamic phenomena that change a large part of the omnidirectional image, such as sun glare, can affect the performance. Dealing with such situations may require modifying the sensor set-up or performing more image processing (for example, masking out dynamic objects). Opaque objects in the LHA do not affect the learning success, as the home vector targets are determined by path integration (Supplementary Video 5, Supplementary Information Section 8 and Fig. 3a). For biology, the proposed strategy offers a new perspective on flying insect navigation. The robotic experiments have shown that Bee-Nav successfully passes the test of the real world. One of its essential elements is that path integration provides the targets for home-vector learning. In our theoretical analysis, we show that self-supervised learning on the basis of imperfect path integration estimates leads to tortuosity of the visual homing trajectory (Supplementary Information Section 4). We performed a preliminary verification of the potential biological relevance of this finding by means of reanalysing honeybee learning and foraging flight data4 (Supplementary Information Section 7). It shows that the behaviour of honeybees is characteristic of the considered manner of learning. However, specific experiments will be necessary to uniquely identify path-integration-based learning as the cause of the tortuous trajectories. This could involve manipulating the path integration machinery45 of the insect during learning flights and evaluating ensuing inbound flight patterns. Another notable element of the strategy is the learning of a full home vector, representing homing direction and distance. Robotic experiments demonstrated the use of the vector’s magnitude, allowing speed modulation for faster visual homing at larger distances. Knowledge of home distance aligns with biological observations, both behaviourally46,47,48 and neuronally18. To enhance the potential relevance to biology, future work could aim for biologically more plausible neural networks. A promising avenue is to enhance the neural networks inspired by the insect mushroom body32,39 to estimate higher-resolution directions instead of just discerning between left and right. This could be achieved by mapping the Kenyon cells in this method to a larger set of output neurons, potentially representing directions in a similar manner to ring attractors18. It could also be worthwhile revisiting known neural data from, for example, the insect mushroom body and investigating whether the neural structure could encode more fine-grained directional data. Finally, in our current implementation, the robot uses a home vector, expressed in its body reference frame, for direct action. Moreover, it learns only the area around the home location. Hence, the present proposed navigation strategy does not yet involve any cognitive map according to the common definition49. In future work, the strategy could be extended to include the learning of different places and the capability to take shortcuts between them. As suggested previously50, if two different places are stored in memory in a global, home-centred reference frame, a simple vector subtraction would suffice for determining the vector from one place to the other along an unvisited path. Although such an extension to Bee-Nav would be straightforward to implement when done with a traditional algorithm, it will be more challenging to realize this with neural machinery alone. Robotic experiments could show the costs and benefits of such an extended strategy, helping to bring the ingredients and trade-offs of using neural cognitive maps into sharper focus. The results in Fig. 2 are based on two simulators: (1) a simplified simulator that was used to determine the ratio of the LHA versus the total navigation area; and (2) a visually realistic simulator that was used to test the visual homing with a convolutional neural network in various generated forest environments. In this simulator, we simulate a drone flying outwards from a starting position for a given time period and then trying to return straight home. Reflecting the real experiments, we model the drone as using a noisy gyroscope measurement for updating its heading and a noisy velocity measurement for estimating its travel distance. During both the outbound and the inbound flight, the drone determines its position with the help of path integration. Owing to the noisy nature of the heading update and the velocity estimation, the path-integration-estimated position will increasingly drift from the ground-truth position. We use a Gaussian noise model for path integration drift22,27,53. For ‘compass-less’ path integration, as performed by the real drone, the model adds noise to the heading estimate after each time step in the simulation. To this end, samples are drawn from the normal distribution \({\varepsilon }_{\psi }\sim {\mathcal{N}}(0,t{\sigma }_{\psi }^{2})\), in which t is the time in seconds. The noise is added to the actual turn rate and accumulates over time, leading to substantial heading drift: \(\hat{\psi }\leftarrow \hat{\psi }+\dot{\psi }+{\varepsilon }_{\psi }\). Furthermore, the velocity estimation noise is likewise drawn from the normal distribution \({\varepsilon }_{d}\sim {\mathcal{N}}(0,{d\sigma }_{d}^{2})\), in which d is the distance travelled in the simulation time interval. It accumulates in the position estimate of the simulated drone: \(\hat{x}\leftarrow \hat{x}+\cos (\hat{\psi })(d+{\varepsilon }_{d})\) and \(\hat{y}\leftarrow \hat{y}+\sin (\hat{\psi })(d+{\varepsilon }_{d})\). With this “path integration noise model, the simulated drone performs a 3-min outbound flight with a speed of 2 m s−1. To simulate a search task, the simulated drone flies a block-like search pattern, changing direction after every 40 m. After the outbound flight, the drone attempts to fly straight home with a higher speed of 4 m s−1. Every 0.5 s, the simulated drone changes its heading to point at the presumed home location. The simulation run stops when the drone estimates that it is at (0, 0). The statistics per noise setting are based on 1,000 such simulation runs. For the investigation of different noise levels, both elements of the noise model are scaled with the factors (0.1, 0.25, 0.5, 0.75, 1.0, 1.5). The sizes of the circular LHA and total flight area are then based on the 99th percentile of the distances from the home location, for both the outbound end points and the inbound end points. We also model ‘compass-based’ path integration, as performed by some robots with a magnetometer31 and by insects by using sky-light polarization42. In that case, at each time step, the simulated drone receives the actual heading perturbed by Gaussian noise: \(\hat{\psi }\leftarrow {\psi }^{\ast }+{\varepsilon }_{\psi }\). This leads to much more accurate path integration. For the simulation experiments, we selected noise settings that resulted in a similar drift to that recorded in our own experiments or in the literature (Supplementary Information Section 11). Notably, we selected σψ = 0.63° and σd = 0.10 m to best approximate the odometry drift of our own robotic system, which gave a mean yaw drift after 100 s of 5.10° and a mean position drift after 100 m of 0.88 m. The main goal of this simulator was to determine whether a convolutional neural network is able to reliably estimate home vectors from visually realistic images, using these estimates to travel to the home location within the LHA. The simulator used is NVIDIA’s Isaac Sim54, as it allows quick acquisition of omnidirectional images. We use a photo of a meadow landscape as background image and generate a ‘forest’ by placing 40 trees from NVIDIA’s vegetation library in a 50 × 50-m area around the home location. The trees are placed uniformly into this area, while ensuring that: (1) a 5-m-radius circle around the home is free so that it is accessible; (2) trees are further away from each other than 5 m to avoid intersection; and (3) there are maximally three trees in a 10-m-radius circle around the home location to avoid too much clutter in the learning area. The experiments reported in Fig. 2 are based on ten such randomly generated forest environments. Proposed strategy details. For the aggregate results in Fig. 2, we performed experiments in ten different environments. In each environment, we first perform a learning flight with the same learning flight pattern followed by the robot, with parameters nloops = 6, mpoints = 150 and bspacing = 0.35 (see the ‘Learning flight’ section). As in the real robot experiments, the learning flight positions assumed by the robot are different from the actual positions owing to path integration drift. If a position risks being inside a tree, it is moved to be 0.5 m away from the landmark centre. The learning flight results in 147 images taken in a 10-m-radius area. The noisy positions and headings resulting from the path integration are used for determining the targets for the neural network learning. We train an attention network (explained later) for 150 epochs by using the Adam optimizer with a learning rate of 0.0005 and batch size of 8. We use 95% of the dataset for training and 5% for determining a validation loss. During training, rotational augmentation is used, in which each sample image and target are rotated with the same uniformly random angle from the interval [0, 2π]. After training, we simulate a homing run as follows. An omnidirectional picture is taken at the initial location. It is fed to the neural network, which determines a home vector that has both a direction and a magnitude. The vector is used in the same way as on the robot to determine a step size and direction (see the ‘Use of output’ section). When within 2 m of a tree, the desired motion vector is adapted with a basic artificial potential field method55 to veer away from the obstacle. After executing the step, a new image is taken and the procedure is repeated. Each run ends when the simulated drone comes within 1.2 m of the home location or when it has taken 50 steps. For obtaining the aggregated results in Fig. 2, we perform homing runs at 16 locations for different distances, equally spread around a circle. If an initial position is closer to a tree than 1 m, it is moved away from the tree centre to a distance of 1 m. The initial distance is determined by the radius factor, for which 1.0 places the drone at the edge of the LHA. The investigated radius factors are (0.5, 1.0, 1.5, 2.0, 2.5). Snapshot method. We compare the proposed strategy with a snapshot-based method34. The motivation for choosing this particular snapshot method is that its performance is robust if the current view is similar enough to the snapshot. For this method, a single snapshot is taken at the home location. The simulated drone performs homing as follows: it first moves to a position to the left, right, front and back of the current position. At each displaced position, an image is taken. This image is exhaustively rotated pixel by pixel. For each rotation, the image difference D = |Ic − Is| is determined with the home snapshot, in which Ic is the current, rotated image and Is is the snapshot image. Per displacement, the minimal image difference min(D) is retained. Having four values for the image difference allows the simulated robot to estimate the best direction to reduce the image difference (Dx, Dy). The robot then moves 0.5 m in that direction. Although this method requires only a single snapshot at the home location, it does require many movements on the part of the robot. Moreover, exhaustive rotations are computationally expensive. Perfect memory method. We also implemented a method that uses the same learning images as the proposed strategy but now stores them for exhaustive matching during navigation. Hence, this perfect memory method stores 147 ‘snapshots’. At each time step, the simulated robot compares the current image with all snapshot images, using the same procedure as detailed for the snapshot method—rotating the image pixel by pixel and retaining the minimal image difference (min(D)) per snapshot. After this exhaustive image matching, the k = 3 most similar snapshots are selected and the corresponding target vectors averaged to give the desired motion vector. This method is inspired by two perfect memory methods from the literature51,52. Both of these methods are more efficient than exhaustive matching in different ways. In ref. 52, only four snapshots were chosen out of all snapshot images made on a grid, on the basis of an observation that more snapshots did not substantially improve homing performance. Here we included all snapshots to ensure maximal performance at the cost of more computation. In ref. 51, the navigation was purely based on left and right commands, depending on the home being visible in the left or right visual hemisphere during a real wasp’s learning flight. Here we stored real-valued target vectors, that is, with a direction and a distance, for better performance and more adequate comparison with the proposed navigation method. The robotic platform is a custom-built quadcopter that operates autonomously, with all perception and computing handled by onboard systems without reliance on external positioning (Extended Data Fig. 1). The drone is equipped with a Raspberry Pi 4 as its primary onboard computer. A Pixhawk 6C Mini flight controller, running the PX4 autopilot firmware, manages low-level flight control. The perception system consists of several key sensors. A Raspberry Pi V2 camera fitted with a catadioptric omnidirectional lens (Kogeto Dot 360 panoramic lens) serves as the main vision sensor. For odometry, a PMW3901 optical flow sensor provides horizontal motion data, whereas a TFmini-S LiDAR rangefinder measures height for vertical positioning. These raw sensor data are combined with inertial measurement unit data by an extended Kalman filter, running on the Pixhawk, to generate the final odometry estimate (position relative to home and current heading). Furthermore, a RealSense D435i depth camera and TF-Nova range sensors are attached for some of the experiments and used only for obstacle avoidance (see the ‘Obstacle avoidance’ section). Finally, a Holybro F9P GPS module is mounted to record ‘ground-truth’ position data during outdoor experiments. Other available sensors, such as the magnetometer and barometer, are disabled for all experiments to ensure consistency. The onboard software operates in a modular architecture using Docker containers. The primary vision system resides in a dedicated ‘camera container’, for which the omnidirectional camera is activated by an HTTP request. Within this container, captured images are first preprocessed using the methods detailed in the ‘Image processing’ section. Within the same container, the network then performs inference and outputs a 2D vector that represents the predicted coordinates of the home position in the current body reference frame of the drone. This vector is subsequently used to derive the desired yaw angle and distance to home, which are relayed back to the main navigation node for flight control. The ‘navigation node’ runs in a separate container using ROS2. It receives the output from the neural network as well as current state estimates (position and heading) from the PX4 autopilot56. On the basis of this information, it sends high-level control commands back to the PX4. Sensor data are routed directly to the flight controller: optical flow data are transmitted by means of UART and distance sensor data are passed by means of I2C. A catadioptric omnidirectional camera, which uses a convex mirror and a vertically oriented lens, captures a 360° panoramic view. As can be seen in Extended Data Fig. 3a, the raw output is an annular (ring-shaped) RGB image, in which the central and outer areas contain no useful visual information. A preprocessing pipeline is applied to each image. First, the annular region of interest is isolated using a predefined binary mask. Second, this region is unwrapped into a rectangular panorama through a linear–polar transformation, implemented with the linearPolar function from the OpenCV library. Finally, the resulting image is rotated to align with the body-frame orientation of the drone and resized to 3 × 192 × 1,800 pixels, as required by the neural network. The network training uses a self-supervised learning approach in which ground-truth labels are derived directly from the onboard odometry data of the drone. As described in Extended Data Fig. 4, for each captured image, the estimated global position of the drone to home, represented by the vector \({\bf{p}}=[\begin{array}{c}{p}_{x}\\ {p}_{y}\end{array}]\), and its estimated heading (yaw), ψdrone, are logged. The objective is to calculate a target home vector label, L, which represents the home position in the body-fixed reference frame of the drone. This vector is computed in two steps. First, the vector pointing from the current position of the drone to the home origin (0, 0) in the world frame is determined, which is simply −p. Second, this vector is transformed into the reference frame of the drone by applying a clockwise 2D rotation matrix, R(−ψdrone), which aligns the world frame with the current heading of the drone. The final label vector L is calculated using the following operation: The resulting components, Lx and Ly, directly represent the coordinates of the home location relative to the forward-facing perspective of the drone. This vector L serves as the ground-truth label for training the neural network. Strong wind conditions (> 5 m s−1 with gust >10 m s−1) pose a substantial challenge during outdoor flights, forcing the drone to maintain a large tilt angle—up to 30°—to counteract the aerodynamic forces. This tilt introduces two primary issues in the captured omnidirectional images, which can provide false cues to the neural network. First, if wind conditions cause the tilt of the drone to differ from what it was during the learning phase, the learned visual cues—such as the apparent distance from landmarks to the bottom of the frame—become unreliable. This can lead to a faulty estimation of the true position of the drone, even when it is at the correct spot. Second, it causes a sinusoidal distortion of the horizon line in the unwrapped panoramic image, which in turn corrupts the perceived spatial relationships between landmarks. These problems caused by camera tilt are well known in the omnidirectional vision-based homing literature57. To mitigate these effects, we correct the distortion by dynamically adjusting the centre point used in the linearPolar unwarping process (also see Extended Data Fig. 3d). Two methods are used to determine the necessary offset for this unwarping centre: (1) model-based correction: a linear model maps the current pitch and roll angles of the drone, obtained from the extended Kalman filter, to the required x–y offset for the unwarping centre and (2) vision-based correction: when a clear horizon is visible, it is detected in the image and used as a geometric reference to calculate the centre point that flattens the sinusoidal distortion. This vision-based method is reminiscent of the method presented in ref. 58. Both methods have their weaknesses, so the choice between these two correction methods is made dynamically on the basis of environmental conditions. The vision-based correction is given priority in environments with a consistently visible ground horizon, as it adapts in real time to the current image and is independent of other sensor measurements that may be subject to delay. In environments in which a stable horizon is not available, the system defaults to the model-based correction, which provides sufficient reliability. Please note that, if the model-based correction relies on attitude estimates based on the inertial measurement unit, it will be susceptible to drift over time. This can deteriorate the results for long trajectories. Two neural network models have been proposed for the visual homing mode: an extremely lightweight convolutional neural network (referred to as the ‘compact network’) and an only slightly larger attention-based Inception network (referred to as the ‘attention network’). The detailed architecture of these two models can be seen in Extended Data Fig. 2. The compact network is designed for high efficiency, containing four convolutional layers and a final fully connected output layer with two neurons, with a total of only 868 parameters (3.4 kB). The attention network has 10,820 parameters (42.3 kB) and is built on two custom Inception modules59. Each module uses parallel branches with different kernel sizes, pooling and dilated convolutions to capture features at several scales. Crucially, each module also incorporates a spatial attention mechanism60, which generates a map to reweight features and allow the network to focus on the most salient spatial regions of the image. This second, slightly deeper network is composed of the two Inception modules, two extra convolutional layers and two fully connected layers, with weights initialized using the Xavier uniform method. Both models use the tanh activation function and are designed to take panoramic colour images with a size of 3 × 192 × 1,800 pixels as input. The output of the network is a 2D home vector \({{\bf{h}}}_{{\rm{pred}}}=[\begin{array}{c}{h}_{x}\\ {h}_{y}\end{array}]\). which represents the predicted location of the home position in the body-fixed reference frame of the drone. This vector is directly translated into control commands, as described in Extended Data Fig. 5. The required change in heading, ∆ψ, is determined by the angle of the vector, calculated as ∆ψ = atan2(hx, hy), in which a positive angle corresponds to a clockwise rotation. The magnitude of the vector, dpred = ‖hpred‖, determines the step size (distance), s, for the next forward movement of the drone according to the linear relationship s = kdpred + smin, in which k is a scaling factor and smin is the minimum distance it should take. For our experiments, we use a constant scaling factor of k = 0.13. The minimum step size, smin, is set to 0.1 during standard tests and increased to 0.5 in windy conditions to ensure that the drone makes sufficient progress against aerodynamic forces. After rotating to the new heading, the drone moves forward a distance s. On reaching this new position, the cycle repeats with the capture of a new image. This strategy ensures larger steps when far from home and smaller, more precise steps near the target to prevent overshoot. Experiments were conducted across a variety of indoor and outdoor environments to validate the robustness and scalability of the system (Extended Data Fig. 6). Initial algorithm validation (visual learning and homing) was performed in the 10 × 10-m CyberZoo at TU Delft, a controlled lab space with motion capture system as ground truth. Full-scale flight tests were conducted in larger, more challenging locations. To test performance in GPS-denied environments, we used two indoor hangars: the 30 × 40-m Unmanned Valley indoor facility in Valkenburg, the Netherlands (the large indoor area), which provides a large, visually structured area, and a 30 × 25-m section of the Delft Drone Initiative flight hall (the small indoor area). To test against more challenging conditions, outdoor experiments were performed in two distinct open-field environments: the outdoor test field at Unmanned Valley, a 400 × 500-m permissible flight area (the large outdoor area), characterized by natural terrain and lighting in an open field, and a 35 × 20-m tennis court in Sardinia, Italy (the small outdoor area), which provided a visually distinct, closed scene. In a new environment, the drone acquires training data during a learning flight conducted in a small area around the designated home location. Because the learning flight trajectory determines the data for learning the homing vector, it has a substantial influence on the subsequent homing performance. In our experiments, we did not mimic the actual, varying honeybee learning trajectories (Supplementary Information Section 7). Given the proposed technological solution, we opted for a trajectory pattern that ensured covering a circular region around the home location. A comparison of an Archimedean spiral with a ‘wasp-like’ flight pattern51,61 showed that the latter resulted in better homing performance, as it does not lead to the learning of spurious cues (Supplementary Information Section 6). Hence, the wasp-like pattern was used for all experiments. This pattern is generated algorithmically, starting with a classical Archimedean spiral defined in polar coordinates by the equation r = bθ, in which r is the radius, θ is the angle and the parameter b controls the distance between the arms of the spiral. The angle θ is discretized into m steps over a total of n full rotations, spanning from 0 to 2nπ. The key ‘wasp-like’ modification is a periodic mirroring of the trajectory: each time the path crosses the negative y-axis, the x-coordinates for all subsequent points are inverted. This creates a series of back-and-forth loops that expand outwards from the centre. The parameters are adjusted on the basis of the environment size; for example, for a small 10 × 10-m area, the path consists of nloops = 4 discretized into mpoints = 36 waypoints with bspacing = 0.1, creating a learning flight with a maximum radius of approximately 2.5 m. For larger outdoor areas, the pattern is expanded to nloops = 5 loops with mpoints = 36 waypoints and bspacing = 0.2, resulting in a learning flight with a maximum radius of approximately 6.3 m. Once learning is completed, the network is trained using one of the learning set-ups described below. Depending on the mission constraints and resource availability (for example, time, hardware and so on), one of three distinct learning set-ups can be used: offboard, offline learning; onboard, offline learning; and onboard, online learning. Extended Data Table 1 summarizes the computational requirements and performance in one of the experiments for each set-up. Offboard, offline learning is used when a ground station with sufficient processing power (a modern CPU) and data transmission (for example, Wi-Fi, capable of transferring approximately 100 MB of data) is available. On completion of the learning flight, the raw omnidirectional images and associated labels (generated from the specific odometry data; see the ‘Data labelling’ section) are transferred to a ground station laptop. During the experiments, we used an Apple MacBook Air, with Apple M1 chip and 8 GB unified memory. The network is trained using extensive data augmentation to improve generalization, specifically by means of virtual rotation and colour augmentation (also see Extended Data Fig. 3b,c). For virtual rotation, we make use of the panoramic nature of the omnidirectional images to simulate different camera headings from a single captured frame. This is achieved by horizontally shifting the image pixels to rotate the gaze direction of the camera. For each captured image, we generate 360 new training samples by rotating the gaze in 1° increments. The corresponding label vector is recalculated for each shift to reflect the new relative heading to the home position. Subsequently, colour augmentation is applied to account for variable outdoor lighting. We duplicate each virtually rotated image and adjust its brightness by a factor sampled from U(0.9, 1.1) and its contrast by a value from U(−10, 10). For onboard, offline learning, when a ground station is unavailable or data transmission is unreliable, training is performed locally on the drone’s onboard computer (Raspberry Pi 4). To accommodate faster training with the more limited computational resources, we introduce two optimizations compared with the offboard approach. First, colour augmentation is omitted to reduce preprocessing overhead and duplication of the dataset. Second, the virtual rotation step size is increased from 1° to 5°, reducing the training dataset size by a factor of five. Despite the slower onboard processor, these optimizations ensure that the total training time remains comparable with offboard methods while maintaining successful homing performance. For missions requiring immediate execution (for example, outbound flights have to be executed less than 2 min after the learning flight), we use onboard, online learning. In this mode, training initiates in-flight immediately after the first image is captured. We use multithreaded processing on the Raspberry Pi: specific cores are dedicated to navigation and communication, whereas two cores are isolated for network training. Image capture and training happen asynchronously. Captured images are continuously appended to an image bank (stored as tensors in RAM), which serves as a replay buffer for the training thread. Given the short duration of the learning flight and the small number of images, the memory footprint is manageable, eliminating the need for a deletion policy. The training thread continuously samples batches from this buffer and applies random virtual rotation (sampled from virtual rotation step size of 1º). Training concludes exactly one minute after the learning flight ends; this interval ensures that the final learning images are sufficiently represented in the training distribution. All training configurations use the Adam optimizer with a learning rate of 9 × 10−4 and a batch size of 4. The offboard and onboard methods are trained for one epoch, whereas the online learning set-up uses a continuous rolling update strategy. All methods were validated in the CyberZoo environment, achieving a 100% success rate across all visual homing trials. Extended Data Table 1 and Fig. 3b summarize the training configuration and navigation performance for each method. After the learning, the forage part of the navigation strategy is implemented as a three-phase process: an outbound search, an inbound return through odometry and a final visual homing phase. During the outbound phase, the drone follows a predefined trajectory designed to cover the test area. Throughout this phase, the drone continuously updates its state estimate (position and heading) relative to its starting point using onboard odometry. Although simple paths are used for most experiments, more complex patterns, such as a grid search, are also used in some indoor environments to simulate real-world applications such as search and rescue. Once the outbound trajectory is complete, the drone switches to the inbound phase. The flight controller is commanded to return to the home coordinates (0, 0) based on the current odometry estimate. The drone executes a direct, high-speed flight towards this estimated home position. On reaching the odometry-based goal, the final visual homing phase is initiated. Owing to the expected accumulation of odometry drift, the estimated position of the drone does not perfectly align with its true starting location. Therefore, the system switches to the neural-network-based visual control strategy, described previously in the ‘Use of output’ section, to perform the final, precise approach to the home location. In all of our experiments, the home location is not visible by itself, so we stop the experiments when the drone arrives close enough to the home location. A success is hereby defined as the drone ending up within 0.5 m of the home location. Some example trajectories of these full flights can be seen in Extended Data Figs. 7 and 8. Inspired by Wedgebug62, we implemented a reactive detect-and-avoid system based on a finite-state machine, in which the sensing hardware evolved to match the computational constraints of the onboard Raspberry Pi. Initial experiments used an Intel RealSense D435i depth camera with the depth map segmented into left, centre and right average-depth bins, whereas the later experiments used three TF-Nova LiDAR sensors monitoring a 1° × 14° field of view for each sector. The avoidance logic interrupts the primary navigation loop whenever the front distance dfront drops below a predefined stopping threshold dstop, at which point the evasion trajectory is calculated on the basis of the specific flight phase. For the learning, outbound and inbound phases, the core avoidance logic is identical. The system monitors the left, centre and right sectors. If the centre is blocked, the drone determines which side (left or right) is clear, rotates in that direction and executes a forward movement of devade. Immediately after this evasion, it realigns its yaw to face the original target waypoint. If all three sectors (left, centre and right) are blocked, the system triggers a panic mode: the drone rotates by a larger angle ψdrone, travels a distance of dpanic and attempts to resume navigation by realigning to the target waypoint again in this new position. However, if after nattempts the same target waypoint is still not reached, the next movement differs by phase: Learning phase: if the point remains unreachable after n tries, the system skips it, takes an image and records the label at the current position and heading and proceeds to the next learning waypoint. Outbound phase: if blocked, the system skips to the next outbound waypoint. If the outbound path is completed, it automatically switches to the inbound phase. Inbound phase: the system persists in trying to reach the odometry coordinates (0, 0). However, if the drone is stuck but within 2 m of the odometry coordinates (0, 0), it aborts the inbound flight and immediately switches to visual homing. During the homing phase, the detection logic (checking left/centre/right) and the evasion movement devade remain the same. However, the post-evasion behaviour is different: the drone does not realign to the previous target. Instead, it simply captures a new image at its current position, queries the network for a new prediction, rotates to this new predicted heading and restarts the obstacle detection and evasion loop again. The biological reanalysis data are available from the corresponding authors on reasonable request. All robotic experimental data are available at https://doi.org/10.4121/a0217a20-0443-48b2-8a04-9609ac267029. All codebases (running the simulation experiments, onboard the robot, training and evaluating the networks) that have been used to generate the results in this article are available at https://github.com/tudelft/Bee-Nav. Beekman, M. & Ratnieks, F. L. W. Long-range foraging by the honey-bee, Apis mellifera L. Funct. Ecol. 14, 490–496 (2000). Article Google Scholar Herrera-Granda, E. P., Torres-Cantero, J. C., Rosales, A. & Peluffo-Ordóñez, D. H. A comparison of monocular visual SLAM and visual odometry methods applied to 3D reconstruction. Appl. Sci. 13, 8837 (2023). Article CAS Google Scholar Sharafutdinov, D. et al. Comparison of modern open-source visual SLAM approaches. J. Intell. Robot. Syst. 107, 43 (2023). Article Google Scholar Degen, J. et al. Exploratory behaviour of honeybees during orientation flights. Anim. Behav. 102, 45–57 (2015). Article Google Scholar Capaldi, E. A. & Dyer, F. C. The role of orientation flights on homing performance in honeybees. J. Exp. Biol. 202, 1655–1666 (1999). Article CAS PubMed Google Scholar Capaldi, E. A. et al. Ontogeny of orientation flight in the honeybee revealed by harmonic radar. Nature 403, 537–540 (2000). Article ADS CAS PubMed Google Scholar de Croon, G. C. H. E., De Clercq, K. M. E., Ruijsink, R., Remes, B. & de Wagter, C. Design, aerodynamics, and vision-based control of the DelFly. Int. J. Micro Air Veh. 1, 71–97 (2009). Article Google Scholar Ma, K. Y., Chirarattananon, P., Fuller, S. B. & Wood, R. J. Controlled flight of a biologically inspired, insect-scale robot. Science 340, 603–607 (2013). Article ADS CAS PubMed Google Scholar Ferrera, M., Eudes, A., Moras, J., Sanfourche, M. & Le Besnerais, G. OV2SLAM: a fully online and versatile visual SLAM for real-time applications. IEEE Robot. Autom. Lett. 6, 1399–1406 (2021). Article Google Scholar Bavle, H., De La Puente, P., How, J. P. & Campoy, P. VPS-SLAM: visual planar semantic SLAM for aerial robotic systems. IEEE Access 8, 60704–60718 (2020). Article Google Scholar Boal, J., Sánchez-Miralles, A. & Arranz, A. Topological simultaneous localization and mapping: a survey. Robotica 32, 803–821 (2014). Article Google Scholar Garcia-Fidalgo, E. & Ortiz, A. Vision-based topological mapping and localization methods: a survey. Robot. Auton. Syst. 64, 1–20 (2015). Article Google Scholar Khan, M. A. & Labrosse, F. Visual topological mapping using an appearance-based location selection method. In Proc. Annual Conference Towards Autonomous Robotic Systems (eds Mohammad, A., Dong, X. & Russo, M.) 90–102 (Springer, 2020). Niculescu, V., Polonelli, T., Magno, M. & Benini, L. Nanoslam: enabling fully onboard slam for tiny robots. IEEE Internet Things J. 11, 13584–13607 (2023). Article Google Scholar Webb, B. The internal maps of insects. J. Exp. Biol. 222, jeb188094 (2019). Article PubMed Google Scholar Wehner, R. & Wehner, S. Insect navigation: use of maps or Ariadne’s thread? Ethol. Ecol. Evol. 2, 27–48 (1990). Article Google Scholar Cartwright, B. A. & Collett, T. S. How honey bees use landmarks to guide their return to a food source. Nature 295, 560–564 (1982). Article ADS Google Scholar Stone, T. et al. An anatomically constrained model for path integration in the bee brain. Curr. Biol. 27, 3069–3085 (2017). Article CAS PubMed PubMed Central Google Scholar Denuelle, A. & Srinivasan, M. V. A sparse snapshot-based navigation strategy for UAS guidance in natural environments. In Proc.2016 IEEE International Conference on Robotics and Automation (ICRA) 3455–3462 (IEEE, 2016). Franz, M. O., Schölkopf, B., Mallot, H. A. & Bülthoff, H. H. Where did I take that snapshot? Scene-based homing by image matching. Biol. Cybern. 79, 191–202 (1998). Article Google Scholar Stürzl, W. & Mallot, H. A. Efficient visual homing based on Fourier transformed panoramic images. Robot. Auton. Syst. 54, 300–313 (2006). Article Google Scholar van Dijk, T., De Wagter, C. & de Croon, G. C. H. E. Visual route following for tiny autonomous robots. Sci. Robot. 9, eadk0310 (2024). Article PubMed Google Scholar Baddeley, B., Graham, P., Husbands, P. & Philippides, A. A model of ant route navigation driven by scene familiarity. PLoS Comput. Biol. 8, e1002336 (2012). Article ADS CAS PubMed PubMed Central Google Scholar Zhu, L., Mangan, M. & Webb, B. Neuromorphic sequence learning with an event camera on routes through vegetation. Sci. Robot. 8, eadg3679 (2023). Article PubMed Google Scholar Collett, T. S. & Collett, M. Path integration in insects. Curr. Opin. Neurobiol. 10, 757–762 (2000). Article CAS PubMed Google Scholar Wehner, R. Desert ant navigation: how miniature brains solve complex tasks. J. Comp. Physiol. A 189, 579–588 (2003). Article ADS CAS Google Scholar Wystrach, A., Mangan, M. & Webb, B. Optimal cue integration in ants. Proc. R. Soc. B 282, 20151484 (2015). Article PubMed PubMed Central Google Scholar Lambrinos, D., Möller, R., Labhart, T., Pfeifer, R. & Wehner, R. A mobile robot employing insect strategies for navigation. Robot. Auton. Syst. 30, 39–64 (2000). Article Google Scholar Dupeyroux, J., Serres, J. R. & Viollet, S. AntBot: a six-legged walking robot able to home like desert ants in outdoor environments. Sci. Robot. 4, eaau0307 (2019). Article PubMed Google Scholar Wang, Z., Qu, J. & Morin, P. Airflow-based odometry for MAVs using thermal anemometers. Int. J. Micro Air Veh. 15, 17568293221148385 (2023). Article Google Scholar Stankiewicz, J. & Webb, B. Using the neural circuit of the insect central complex for path integration on a micro aerial vehicle. In Proc.Conference on Biomimetic and Biohybrid Systems (eds Vouloutsi, V. et al.) 325–337 (Springer, 2020). Ardin, P., Peng, F., Mangan, M., Lagogiannis, K. & Webb, B. Using an insect mushroom body circuit to encode route memory in complex natural environments. PLoS Comput. Biol. 12, e1004683 (2016). Article ADS PubMed PubMed Central Google Scholar Möller, R. Insect visual homing strategies in a robot with analog processing. Biol. Cybern. 83, 231–243 (2000). Article PubMed Google Scholar Zeil, J., Boeddeker, N. & Stürzl, W. in Flying Insects and Robots (eds Floreano, D., Zufferey, J. C., Srinivasan, M. & Ellington, C.) 87–100 (Springer, 2010). Kendall, A., Grimes, M. & Cipolla, R. PoseNet: a convolutional network for real-time 6-DOF camera relocalization. In Proc. IEEE International Conference on Computer Vision 2938–2946 (IEEE, 2015). Chen, C., Wang, B., Lu, C., Trigoni, N. & Markham, A. Deep learning for visual localization and mapping: a survey. IEEE Trans. Neural Netw. Learn. Syst. 35, 17000–17020 (2023). Article Google Scholar Lochner, S., Honerkamp, D., Valada, A. & Straw, A. D. Reinforcement learning as a robotics-inspired framework for insect navigation: from spatial representations to neural implementation. Front. Comput. Neurosci. 18, 1460006 (2024). Article PubMed PubMed Central Google Scholar Wystrach, A. Neurons from pre-motor areas to the mushroom bodies can orchestrate latent visual learning in navigating insects. Preprint at bioRxiv https://doi.org/10.1101/2023.03.09.531867 (2023). Gattaux, G. G., Serres, J. R., Ruffier, F. & Wystrach, A. Visual homing in outdoor robots using mushroom body circuits and learning walks. In Proc. 14th International Conference on Biomimetic and Biohybrid Systems: Living Machines 2025 (eds Jiménez Rodríguez, A. et al.) 456–468 (Springer, 2025). Firlefyn, M. V. M., Hagenaars, J. J. & De Croon, G. C. H. E. Direct learning of home vector direction for insect-inspired robot navigation. In Proc. 2024 IEEE International Conference on Robotics and Automation (ICRA) 6022–6028 (IEEE, 2024). Delmerico, J. & Scaramuzza, D. A benchmark comparison of monocular visual-inertial odometry algorithms for flying robots. In Proc. 2018 IEEE International Conference on Robotics and Automation (ICRA) 2502–2509 (IEEE, 2018). Heinze, S., Narendra, A. & Cheung, A. Principles of insect path integration. Curr. Biol. 28, R1043–R1058 (2018). Article CAS PubMed PubMed Central Google Scholar Wang, Z., Chen, X., Okada, R., Walter, S. & Menzel, R. Encoding and decoding of the information in the honeybee waggle dance. Behav. Ecol. Sociobiol. 79, 53 (2025). Article Google Scholar SvatÝ, Z. et al. Impact analysis assessment of UAS collision with a human body. PLoS One 20, e0320073 (2025). Article PubMed PubMed Central Google Scholar Srinivasan, M. V., Zhang, S., Altwein, M. & Tautz, J. Honeybee navigation: nature and calibration of the “odometer”. Science 287, 851–853 (2000). Article ADS CAS PubMed Google Scholar von Frisch, K. The Dance Language and Orientation of Bees (Harvard Univ. Press, 1993). Esch, H. E. & Burns, J. E. Distance estimation by foraging honeybees. J. Exp. Biol. 199, 155–162 (1996). Article CAS PubMed Google Scholar Menzel, R. & Galizia, C. G. Landmark knowledge overrides optic flow in honeybee waggle dance distance estimation. J. Exp. Biol. 227, jeb248162 (2024). Article PubMed PubMed Central Google Scholar Wehner, R. & Menzel, R. Do insects have cognitive maps? Annu. Rev. Neurosci. 13, 403–414 (1990). Article CAS PubMed Google Scholar Cartwright, B. A. & Collett, T. S. Landmark maps for honeybees. Biol. Cybern. 57, 85–93 (1987). Article Google Scholar Stürzl, W., Zeil, J., Boeddeker, N. & Hemmi, J. M. How wasps acquire and use views for homing. Curr. Biol. 26, 470–482 (2016). Article PubMed Google Scholar Dewar, A. D. M., Philippides, A. & Graham, P. What is the relationship between visual environment and the form of ant learning-walks? An in silico investigation of insect navigation. Adapt. Behav. 22, 163–179 (2014). Article Google Scholar Thrun, S., Burgard, W. & Fox, D. Probabilistic Robotics (MIT Press, 2005). Zhou, Z. et al. Towards building AI-CPS with NVIDIA Isaac Sim: an industrial benchmark and case study for robotics manipulation. In Proc. 46th International Conference on Software Engineering: Software Engineering in Practice 263–274 (ACM, 2024). Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. Int. J. Robot. Res. 5, 90–98 (1986). Article Google Scholar Meier, L., Honegger, D. & Pollefeys, M. PX4: a node-based multithreaded open source robotics framework for deeply embedded platforms. In Proc. 2015 IEEE International Conference on Robotics and Automation (ICRA) 6235–6240 (IEEE, 2015). Berganski, C., Hoffmann, A. & Möller, R. Tilt correction of panoramic images for a holistic visual homing method with planar-motion assumption. Robotics 12, 20 (2023). Article Google Scholar Natraj, A., Ly, D. S., Eynard, D., Demonceaux, C. & Vasseur, P. Omnidirectional vision for UAV: applications to attitude, motion and altitude estimation for day and night conditions. J. Intell. Robot. Syst. 69, 459–473 (2013). Article Google Scholar Szegedy, C. et al. Going deeper with convolutions. In Proc. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 1–9 (Curran Associates, 2015). Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. CBAM: Convolutional Block Attention Module. In Proc. European Conference on Computer Vision (ECCV 2018) (eds Ferrari V., Hebert, M., Sminchisescu, C. & Weiss, Y.) 3–19 (Springer, 2018). Zeil, J., Kelber, A. & Voss, R. Structure and function of learning flights in bees and wasps. J. Exp. Biol. 199, 245–252 (1996). Article CAS PubMed Google Scholar Laubach, S. L. & Burdick, J. W. An autonomous sensor-based path-planner for planetary microrovers. In Proc. 1999 IEEE International Conference on Robotics and Automation 347–354 (IEEE, 1999). Download references We thank M. Mangan for reading and commenting on an earlier version of this manuscript. We are also grateful to S. Stroobants and E. van der Horst for their extensive help with resolving drone hardware issues, T. J. Singh and the MAVLab outdoor test crew for their assistance with the outdoor experiments and M. Yedutenko and the Delft Drone Initiative for lending their flight hall for the indoor experiments. Part of this project was financed by the Dutch Research Council (NWO) under grant number 20663 of the VICI personal grant programme and grant number NNWA.1292.19.298 of the Dutch Research Agenda (NWA). Micro Air Vehicle Laboratory, Department Control & Operations, Faculty of Aerospace Engineering, Delft University of Technology, Delft, The Netherlands Dequan Ou, Jesse J. Hagenaars, Maciej R. Jankowski, Michiel V. M. Firlefyn, Christophe De Wagter & Guido C. H. E. de Croon Experimental Zoology Group, Wageningen University, Wageningen, The Netherlands Florian T. Muijres Navigation Biology Group, Institute of Biology and Environmental Sciences, Carl von Ossietzky University of Oldenburg, Oldenburg, Germany Jacqueline Degen Search author on:PubMed Google Scholar Search author on:PubMed Google Scholar Search author on:PubMed Google Scholar Search author on:PubMed Google Scholar Search author on:PubMed Google Scholar Search author on:PubMed Google Scholar Search author on:PubMed Google Scholar Search author on:PubMed Google Scholar All authors contributed to the conception of the study and the analysis and interpretation of the results. M.V.M.F. performed the early proof-of-concept simulation studies under the guidance of G.C.H.E.d.C. and J.J.H. G.C.H.E.d.C. performed the theoretical and simulation analysis in the Supplementary Information. The visual simulation experiments were developed and performed by M.J., J.J.H., D.O. and G.C.H.E.d.C. The neural networks used for visual learning and homing were developed by D.O., who also built the robot, developed the code, performed the real-world robotic experiments and analysed the data, with support from J.J.H., G.C.H.E.d.C. and C.D.W. Biological data were provided by J.D. Furthermore, F.T.M. and J.D. provided insights into the biological reanalysis. D.O. performed the reanalysis of the biological data. The manuscript was primarily written by G.C.H.E.d.C. and D.O., and the illustrations were made by D.O., G.C.H.E.d.C. and C.D.W. All authors contributed critically to the drafts and gave final approval for publication. Correspondence to Guido C. H. E. de Croon. The authors declare no competing interests. Nature thanks Barbara Webb and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available. Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. a, Isometric view of the drone, highlighting the omnidirectional camera (④), F9P GPS module (③) and the Raspberry Pi 4 onboard computer and Pixhawk 6C Mini flight controller housed in the main body (⑥ and ⑤, respectively). b, Bottom view showing the PMW3901 optical flow sensor (①) and the TFmini-S LiDAR sensor (②). c, System architecture diagram illustrating the data flow between sensors, the flight controller and the onboard computer. a, The lightweight compact network, a sequential model with four convolutional layers and one fully connected layer. The diagram specifies the kernel size, stride and channel depth for each layer. This model, with a total of 868 parameters (3.4 kB), was used in most experimental environments. b, The attention network, a deeper model with 10,820 parameters (42.3 kB), was used for the challenging, large and open outdoor environment. The main diagram shows the overall data flow and the inset provides a detailed view of the multibranch Inception module, which includes the spatial attention mechanism. a, The preprocessing pipeline. The raw image taken by the omnidirectional camera is masked, unwrapped and further resized to a format that fits the input size of the neural networks. b, Virtual rotation. The preprocessed images are virtually rotated to simulate the view seen when facing different headings, despite only one image being physically taken. This is achieved by cyclically shifting the image content horizontally (moving part of the image from left to right or vice versa). c, Colour augmentation. Each virtually rotated image is duplicated and augmented with a random brightness factor sampled from U(0.9, 1.1) and a contrast factor sampled from U(−10, 10). d, Wind correction. When wind affects the drone, the resulting tilt during image capture leads to artefacts in the preprocessed image. This is corrected by adjusting the centre position of the rectilinear unwarping. The new centre is obtained either by detecting the horizon line (dashed orange line) or by a model-based method that calculates the required centre shift using the pitch and roll measured by the drone at the moment of capture. a, The learning flight trajectory during one of the CyberZoo experiments. The solid line shows the ground-truth position captured by the OptiTrack motion capture system, serving as a reference. The dashed line shows the odometry position estimation (path integration). The inset highlights one of the learning points in which an image is captured and the corresponding odometry information is used for labelling. The direction of the arrows indicates the heading direction. The drift (red) illustrates the discrepancy between the noisy odometry estimate (orange) and the ground truth (blue). b, The odometry information is used to generate the label for the image captured at this location relative to the estimated home position (orange star). Owing to drift, this introduces noise to the label compared with the ‘correct’ label based on the true relative home location (blue star). The 2D label is generated by performing matrix multiplication using the heading and the current position relative to home. The magnitude of this label represents the distance between the current position and the home location, whereas the arctan of the label represents the desired angle to turn from the current heading to face home. a, Eight homing trajectories (blue lines) starting at different locations with varying headings (black arrows), reaching home (black star in the middle) using outputs (orange arrows) predicted by the compact network trained offline, offboard. The inset shows the first four steps of one of the homing trajectories. b, A detailed description of how the output (hpred) is used to obtain the control command (∆ψdrone and s). The arctan of the output is used to determine the heading change ∆ψdrone relative to the current heading to face home. The magnitude of the output predicts the distance from the current position to home and is used to determine the step size s for the drone to move forward along this heading. a, The CyberZoo flying arena at TU Delft (10 × 10 m) equipped with an OptiTrack motion capture system for ground-truth validation. b, The Delft Drone Initiative flight hall, a small indoor area (30 × 25 m) with consistent visual features. c,d, The indoor hangar at Unmanned Valley, Valkenburg, configured as a large indoor area with obstacles (30 × 40 m) (c) and without obstacles (d) to test navigation in cluttered versus open spaces. e, An outdoor tennis/football field (35 × 20 m), representing a small outdoor area enclosed by trees, providing distinct peripheral visual cues. f, The open test field at Unmanned Valley, Valkenburg, representing a large outdoor area (400 × 500-m permissible flight area) with natural terrain and a distant horizon, in which accurate GPS ground truth can be obtained. Several objects (a laid-down orange pole and two large features on the ground) were placed on the ground to provide landmarks in the surroundings of the home location. Although the omnidirectional camera could only see these features from some distance owing to the narrow field of view, these objects provided enough information for homing. The figure shows trajectories for each of the 30–110-m flights in four different environments. Each plot shows the robot’s learning flight (dark grey), the outbound phase (teal), followed by the inbound phase (orange) and the final visual homing phase (red) of the foraging flight. Trajectories are plotted using onboard odometry. All of the flights successfully ended up within 0.5 m around the home. For visualization purposes, trajectories based on odometry have been globally translated so that their final recorded point aligns with the true home position (0, 0), correcting for accumulated drift to accurately reflect the successful homing. Inset boxes provide quantitative metrics, including total distance and average velocity, for each phase of the flight. The figure shows trajectories for each of the 200–600-m flights in the 400 × 500-m Unmanned Valley, Valkenburg test field. Each plot shows the robot’s learning flight (dark grey), the outbound phase (teal), followed by the inbound phase (orange) and the final visual homing phase (red) of the foraging flight. Trajectories are plotted using high-precision GPS data. Three flights (marked as ‘Failed’ in red) did not successfully reach home owing to the challenging conditions in the large outdoor field. The flight in j reached 0.5 m within the home area, whereas the GPS data were slightly drifted. Inset boxes provide quantitative metrics, including total distance and average velocity, for each phase of the flight. This file contains Supplementary Sections 1–14 including Supplementary Figs. 1–33 and additional references. Visual learning and homing in CyberZoo. This video demonstrates the experimental procedure for the visual learning and homing components of the Bee-Nav system within a controlled indoor environment (10 × 10-m CyberZoo). The experiment begins with a learning flight, in which the drone autonomously collects training images and simultaneously trains a ‘compact’ neural network online using its onboard Raspberry Pi 4. To provide a comprehensive comparison, we also use the gathered data to train two network architectures (compact and attention) offline, both on a laptop and on the onboard Raspberry Pi 4. Furthermore, a separate learning flight is performed to train an ‘attention’ network onboard in real time. Following the training phase, all six resulting models are deployed to the drone for evaluation. The video showcases the homing performance tests, in which the drone is initialized at eight distinct starting positions along the perimeter with random initial headings. A homing attempt is classified as successful if the drone navigates back to the central home location. For brevity, this demonstration highlights the performance of the six models from two representative starting locations. As the test space is limited, the entire arena serves as the LHA, focusing this experiment exclusively on the visual learning and precision homing capabilities of the system. Visual learning and full-flight indoor tests. This video demonstrates the complete, multistage flight pipeline of Bee-Nav in a large indoor hangar (30 × 40 m), a GPS-denied environment. The experiment begins with the drone performing a learning flight to establish a 10 × 10-m LHA. Following offboard training and deployment of the neural network, the drone executes five consecutive trials. Each trial consists of a preplanned outbound flight, a direct inbound return to the estimated home position using onboard odometry and the final visual homing phase guided by the neural network. The video presents a multipanel view during the homing phase, showing the flight trajectory plot alongside third-person and onboard camera views. Visual learning and outdoor flight test under windy conditions. This video demonstrates the performance of Bee-Nav in a challenging outdoor test field with substantial wind (5–10 m s−1). The experiment begins with the drone performing a learning flight to establish a 15 × 15-m LHA. After the network is trained and deployed, the drone executes a long-distance, 120-m preplanned outbound flight. On completion, it performs an inbound return flight using onboard odometry, followed by the final visual homing phase to reach the starting location. The video includes a real-time plot comparing the GPS ground truth with the onboard odometry of the drone, visually demonstrating the notable drift that the visual homing system successfully overcomes. Visual learning and long-distance (600-m) outdoor flight test. This video demonstrates the performance of Bee-Nav over a long-distance trajectory in an open outdoor test field. The experiment begins with the drone performing a learning flight to establish a 15 × 15-m LHA. After the network is trained and deployed, the drone executes a 500-m (odometry distance) preplanned outbound flight. On completion, it performs an inbound return using onboard odometry, followed by the final visual homing phase to reach the starting location. The video includes a real-time plot comparing the GPS ground truth (that shows the actual outbound distance of more than 600 m) with the onboard odometry of the drone, visually demonstrating the notable drift that accumulates over long distances, which the visual homing system must successfully overcome. Visual learning and homing in CyberZoo with obstacles inside. This video demonstrates the experimental procedure for the visual learning and homing components of the Bee-Nav system within a controlled indoor environment (10 × 10 m, CyberZoo) that has been augmented with static obstacles. The experiment begins with a learning flight, in which the drone autonomously collects training images while actively navigating around obstacles. Following this flight, a compact neural network is trained offline on a laptop and the resulting model is deployed to the drone. The video then showcases the homing evaluation, in which the drone is initialized at eight distinct starting positions with random initial headings. During homing, the drone uses the output of the network to navigate towards the centre in discrete steps; however, whenever an obstacle is detected in the intended path, the obstacle-avoidance logic overrides the navigation command to ensure safety. A homing attempt is classified as successful if the drone navigates back to the central home location. Given the limited test space, the entire arena serves as the LHA, focusing this experiment exclusively on the system’s visual learning and precision homing capabilities in the presence of obstacles. Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. Reprints and permissions Ou, D., Hagenaars, J.J., Jankowski, M.R. et al. Efficient robot navigation inspired by honeybee learning flights. Nature (2026). https://doi.org/10.1038/s41586-026-10461-3 Download citation Received: 18 August 2025 Accepted: 30 March 2026 Published: 13 May 2026 Version of record: 13 May 2026 DOI: https://doi.org/10.1038/s41586-026-10461-3 Anyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Provided by the Springer Nature SharedIt content-sharing initiative Advertisement Nature (Nature) ISSN 1476-4687 (online) ISSN 0028-0836 (print) © 2026 Springer Nature Limited Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.
Images (10): 
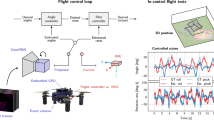
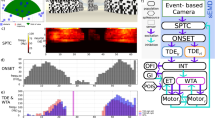

|
|||||
| Hong Kong pins focus on life sciences, embodied intelligence in … | http://www.ecns.cn/china/2026-05-13/det… | 10 | May 14, 2026 00:00 | active | |
Hong Kong pins focus on life sciences, embodied intelligence in AI pushURL: http://www.ecns.cn/china/2026-05-13/detail-ihfenirv8001478.shtml Content:
Hong Kong will establish a committee on AI+ and industry development strategy to formulate strategies for driving industrial transformation through AI, with initial focus on life and health technology and embodied intelligence, John Lee, chief executive of the Hong Kong Special Administrative Region (HKSAR), said on Tuesday. Addressing the first Hong Kong embodied AI industry summit, Lee highlighted the role of embodied AI in promoting industrial upgrading and fostering new quality productive forces, adding that Hong Kong welcomes enterprises to set up operations here to leverage the city's strengths and accelerate technological upgrading. Lee said that the Hong Kong Artificial Intelligence Research and Development Institute is set to commence operations in the second half of the year, with the aim of boosting AI research and development, facilitating the commercialization of research outcomes, and expanding real-world application scenarios. The institute will launch an AI technology matching platform, providing industry demand with solutions to speed up commercialization and empower industrial development, Lee added. Also speaking at the summit, Frederick Ma, chairman of the Hong Kong Trade Development Council, stressed that Hong Kong boasts unique strengths of internal integration and external connectivity as well as openness and inclusiveness, making it an optimal platform for mainland innovation and tech enterprises to expand into global markets. The summit, co-hosted by the Hong Kong China Friendship Association and robotics firm AGIBOT, aims to forge a platform for exchanges and cooperation for Hong Kong's embodied AI sector, as well as build the city into a global hub for embodied AI. 2026 World Digital Education Conference: how AI drives educational transformation International Healthcare Week opens in Hong Kong, fueling healthcare breakthroughs
Images (10): 




|
|||||
| SoftBank targets $100B IPO for AI robotics venture Roze (SFTBY:OTCMKTS) | https://seekingalpha.com/news/4582464-s… | 0 | May 13, 2026 08:00 | active | |
SoftBank targets $100B IPO for AI robotics venture Roze (SFTBY:OTCMKTS)URL: https://seekingalpha.com/news/4582464-softbank-targets-100b-ipo-for-ai-robotics-venture-roze Description: SoftBank plans Roze, an AI robotics firm to automate data center construction, eyeing a $100B U.S. IPO. Content: |
|||||
| SoftBank eyes listing new AI and robotics firm Roze in … | https://www.cnbc.com/2026/04/30/softban… | 10 | May 13, 2026 08:00 | active | |
SoftBank eyes listing new AI and robotics firm Roze in the U.S., FT reportsURL: https://www.cnbc.com/2026/04/30/softbank-roze-ai-robotics-ipo-100-billion-ft-report.html Description: SoftBank Group is planning to create and list a standalone artificial intelligence and robotics company, coined "Roze" in the U.S. Content:
SoftBank Group is planning to create and list a standalone artificial intelligence and robotics company in the U.S. as early as this year, the Financial Times reported on Thursday. The new entity, to be called "Roze," will focus on building data centers and using robotics to improve the efficiency of AI infrastructure construction, according to the report, which cited anonymous sources familiar with the matter. SoftBank founder and Chief Executive Masayoshi Son is driving the effort, with executives reportedly targeting a valuation of about $100 billion and aiming to pursue the initial public offering this year. However, the report noted that the valuation target and timeline could shift and that the plans are considered ambitious by some SoftBank executives, in part due to uncertainties stemming from the conflict in the Middle East. Son's AI risk appetite has been growing in recent years, with tens of billions of dollars committed to the sector. Investors, however, have raised concerns about how SoftBank will fund those investments, particularly its backing of OpenAI, which remains unprofitable. The proposed listing could help offset some of the major pledges, including more than $30 billion committed to OpenAI. Roze could also reportedly bundle existing energy, land and infrastructure assets from SoftBank's portfolio, as well as ABB Robotics, which SoftBank agreed to buy last year. ABB Robotics is one of the world's leading suppliers of robotics and machine automation solutions, and SoftBank is expected to integrate its robotics hardware with AI capabilities. SoftBank representatives did not immediately respond to a request for comment from CNBC. Son's AI ambitions have increasingly centered on the U.S., with the firm already positioning itself as a major financier of American AI infrastructure. At the start of last year, SoftBank partnered with OpenAI, Oracle and others on the Stargate project, a planned $500 billion investment to build AI data center capacity across the country. The conglomerate has also been working quickly to build its own data centers, including a large-scale project in Ohio. SoftBank posted a $2.4 billion gain in its Vision Fund in the December quarter as gains tied to its OpenAI investment helped offset losses in some of its other bets. The firm was trading 0.9% lower on Thursday and is up more than 18% this year. Got a confidential news tip? We want to hear from you. Sign up for free newsletters and get more CNBC delivered to your inbox Get this delivered to your inbox, and more info about our products and services. © 2026 Versant Media, LLC. All Rights Reserved. A Versant Media Company. Data is a real-time snapshot *Data is delayed at least 15 minutes. Global Business and Financial News, Stock Quotes, and Market Data and Analysis. Data also provided by
Images (10): 


|
|||||
| SoftBank Maps Out $100 Billion Robotics Spinoff | https://finance.yahoo.com/sectors/techn… | 2 | May 13, 2026 08:00 | active | |
SoftBank Maps Out $100 Billion Robotics SpinoffDescription: Softbank is planning to bundle a bouquet of existing bets together into a new venture at the intersection of AI and robotics. Content:
Oops, something went wrong Concerned about an AI bubble? Sign up for The Daily Upside for smart and actionable market news, built for investors. Every rose has its thorn, and SoftBank’s unwieldy portfolio of AI investments is starting to feel a bit prickly. Masayoshi Son’s solution? Bundle a bouquet of existing SoftBank bets together into a new venture that exists at the intersection of AI and robotics, name it Roze AI, and take it public sometime in the next seven to 19 months, according to a Financial Times report last week. Sign up for The Daily Upside at no cost for premium analysis on all your favorite stocks. READ ALSO: Forget Eggs. Tomato Prices Swell as Inflation Hits Three-Year High and Is Boeing’s Massive China Order Finally Close to Landing? Just about everyone in the AI world sees so-called “physical AI” as the next great frontier; at the Consumer Electronics Show earlier this year, Nvidia CEO Jensen Huang famously declared that robots were about to have their “ChatGPT moment.” For SoftBank, Roze AI would represent a critical move to both catch the next AI wave and reduce exposure to the data center infrastructure and frontier model-making it has thus far invested in heavily. Per the FT, key SoftBank lieutenants are growing wary of the company’s costly alliance with OpenAI, with the tens of billions of dollars the group has invested and loaned to the firm potentially weighing on its balance sheet. Launching Roze, at a valuation as high as $100 billion, might help ease some of the financial burden. The timing could be critical: To fund its AI investments, and bets on OpenAI in particular, SoftBank last month signed a $40 billion bridge loan, its largest-ever lending facility denominated solely in dollars, per Bloomberg. Meanwhile, The Wall Street Journal reported last week that SoftBank has considered selling its Intel stake to fund its investments; last year, it sold its $5.8 billion stake in Nvidia. Roze would feature many of SoftBank’s existing energy, land and infrastructure investments, sources told the WSJ, and would invest in the creation of robots that could, in turn, help with the massive buildout of data centers. Slice of Life: Yes, that’s robots running AI models created in data centers being used to build more data centers to train more AI models to … well, you get it. Historically, SoftBank’s interest in robots has ebbed and flowed. An early attempt to build a robot dubbed Pepper was canned in 2021, while Zume Pizza, the robot-operated pizzeria startup it backed, shuttered in 2023. But last year, the company agreed to buy ABB’s robotics business, which builds bots for industrial settings, for $5.4 billion; sources told the FT that once the deal closes, ABB could be a centerpiece for Roze. This post first appeared on The Daily Upside. To receive razor sharp analysis and perspective on all things finance, economics, and markets, subscribe to our free The Daily Upside newsletter. Sign in to access your portfolio
Images (2): 
|
|||||
| PYMNTS | SoftBank Planning $100 Billion US Robotics and AI … | https://www.pymnts.com/technology/2026/… | 7 | May 13, 2026 08:00 | active | |
PYMNTS | SoftBank Planning $100 Billion US Robotics and AI CompanyURL: https://www.pymnts.com/technology/2026/softbank-planning-100-billion-us-robotics-and-ai-company/ Content:
Japanese conglomerate SoftBank reportedly plans to create an American artificial intelligence (AI) and robotics company. Complete the form to unlock this article and enjoy unlimited free access to all PYMNTS content — no additional logins required. yesSubscribe to our daily newsletter, PYMNTS Today. By completing this form, you agree to receive marketing communications from PYMNTS and to the sharing of your information with our sponsor, if applicable, in accordance with our Privacy Policy and Terms and Conditions. Δ That’s according to a report Thursday (April 30) from the Financial Times (FT), which characterizes the venture, known as Roze, as part of SoftBank founder and CEO Masayoshi Son’s push to make his AI ambitions a reality. Roze could go public as early as this year, with SoftBank executives targeting a valuation that could reach $100 billion, the report added, citing sources familiar with the matter. These sources say Son wants to list this year to offset the multi-billion dollar funding pledges the company has made, including large commitments to OpenAI. Reached by PYMNTS, SoftBank declined to comment. SoftBank plans to hold an analyst day in a data center facility in Texas in July to promote the initial public offering (IPO), according to the same sources. Advertisement: Scroll to Continue However, the FT added, there are some within SoftBank who are doubtful about the valuation and the timeline for the listing, partly because of geopolitical and economic upheaval amid the U.S war on Iran. At the same time, U.S. markets could soon have to find space for three historically large IPOs, the report added: those of SpaceX, Anthropic and OpenAI. In related news, PYMNTS wrote recently about rising investor attention to physical AI and vertical AI startups, with venture funding focusing on firms building systems designed to operate in the physical world or automate specialized industry workflows. “The trend reflects a shift in the AI startup landscape away from general-purpose tools toward systems that can perform defined tasks in sectors such as robotics, healthcare, logistics and enterprise software,” that report said. Interest in physical AI has picked up amid debate about the role robotics could play in advancing artificial intelligence. Tesla CEO Elon Musk has argued that humanoid robots could chart a potential pathway toward artificial general intelligence, suggesting that machines that can interact with the physical world may accelerate progress in autonomy and reasoning. “While the claim remains speculative, funding patterns suggest investors are betting that AI systems connected to real-world environments could become a major frontier of innovation,” PYMNTS added. Meanwhile, another FT report from earlier this month said that nearly 40% of U.S. data center projects are in danger of falling behind schedule. The report, citing data from satellite and AI analytics group SynMax, said that 60% of projects scheduled for next year have not yet started construction. Industry executives interviewed by the FT said delays are due to problems related to permitting and local opposition, as well as labor, power and equipment shortages. SoftBank Planning $100 Billion US Robotics and AI Company Federal Paper Checks Face Stricter Limits Under Treasury Plan Amazon Tightens Grip on Seller Cash With Card Payment Overhaul Meta's Business AI Handling 10 Million Weekly Conversations Get PYMNTS Today, AI, B2B and more. We’re always on the lookout for opportunities to partner with innovators and disruptors.
Images (7): 


|
|||||
| Производство гуманоидного робота Tesla Optimus 3 начнется летом | http://upweek.ru/proizvodstvo-gumanoidn… | 1 | May 12, 2026 16:00 | active | |
Производство гуманоидного робота Tesla Optimus 3 начнется летомDescription: Глава компании Tesla Илон Маск в интервью на конференции Abundance Summit 11 марта 2026 года сообщил о сроках начала выпуска человекоподобного робота Optimus 3. По его словам, производство устройства намечено на лето текущего года, при этом первые партии будут немногочисленны и станут наращиваться по классической для производств S-образной кривой. Маск охарактеризовал новинку как наиболее совершенного Content:
Глава компании Tesla Илон Маск в интервью на конференции Abundance Summit 11 марта 2026 года сообщил о сроках начала выпуска человекоподобного робота Optimus 3. По его словам, производство устройства намечено на лето текущего года, при этом первые партии будут немногочисленны и станут наращиваться по классической для производств S-образной кривой. Маск охарактеризовал новинку как наиболее совершенного робота в мире, не имеющего аналогов среди существующих разработок. Optimus 3 станет третьей итерацией человекоподобного робота, разрабатываемого Tesla с 2022 года. Предыдущая версия Gen 2 демонстрировала возможности ходьбы со скоростью 0,6 метра в секунду, выполняла операции по сортировке элементов питания 4680 и оснащалась 22 степенями свободы в кистях рук, что позволяло манипулировать хрупкими предметами. Новая модель, согласно заявлениям Маска, получит качественно иной уровень искусственного интеллекта, позволяющий обучаться новым действиям посредством наблюдения за человеком, без необходимости программирования отдельных движений. В основе системы лежит фирменный бортовой компьютер FSD (Full Self-Driving) версии 15, адаптированный для задач встраиваемого интеллекта. Производственная стратегия Tesla в отношении роботов предусматривает поэтапное масштабирование. Первая сборочная линия мощностью до одного миллиона единиц в год будет развернута на заводе компании во Фримонте (Калифорния). Именно на этой площадке ожидается выпуск первых экземпляров Optimus 3. Одновременно компания готовит инфраструктуру для гораздо более крупного производства в Техасе: на территории гигафабрики Giga Texas уже ведутся подготовительные земляные работы под строительство отдельного предприятия, проектная мощность которого должна составить 10 миллионов роботов в год. Маск охарактеризовал будущие темпы развертывания как самые быстрые в истории для сложных промышленных изделий. Выход на действительно крупные объемы выпуска связывают уже со следующим поколением — Optimus 4. По словам Маска, его разработка должна завершиться в 2027 году, и именно эта версия будет производиться преимущественно в Техасе в значительно больших количествах. Глава Tesla также подтвердил намерение обновлять модельный ряд роботов ежегодно, добиваясь быстрого технического прогресса. Одним из ключевых барьеров для массового распространения Optimus остается стоимость. По оценкам аналитиков, благодаря использованию собственных приводов, вертикальной интеграции и эффекту масштаба, производственные расходы на одного робота могут быть снижены до 20 тысяч долларов. Это сопоставимо с ценой недорогого автомобиля и открывает перспективы использования таких машин не только в промышленности, но и в домашнем хозяйстве. Критически важной особенностью Optimus 3 называют полностью независимую цепочку поставок комплектующих. Tesla сознательно отказалась от использования готовых решений, доступных на рынке промышленной робототехники, и спроектировала все ключевые узлы — актюаторы, сенсоры, элементы питания и вычислительные модули — самостоятельно. Такой подход, основанный на «первых принципах», неизбежно удлиняет этап отладки производства и выхода на плановую мощность, но, по мнению руководства компании, позволит сохранить полный контроль над технологией в долгосрочной перспективе. Параллельно с физической версией робота, Tesla совместно с принадлежащей Маску компанией xAI разрабатывает программный продукт под названием Digital Optimus. Эта система, как пояснил предприниматель в социальной сети X, представляет собой «искусственный интеллект для офисного работника», способный выполнять рутинные операции за компьютером, наблюдая за действиями человека и повторяя их. Таким образом, стратегия Tesla в области автоматизации охватывает как физический труд, так и сферу интеллектуальной деятельности. Конкуренция на рынке человекоподобных роботов обостряется. Помимо китайских производителей, активность проявляют Boston Dynamics с коммерческой версией Atlas, Figure AI при поддержке Microsoft и OpenAI, а также Google DeepMind, предлагающий сторонним производителям базовую модель Gemini Robotics. На этом фоне успех Optimus будет зависеть не только от технического совершенства аппарата, но и от способности Tesla организовать его рентабельное массовое производство в ранее недостижимых для этой отрасли масштабах. Маск уже называл Китай единственным серьезным конкурентом в данной сфере. Глава компании Tesla Илон Маск в интервью на конференции Abundance Summit 11 марта 2026 года сообщил о сроках начала выпуска человекоподобного робота Optimus 3. По его словам, производство устройства намечено на лето текущего года, при этом первые партии будут немногочисленны и станут наращиваться по классической для производств S-образной кривой. Маск охарактеризовал новинку как наиболее совершенного робота в мире, не имеющего аналогов среди существующих разработок. Δ Для пресс-релизов и писем: news@upweek.ru
Images (1): 
|
|||||
| Tesla показала человекоподобного робота Optimus. Что он умеет? | https://tech.onliner.by/2022/10/01/tesl… | 1 | May 12, 2026 16:00 | active | |
Tesla показала человекоподобного робота Optimus. Что он умеет?URL: https://tech.onliner.by/2022/10/01/tesla-pokazala-chelovekopodobnogo-robota Description: Генеральный директор Tesla показал прототип человекоподобного робота Optimus, пишет The Guardian. Он вышел на сцену и помахал рукой сидящей публике. Как отметил Илон Маск, это первая такая самостоятельная и автономная прогулка аппарата. Далее был продемонстрирован небольшой ролик с другими Content:
Генеральный директор Tesla показал прототип человекоподобного робота Optimus, пишет The Guardian. Он вышел на сцену и помахал рукой сидящей публике. Как отметил Илон Маск, это первая такая самостоятельная и автономная прогулка аппарата. Далее был продемонстрирован небольшой ролик с другими возможностями робота: на нем он носит коробки, поливает растения и перемещает металлические прутья на заводе автопроизводителя. Optimus использует те же сенсоры, камеры и компьютер, которые отвечают за функцию автопилота в электромобилях Tesla. Он также самообучается. Встроенной батареи роботу хватает на сутки. Весит от 73 кг. Tesla Bot coming out and dancing @elonmuskpic.twitter.com/TKT1lSGyqa — Tesla Owners Silicon Valley (@teslaownersSV) October 1, 2022 — Главная цель — создание робота, который может заменить собой человеческую рабочую силу и использоваться на производстве и в быту, — заявил глава Tesla. Наш канал в Telegram. Присоединяйтесь! Есть о чем рассказать? Пишите в наш телеграм-бот. Это анонимно и быстро
Images (1): 
|
|||||
| Cette start-up valorisée à 14 milliards de dollars développe un … | https://infohightech.com/cette-start-up… | 0 | May 12, 2026 08:00 | active | |
Cette start-up valorisée à 14 milliards de dollars développe un « cerveau » pour tous les robots.Description: Et si tous les robots pouvaient fonctionner avec le même cerveau ? SoftBank veut le découvrir. Le 14 janvier, la startup de robotique Skild AI a levé 1,4 mil... Content: |
|||||
| Yahboom DOGZILLA-Lite: The First AI LLM Embodied Intelligence Robot Dog … | https://7gadgets.com/2025/11/24/yahboom… | 1 | May 12, 2026 08:00 | active | |
Yahboom DOGZILLA-Lite: The First AI LLM Embodied Intelligence Robot Dog for Raspberry Pi Education and Autonomous DevelopmentContent:
DOGZILLA-Lite is presented as the world’s first educational robot dog that seamlessly integrates multimodal large language models (LLM) with embodied intelligence. Built around a Raspberry Pi module, this advanced platform supports multiple AI visual functions, including face detection and sophisticated object recognition. DOGZILLA-Lite is more than just a walking robot; it is a true AI partner capable of understanding images, voices, environmental cues, and making complex autonomous decisions. The platform supports Robot Arm expansion, enabling the extension of a 3DOF robotic arm for autonomous object grasping and handling. It comes pre-programmed with a graphical user interface (GUI) system that includes built-in AI vision and voice programs. These programs unlock numerous exciting functions such as 3D object recognition, color identification, face and emotion recognition, and motion detection, providing endless possibilities for creative and educational projects. It should be noted that the robotic arm is designed to grasp standard EVA cubes and balls. Users benefit from Multiple Control Methods and real-time visual feedback. DOGZILLA-Lite can be easily controlled via the XGO APP and PC software, compatible with both Android and iOS devices. The robot dog can transmit real-time video images directly to the application, providing the user with an immersive first-person perspective control experience. The robot features highly advanced Gait Planning and free adjustment capabilities. DOGZILLA-Lite integrates inverse kinematics algorithms to accurately control the ground contact time, lift time, and lift height of each leg. Users can easily adjust these parameters to achieve different complex gaits. Detailed inverse kinematics analysis and the source code for these functions are provided for deeper learning. DOGZILLA-Lite is positioned not just as a toy, but as a ticket to the future of technology. Students can use it to understand core AI principles, developers and geeks can use it to create and test autonomous driving algorithms, and families can enjoy it as an interactive technology partner. Yahboom provides extensive technical support, including open-source data code for AI visual interaction, Open CV, and AI LLM development.
Images (1): 
|
|||||
| Naver to develop Arabic-based LLM, expand AI cooperation with Saudi … | https://en.yna.co.kr/view/AEN2024091300… | 1 | May 12, 2026 08:00 | active | |
Naver to develop Arabic-based LLM, expand AI cooperation with Saudi Arabia | Yonhap News AgencyURL: https://en.yna.co.kr/view/AEN20240913001200320?section=news&input=rss Description: SEOUL, Sept. 13 (Yonhap) -- Naver Corp., the operator of South Korea's largest intern... Content:
All Headlines North Korea Sports Top News Most Viewed Korean Newspaper Headlines Today in Korean History Yonhap News Summary Editorials from Korean Dailies URL is copied. SEOUL, Sept. 13 (Yonhap) -- Naver Corp., the operator of South Korea's largest internet platform, has signed an initial agreement with Saudi Arabia's artificial intelligence (AI) agency to jointly develop an Arabic language-based large language model (LLM), company officials said Friday. During the Global AI Summit hosted by the Saudi Data & AI Authority (SDAIA) in Saudi Arabia's capital of Riyadh earlier this week, Naver and the SDAIA signed the memorandum of understanding (MOU) to cooperate in various sectors, including AI, cloud computing, data centers and robots, according to the officials. Under the MOU, the two sides plan to jointly develop an Arabic LLM, and technology solutions and services in the fields. SDAIA has been leading the Middle Eastern nation's ambitious plan of creating a technology-driven economy by 2030. Last year, Naver also struck a deal with the Saudi Arabian government to create a digital twin platform for Riyadh and four other Saudi cities. Naver Corp.'s executives are seen attending the Global AI Summit in Riyadh, hosted by the Saudi Data & AI Authority, in this photo provided by the Korean company on Sept. 12, 2024. (PHOTO NOT FOR SALE) (Yonhap) nyway@yna.co.kr(END) All News National North Korea Economy/Finance Biz Culture/K-pop Sports Images Videos Top News Most Viewed Korean Newspaper Headlines Today in Korean History Yonhap News Summary Editorials from Korean Dailies Korea in Brief Useful Links Weather Advertise with Yonhap News Agency
Images (1): 
|
|||||
| Robots humanoïdes : la Chine montre en spectacle sa domination … | https://www.zdnet.fr/actualites/robots-… | 1 | May 12, 2026 08:00 | active | |
Robots humanoïdes : la Chine montre en spectacle sa domination in ...Description: Le Gala du Nouvel An lunaire a mis en scène des dizaines de robots humanoïdes capables de prouesses martiales. La Chine confirme ainsi son avance stratégique sur l'IA incarnée par des robots. Content:
Les dernières news Le Gala du Nouvel An lunaire a mis en scène des dizaines de robots humanoïdes capables de prouesses martiales. La Chine confirme ainsi son avance stratégique sur l'IA incarnée par des robots. Par Guillaume Serries 2 min En Chine, le gala annuel de la CCTV n'est plus seulement un rendez-vous culturel. Il est devenu un véritable baromètre de la politique industrielle de Pékin. Cette année, quatre startups — Unitree Robotics, Galbot, Noetix et MagicLab — ont occupé le devant de la scène, rapporte Reuters. Et derrière les chorégraphies et les démonstrations de "drunken boxing" robotique se cache une réalité économique brutale. La Chine a livré 90 % des 13 000 robots humanoïdes expédiés dans le monde l'année dernière. Et selon Morgan Stanley, les ventes d'humanoïdes sur le marché chinois devraient encore doubler cette année pour atteindre 28 000 unités. Un marché porté par des commandes publiques importantes et un accès facilité au marché pour les entreprises exposées lors de ce gala. Surtout, l'enjeu dépasse la performance technique. La stratégie "AI+" de la Chine vise à intégrer l'IA dans les robots pour compenser le vieillissement important de la population active chinoise. L'automatisation est donc devenu dans l'Empire du Milieu une nécessité de survie économique. Cette volonté politique se traduit par un soutien direct du sommet de l'État. Le fondateur d'Unitree a notamment été reçu par le président Xi Jinping, un signal fort envoyé aux investisseurs. L'année 2026 s'annonce donc comme celle de la maturité financière pour le secteur de la robotique en Chine, avec les introductions en bourse (IPO) attendues d'acteurs majeurs comme AgiBot et Unitree. Ces levées de fonds devraient accélérer le déploiement de ces machines dans les lignes d'assemblage des usines. De quoi transformer radicalement le quotidien des collaborateurs en entreprise de ces robots qui devront désormais cohabiter avec ces collègues de métal. C'est ce que l'on appelle la cobotique. Côté technologie, l'évolution récente la plus marquante réside dans les capacités de coordination multi-robots et la récupération après erreur ("fault recovery"). Ainsi, les robots ne se contentent plus de suivre une trajectoire préprogrammée. Ils utilisent des modèles d'IA pour adapter leur motricité fine en temps réel. Par ailleurs, l'expertise d'Unitree dans le développement du "cerveau" logiciel permet désormais d'envisager des tâches complexes en environnement industriel. Et cette avance technique commence à inquiéter les acteurs occidentaux. « Les gens en dehors de la Chine sous-estiment la Chine, mais la Chine est le prochain niveau du botteur de fesses » a ainsi poétiquement évoqué Elon Musk, le CEO de Tesla. Alors que l'Occident se concentre sur les modèles de langage (LLM), Pékin prend vraisemblablement de l'avance sur l'IA incarnée. Le véritable test pour les entreprises européennes et américaines sera de maintenir leur compétitivité face à une industrie chinoise capable de produire des robots sophistiqués à une échelle et un coût jusqu'ici inégalés. Le ZDNET Morning le brief de l'actu tech pour les pros tous les matins à 9h00. Transformation numérique, IA, matériel, logiciels,... ne passez pas à côté de ce qui fait la Une du secteur. Le Google Threat Intelligence Group révèle avoir détecté pour la première fois un code d'exploitation zero-day fonctionnel développé à l'aide de l'IA. Il constate une utilisation croissante de l'intelligence artificielle par des acteurs malveillants étatiques, notamment nord-coréens et chinois, et des groupes cybercriminels. En seulement quatre mois, NVIDIA a déployé plus de 40 milliards de dollars en capital-investissement. Un record absolu avec surtout un ticket de 30 milliards de dollars dans OpenAI. Plus qu'une diversification, le fondeur orchestre une intégration verticale qui interroge. La fermeture définitive de Digital College, annoncée pour le 31 mai 2026, marque le point final d'une dérive mêlant opacité financière et délitement des programmes. Pour les entreprises partenaires et les 3 000 étudiants, le préjudice touche à la crédibilité même des formations tech privées. L'année dernière, le mieux que l'on pouvait dire des créateurs de sites web basés sur l'IA, c'est qu'ils avaient du potentiel. Cette année, nous en avons trouvé certains qui sont réellement à la hauteur. L’appareil, associé à Alexa+, représente une nette amélioration par rapport à ses prédécesseurs, mais il n'est pas sans présenter certains inconvénients, en termes de confidentialité. Je ne suis pas programmeur, mais j'ai essayé quatre outils de Vibe coding pour voir si je pouvais créer quelque chose tout seul. Voici ce que j'ai réussi et ce que je n'ai pas réussi à faire. L’anneau est précisément un outil de prise de notes et d'organisation de la pensée alimenté par l'intelligence artificielle et à qui vous parlez quelque soit l'environnement. Surprenant. ChatGPT pour anticiper les questions, Gemini pour s'entraîner à voix haute, l'IA pour décrypter le profil de votre interlocuteur… Les outils d'intelligence artificielle s'imposent comme de nouveaux alliés dans la préparation aux entretiens d'embauche. Encore faut-il savoir s'en servir sans perdre ce qui fait la différence : l'authenticité. ChatGPT retient bien plus d’informations personnelles qu’on ne le croit. Quelques réglages simples suffisent pourtant à reprendre la main sur ses données. En employant des interactions entre le chatbot d’intelligence artificielle d’Anthropic et les services tiers comme TripAdvisor and AllTrails, voici un exemple de planification d’un voyage estival devant inclure de la marche sur les sentiers, l’hébergement en hôtel, des tours guidés et même la création d’une playlist devant nous accompagner. Des chefs d'entreprise expliquent pourquoi ils continuent à recruter pour des postes de débutants, comment ils investissent dans leurs employés et ce qui fonctionne jusqu'à présent Vous n’avez pas encore de compte ? Mentions légales | Conditions générales d'utilisation | Politique de protection des données personnelles | Cookies | Foire aux questions - Vos choix concernant l'utilisation de cookies | Paramétrer les cookies | Copyright © 2025 ZDNET ZDNET France is operated by CUP Interactive SAS (France) under license from Ziff Davis | ZDNET France est exploité par CUP Interactive SAS (France) sous licence de Ziff Davis.
Images (1): 
|
|||||
| Neura Robotics: Physical AI for Manufacturing | IIoT World | https://www.iiot-world.com/artificial-i… | 1 | May 12, 2026 00:00 | active | |
Neura Robotics: Physical AI for Manufacturing | IIoT WorldDescription: David Reger explains how Neura's 4NE1 humanoid robots address a 101 million worker shortage by 2030. AWS partnership scales physical AI for manufacturing. Content:
David Reger, founder and CEO of Neura Robotics, stood next to a 4NE1 Mini humanoid robot at the AWS booth during Hannover Messe 2026 and laid out the math: China, Japan, and Europe together face a deficit of 101 million workers by 2030. His company’s answer is a line of cognitive humanoid robots built to work in the same spaces and on the same tasks that human workers handle today. The same week, Neura and AWS announced a strategic partnership to scale physical AI from controlled lab environments to global manufacturing deployment. Physical AI humanoids perform the same manual tasks as human workers, including pressing buttons, turning switches, loading parts into machines, and sorting components into bins, all within existing factory layouts that were designed for people. The humanoid form factor is the key differentiator. Because the 4NE1 matches a human worker’s height and reach at 180 cm, it fits into production lines without requiring facility modifications. Current deployments start with straightforward, repetitive operations: placing parts inside machines, sorting components into baskets, and responding to changing conditions on the line. The distinction from traditional industrial robots is that these systems are fully autonomous and reactive. When something changes in the environment, the robot adapts without reprogramming. The manufacturing-grade 4NE1 Gen 3.5 lifts up to 100 kg, operates for six to eight hours on hot-swappable batteries that enable 24/7 operation, and processes its environment through seven cameras providing 360-degree perception along with a patented artificial skin that detects proximity. Neura targets precision assembly, quality inspection, palletizing, and machine tending across automotive and electronics manufacturing. Other humanoid deployments are already showing measurable production results at scale. Physical AI robots learn tasks through a combination of real-world sensor data and high-fidelity simulation, then share what they learn across an entire fleet through cloud infrastructure. The challenge is that while large language models train on trillions of internet data points, robots operate with far less available training material. The smaller 4NE1 Mini, standing at 132 cm with 25 degrees of freedom, serves as the training platform. Anything a research team builds or trains on the Mini transfers directly to the full-size manufacturing models. The AWS partnership announced at Hannover Messe addresses the infrastructure side of this problem. AWS becomes Neura’s primary cloud provider, hosting the Neuraverse platform for physical AI training, real-time data processing, and fleet intelligence sharing. Neura Gym, the company’s controlled training environment, integrates with Amazon SageMaker to accelerate training pipelines. Amazon is also exploring deployment of Neura robots across select fulfillment centers, creating one of the most advanced real-world environments for robotics at global scale. “Physical AI will only reach its full potential if intelligence can be trained, validated, and continuously improved in the real world,” according to the AWS partnership announcement. Major manufacturing economies face a combined 101 million worker deficit by 2030, according to David Reger. China accounts for 87 million of that deficit, while the EU and Japan are each projected to be short 7 million workers. The aging population across all three regions is driving the deficit, and industry surveys show 86% of manufacturers now treat AI and robotics as essential to sustaining output. Neura’s longer-term target goes beyond the tasks robots handle today. The capability still exclusive to humans is assembly of objects the robot has not encountered before, and that is what Neura is building toward. The company has set a target of delivering five million cognitive robots by 2030 and has raised 185 million euros to date, with a partner network that includes Kawasaki, Schaeffler, Bosch, Qualcomm Technologies, and now AWS. The 4NE1 Gen 3.5, designed in collaboration with Studio F.A. Porsche, is priced at 98,000 euros for individual orders and drops to 60,000 euros per unit for fleet purchases of 20 or more. Both models run on the NVIDIA Thor T5000 processor and the NVIDIA Isaac GR00T XX foundation model, with the Neuraverse operating system managing fleet-level coordination. Based on a video interview with David Reger, founder and CEO of Neura Robotics, recorded by Lucian Fogoros of IIoT World at the AWS booth during Hannover Messe 2026. Additional specifications from Neura Robotics public product documentation and the AWS-Neura partnership announcement of April 20, 2026. Neura Robotics is a German cognitive robotics company founded in 2019 and headquartered in Metzingen. The company develops humanoid robots for manufacturing, logistics, and personal use. CEO and founder David Reger coined the term “cognitive robotics.” Neura has raised 185 million euros and partners with AWS, Kawasaki, Schaeffler, Bosch, and Qualcomm Technologies. The 4NE1 Gen 3.5 handles precision assembly, quality inspection, palletizing, machine tending, pressing buttons, turning switches, and loading parts into machines. It lifts up to 100 kg, has 25+ degrees of freedom, and runs six to eight hours with hot-swappable batteries for continuous 24/7 operation. Physical AI robots are fully autonomous and reactive, adapting to changing conditions without reprogramming. Models trained on the smaller 4NE1 Mini transfer directly to the manufacturing-grade 4NE1 Gen 3.5. Fleet intelligence is shared across all robots through the cloud-based Neuraverse platform hosted on AWS. According to Neura Robotics CEO David Reger, major economies face a combined 101 million worker deficit by 2030: China 87 million, the EU 7 million, and Japan 7 million, driven by rapid population aging across all three regions. Co-Founder at IIoT World An entrepreneurial software engineer with global business leadership experience and a passion for digital transformation. Lucian has worked in the industrial software and automation industry since 1998. He holds a BSEE from Cleveland State University and an MBA in Entrepreneurial Finance from Case Western Reserve University. Figure AI’s humanoid robots completed an 11-month deployment at BMW’s Spartanburg plant, loading 90,000+ sheet metal parts across 1,250 operational… Traditional robotics were remarkable in doing one repetitive task, which helped industries to augment efficiency. But now they are not… The world of robotics is about to experience a revolution—and it’s not just any revolution. Think back to the breakthrough… © 2017-2026 IIoT World. All articles submitted by our contributors do not constitute the views, endorsements or opinions of IIoT-World.com. Free, full-day virtual conference, up to 8 live panels on autonomous AI, predictive maintenance, and industrial AI architecture.
Images (1): 
|
|||||
| Cognitive Science Events in India, List of all India Cognitive … | https://10times.com/india/cognitivescie… | 0 | May 12, 2026 00:00 | active | |
Cognitive Science Events in India, List of all India Cognitive Technology Business Expo & EventsURL: https://10times.com/india/cognitivescience Description: Explore a diverse array of events in IN. Find & compare, Reviews, Ratings, Timings, Entry Ticket Fees, Schedule, Calendar, Discussion Topics, Venue, Speakers, A... Content: |
|||||
| Hacking Embodied AI | https://www.recordedfuture.com/research… | 1 | May 11, 2026 16:00 | active | |
Hacking Embodied AIURL: https://www.recordedfuture.com/research/hacking-embodied-ai Description: Embodied AI, intelligent systems in physical forms such as humanoid and quadruped robots, is moving from spectacle to staffing plans. Content:
Embodied AI has arrived.. Humanoid and quadruped robots are moving off factory floors and into everyday operations, military deployments, and critical infrastructure. Technological advances in large language models LLMs and robotics are enabling robots to perform complex tasks autonomously. Security has not kept pace. Researchers have demonstrated that commercially available robots can be hijacked over Bluetooth, covertly exfiltrate audio, video, and spatial data to servers in China, and even infect neighboring robots wirelessly, forming physical botnets. If unaddressed, these security weaknesses are set to scale massively once humanoid robots are fully integrated into critical workflows. The risks need to be taken extremely seriously. A robot should be treated less like a machine on the balance sheet and more like a cyber-physical endpoint with cameras, microphones, radios, cloud dependencies, and motors. That means tougher procurement, tighter network controls, continuous vulnerability monitoring, and a credible plan for operational continuity if a fleet has to be pulled offline. Embodied AI, intelligent systems in physical forms such as humanoid and quadruped robots, is moving from spectacle to staffing plans. The shift is being driven as much by demographics as by technological progress. There are growing reports that the working-age population worldwide has begun to decline. China, an economic success story, has seen its population also decline again in 2025 as births hit a record low. These trends do not make large-scale automation inevitable, but they seriously strengthen the economic case for it in both corporate and government decision-making. The International Federation of Robotics identifies labor shortages, real-world testing of humanoid robots, and increasing attention to safety and cybersecurity as defining trends for 2026. Some early deployments of embodied AI reinforce this trajectory. BMW reports that the Figure 02 humanoid robot has assisted in the production of more than 30,000 X3 vehicles, while GXO and Agility Robotics describe their partnership (established in 2024) as “the first formal commercial deployment of humanoid robots.” In high-risk environments, Sellafield is deploying quadruped robots to reduce human exposure in nuclear decommissioning. Capital markets are also responding. Unitree filed for a reported $610 million initial public offering (IPO) in Shanghai in March 2026. Taken together, these signals suggest that robots are leaving pilot programs and becoming operational. That transition makes the security question immediate rather than theoretical. Unlike traditional IT assets, embodied AI systems combine multiple high-risk components in a single platform: cameras, microphones, sensors, wireless radios, cloud connectivity, and physical actuation. This convergence creates a broad and under-secured attack surface. A compromised robot can exfiltrate sensitive environmental and operational data, provide persistent remote access to internal networks, and interact physically with its environment, potentially causing unintended physical effects. This elevates robots from conventional endpoints to cyber-physical systems with both digital and real-world consequences. The risk is compounded by architectural choices. Many platforms rely on cloud-dependent telemetry, wireless provisioning interfaces, and centralized control mechanisms. These design decisions create multiple entry points for attackers and increase the likelihood of compromise across entire fleets of embodied AI systems. The risks are no longer theoretical. Documented vulnerabilities show that commercially available robots can be compromised with relative ease. Unlike traditional cyber threats, which mostly affect the digital world, exploiting robots enables attackers to manipulate the physical world, maximizing the potential for harm. In 2025, researchers discovered an undocumented backdoor in Unitree’s Go1 quadruped robot that enabled remote access via the CloudSail service. Axios reported that an exposed web application programming interface (API) could allow attackers to locate devices globally and, if a robot was online, view live camera feeds without authentication. Where default credentials remained unchanged, full device control was possible. Whether described as a backdoor or a design failure, the implication is the same: robots may be reachable in ways operators do not anticipate, just like any other Internet of Things (IoT) device. Further research disclosed a critical vulnerability in the Bluetooth Low Energy and Wi-Fi provisioning interface used by multiple Unitree models, including the Go2, B2, G1, R1, and H1 robots. According to both the UniPwn research and IEEE Spectrum, the flaw combined hard-coded cryptographic keys, trivial authentication bypass, and command injection in the Wi-Fi setup process. An attacker within radio range could obtain root-level access without physical contact, giving them control over the robot. Because the exploit propagates wirelessly, a single compromised device can enable lateral movement across nearby robots. This creates a fleet-level compromise scenario in which multiple units can be controlled simultaneously. The result resembles a physical botnet capable of both digital and physical actions. Surveillance risks are equally significant. Researchers wrote that the Unitree G1 robot continuously exfiltrated multimodal sensor and service-state telemetry every 300 seconds without the operator’s knowledge. This included streaming data to external servers, potentially including audio, video, and spatial mapping. A robot operating inside a plant or laboratory may therefore be mapping the environment in real time. The attack surface extends beyond firmware and networking layers. Researchers showed they could take control of a Unitree humanoid in about a minute, bypass its normal controller, and trigger physical actions. Demonstrations at GEEKCon in Shanghai indicated that both voice commands and short-range wireless exploits could hijack robots and propagate attacks to nearby units, including those not actively in use. At the software layer, embodied AI systems introduce additional risks due to their reliance on large vision-language models. Researchers demonstrated that physical-world text can influence system behavior, as injected visual prompts were shown to steer autonomous driving, drone landing, and tracking tasks without compromising the underlying software. This would enable threat actors to take control of a self-driving car or turn a drone into their own surveillance feed by embedding a visual prompt in the environment, such as hiding a message on a stop sign. The implications extend beyond individual devices to organizational and systemic risk. Embodied AI systems are already being deployed in environments where compromise has consequences beyond data loss. Manipulation or malfunction of robots during critical operations would have outsized economic or public safety consequences. Militaries are also experimenting with robotic systems (see Figure 4). In 2024, the Golden Dragon exercise between Cambodia and China featured robot dogs among the systems on display. Meanwhile, in the US, politicians have begun pushing for Unitree to be designated as a federal supply-chain risk, reflecting national security concerns about commercial robotics platforms. This is a very similar move to Poland’s ban on sensor-rich vehicles accessing military sites to limit surveillance risk. Ukraine has successfully deployed ground-based robots and drones in combat operations, marking a significant shift in modern warfare. In a landmark operation in April 2026, Ukrainian forces captured a Russian position using only unmanned systems — the first recorded instance of a robot-only assault in the conflict. As adoption scales, these risks become interconnected. A vulnerability affecting one platform or vendor could propagate across fleets, sites, or sectors, creating systemic exposure. At the same time, the pace of commercial development is outstripping regulatory oversight. Bank of America estimates that as many as three billion humanoid robots could be in operation by 2060. This convergence of demographic pressure, advancing AI capabilities, and falling production costs suggests that large-scale human-machine coexistence is highly probable. Figure 7: Summary of the factors fueling growth in robotics production, illustrated by Bank of America data (Source: Recorded Future) Securing embodied AI systems is therefore not a peripheral technical issue. It is a strategic requirement that must be addressed before widespread deployment locks in insecure architectures at scale. Table 1: Business risks associated with the adoption of insecure embodied AI systems (Source: Recorded Future) The mass-production surge: Established car manufacturers and tech giants are poised to accelerate their robotics ambitions, not only deploying robots on factory floors but increasingly manufacturing them at scale. As traditional vehicle sales potentially peak or decline due to demographic shifts, the expertise in mass production and complex assembly will almost certainly be repurposed to build robots. We should expect the bill-of-materials costs to continue their downward trend, meaning security features are increasingly marginalized in favor of market penetration. The inevitable breach: It is almost certain that we will see a major cyber-physical incident involving embodied AI in the next decade. This could take the form of large-scale operational downtime in a roboticized factory, a legal crisis arising from a hijacked robot causing human injury, or a high-profile case of industrial espionage involving a robot used to map a secret facility. The incident involving Ecovacs vacuums relaying obscenities and racial slurs from a remote hacker is an early indicator of how these risks may evolve. A new security industry: The next decade will likely see the rise of a dedicated industry focused on securing humanoid robots. Just as the PC era gave birth to antivirus software and the cloud era to SASE, the robotic era will require specialized firms that can provide "physical firewalling," behavioral motor-control monitoring, and "robot-specific" threat intelligence. Companies such as Periphery are examples of where the industry could be rapidly headed. Monitor and maintain a vulnerability register: Track disclosed vulnerabilities in any robotic platform your organization deploys or is considering. Establish a playbook for quickly patching or taking robots offline, and understand the operational downtime cost before, not after, a vulnerability is discovered. Recorded Future Vulnerability Intelligence can provide continuous monitoring of emerging CVEs and disclosures specific to embodied AI platforms. Communicate procurement risks to decision-makers: If your company is purchasing robotics for its operations, the risks of surveillance, covert data exfiltration, and remote compromise must be clearly documented and escalated to the board. Purchasing decisions based solely on unit cost, without accounting for tail risk, are not cost-effective. Interrogate manufacturers on security by design: Work as closely as possible with manufacturers to understand what security measures are built into the platform, what telemetry is collected, where it is routed, and how firmware updates are managed. If responses are unsatisfactory or opaque, treat that as a material factor in procurement. If the decision-makers' risk appetite remains high regardless, document it formally. Monitor the macro landscape continuously: New manufacturers are entering the market at a rapid pace, some with security as an afterthought. Recorded Future Threat Intelligence and Geopolitical Intelligence can assist organizations in tracking which companies are emerging, which have ties to state interests, and how the regulatory environment is shifting in key jurisdictions. Table 2: Mitigation strategies for business risks, with recommended ownership (Source: Recorded Future) Scenario: ACME Ltd manufactures high-grade munitions for a Western military and allied customers. To reduce human exposure to dangerous materials, it buys 100 humanoid robots from an overseas vendor. The chosen model is already used in comparable factories abroad and costs roughly half as much as an alternative sourced from the United States.
Images (1): 
|
|||||
| LG robots move boxes in 90 seconds with zero human … | https://interestingengineering.com/ai-r… | 1 | May 11, 2026 00:00 | active | |
LG robots move boxes in 90 seconds with zero human help in live testURL: https://interestingengineering.com/ai-robotics/humanoid-dog-like-robots-work-together-at-lg Description: LG demostrates autonomous humanoid and quadruped robots coordinating warehouse logistics without human control. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. The platform centrally manages humanoids, quadrupeds, AMRs, AGVs, and wheel-based robots through one interface. A subsidiary of LG has showcased a future logistics workflow in which multiple autonomous robots collaborate without human intervention. In a demonstration, a bipedal humanoid lifted a box from a conveyor belt and passed it to a wheeled quadruped transport robot, which autonomously delivered it across the site. A wheel-type humanoid then used its extended arms to place the box on a shelf over two meters high. The entire process was powered by LG CNS’s Physical Works platform, with robots independently recognizing objects, making decisions, and coordinating tasks using Robot Foundation Model technology. Recently, LG Display also unveiled a 7.2-inch curved P-OLED humanoid robot display powered by its third-generation Tandem OLED display technology. LG CNS showcased its PhysicalWorks robot transformation (RX) platform through a live logistics demonstration at its Magok campus in western Seoul. During the event, four robots from different manufacturers completed coordinated warehouse tasks without remote control. The platform combines a simulation and video-based robot training module with a real-time orchestration system capable of assigning and reassigning jobs across mixed-brand robot fleets, according to The Korea Herald (TKH). During the demonstration, a humanoid robot picked up packaged goods from a conveyor and loaded them into a box. A wheeled quadruped logistics robot then transported the box across the workspace to a wheeled humanoid robot, which stacked it on a designated shelf. After completing the delivery, the quadruped returned to continue the logistics cycle while the wheeled humanoid placed an empty box back onto the conveyor for refilling. LG CNS also demonstrated adaptive task management by simulating an emergency scenario. When the quadruped robot was reassigned to patrol operations, the platform automatically deployed another autonomous logistics robot to continue the transport work without interrupting the workflow, according to TKH. The company said the robots operated entirely autonomously, relying on the platform’s robot learning and coordination capabilities rather than manual intervention. In the live setup, the robots transferred a single box between stations positioned roughly two to three meters ((6.5 to 9.8 feet) apart in about 90 seconds, with performance expected to improve further through additional field training and operational experience. LG CNS said the robotics industry is shifting beyond hardware-focused development toward software systems that allow robots to understand, coordinate, and reliably execute real-world industrial tasks. The company believes successful robot transformation depends on integrated learning, verification, and operational frameworks tailored to manufacturing and logistics sites rather than on individual robot performance alone, reports Chosun Biz. To support this strategy, LG CNS has developed its Physical Works platform, which combines two systems: Physical Works Forge for robot data learning and simulation-based verification, and Physical Works Baton for centralized control of robots from multiple manufacturers. The platform supports different robot types, including bipedal humanoids, quadrupeds, wheel-based robots, AMRs, and AGVs, through a unified management interface. LG CNS said the system reduces robot deployment timelines from several months to around one or two months. In mixed-robot environments of about 100 units, the company projects productivity gains exceeding 15 percent and operating cost reductions of up to 18 percent by minimizing traffic overlap, congestion, and manual intervention, Chosun Biz reported. The company has also invested in robotics and embodied AI firms developing humanoid control and robot foundation models. Currently, LG CNS is conducting proof-of-concept projects with 20 customers across industrial sectors while deploying the platform in South Korea’s Busan Smart City pilot project to manage patrol, cleaning, delivery, and service robots through a single system. Jijo is an automotive and business journalist based in India. Armed with a BA in History (Honors) from St. Stephen's College, Delhi University, and a PG diploma in Journalism from the Indian Institute of Mass Communication, Delhi, he has worked for news agencies, national newspapers, and automotive magazines. In his spare time, he likes to go off-roading, engage in political discourse, travel, and teach languages. Premium Follow
Images (1): 
|
|||||
| La française Genesis AI automatise les gestes complexes des robots | https://www.objetconnecte.com/la-franca… | 1 | May 10, 2026 00:00 | active | |
La française Genesis AI automatise les gestes complexes des robotsURL: https://www.objetconnecte.com/la-francaise-genesis-ai-automatise-les-gestes-complexes-des-robots/ Description: Genesis AI dévoile GENE-26.5 pour automatiser les manipulations robotiques complexes. La start-up française cible les usages industriels, scientifiques et domestiques. Content:
Par Prisca R. 8 mai 2026, 19 h 30 min 4 minutes de lecture Genesis AI signe une avancée majeure dans la robotique en automatisant les gestes complexes des robots. La start-up française dévoile un modèle de fondation révolutionnaire, le GENE-26.5, pour doter les robots d’une agilité inédite. Cette innovation promet de transformer les secteurs industriels et domestiques. Depuis Paris jusqu’à la Silicon Valley, Genesis AI structure une infrastructure d’IA appliquée à la robotique généraliste. Elle répond ainsi aux défis liés à l’automatisation de tâches manuelles complexes. Ces avancées s’inscrivent dans un contexte où 95 % des gestes manuels restent non automatisés. Genesis AI lance le GENE-26.5, un modèle articulé autour d’une main robotique à 20 degrés de liberté. Cette conception permet au robot d’exécuter des mouvements précis et indépendants, reproduisant la dextérité humaine. La main est équipée d’un matériau mimant la peau humaine, apportant un sensation tactile réelle. Cette innovation positionne Genesis AI au cœur des avancées robotiques. Le modèle inclut un moteur de données exploitant des vidéos à point de vue subjectif capturées lors d’interactions physiques réelles. En combinant ces données à des volumes massifs de vidéos en ligne, Genesis AI a su accroître l’efficacité de son apprentissage. Des gants équipés de capteurs tactiles et de suivi électromagnétique permettent de collecter jusqu’à 200 000 heures de données. Cette méthode surpasse, de cinq fois, les performances des téléopérations classiques. De ce fait, la start-up offre une plateforme d’apprentissage robotique d’une précision remarquable. Genesis AI illustre l’étendue de ses capacités dans des domaines aussi variés que les laboratoires, la cuisine ou le jeu. La mécanique du GENE-26.5 autorise le pipetage, le transfert de liquides, ou encore le scellage précis de tubes en environnement scientifique. Les robots peuvent même casser des œufs d’une main ou manipuler jusqu’à quatre objets simultanément. Cette polyvalence révèle une flexibilité jamais atteinte par les robots traditionnels. Les démonstrations incluent également des gestes complexes comme la résolution de Rubik’s Cube ou la préparation complète d’un smoothie. Ce niveau de précision illustre l’ambition de réaliser l’automatisation manuelle intégrale, bridée jusqu’ici par des contraintes techniques. En ce sens, le modèle dépasse largement les systèmes spécialisés et rigides dominants dans l’industrie robotique classique. Cette avancée ouvre des perspectives nouvelles pour les secteurs où la manipulation fine est cruciale. Genesis AI implémente une plateforme alliant simulation haute fidélité et collecte massive de données réelles. La start-up a mis au point un moteur physique en Python capable d’exécuter des simulations jusqu’à 80 fois plus rapides que les solutions GPU classiques. Cette innovation réduit drastiquement le temps d’entraînement des modèles, tout en conservant une précision exceptionnelle. Comparativement, ce moteur génère des résultats 430 000 fois plus rapidement que la simulation en temps réel traditionnelle. Cette infrastructure sim-to-real facilite la transposition des compétences acquises en environnement virtuel vers le monde physique. En combinant données synthétiques et données récoltées via les gants à capteurs, Genesis AI optimise le développement de ses modèles. Cette approche révolutionne la manière dont l’intelligence physique est entraînée. Elle offre un avantage stratégique dans l’industrie, notamment face aux limites des modèles d’apprentissage automatisés standard. Genesis AI bénéficie d’un soutien solide avec une levée de fonds de 105 millions de dollars, pilotée par Eclipse et Khosla Ventures. Xavier Niel et Eric Schmidt, ancien CEO de Google, comptent parmi les investisseurs influents. Ce financement permet à la start-up d’accélérer la conception de son premier robot généraliste, intégrant les technologies développées. La société vise la création d’une nouvelle génération de robots plus robustes, flexibles et économiquement accessibles. Théophile Gervet, cofondateur, souligne l’importance du vivier technologique français pour l’innovation en robotique. Le développement local s’accompagne d’une forte implantation aux États-Unis, point névralgique des avancées en intelligence artificielle. Enfin, Genesis AI prévoit d’ouvrir certains éléments clés en open-source. Cette ouverture vise à stimuler la recherche collaborative et à accélérer la généralisation de ces technologies de pointe. Ce projet s’inscrit dans un contexte où l’évolution des industries dépendra de l’automatisation intelligente et adaptative. Les tâches manuelles représentent entre 30 000 et 40 000 milliards de dollars du PIB mondial. Pourtant, 95 % de ces activités restent hors de portée des robots actuels, limités par des solutions rigides et coûteuses. Genesis AI ambitionne de combler cette lacune avec une robotique généraliste capable d’interagir efficacement dans des environnements complexes. Cette révolution robotique offre un potentiel économique colossal. Le ratio actuel entre robots et humains dans les usines dépasse rarement un robot pour trente employés. Cette situation reflète les difficultés liées à la mobilité, la dextérité et le raisonnement contextuel en environnement réel. L’intégration d’IA physique aux machines permettrait d’augmenter significativement les capacités d’automatisation. Ce point est crucial au regard des tensions persistantes sur le recrutement au niveau mondial. Offrir des solutions robotisées intelligentes répond à des besoins économiques et sociaux pressants, en assurant une efficacité durable et une diminution des coûts. Votre adresse e-mail ne sera pas publiée. Les champs obligatoires sont indiqués avec * Commentaire * Nom * E-mail * La start-up américaine 1X franchit une étape majeure dans la robotique domestique. Son usine californienne […] Plus Le robot de tennis de table Ace, développé par Sony AI, vient de franchir une […] Plus SoftBank mise sur la robotique pour transformer le secteur des data centers. La firme japonaise […] Plus La Chine franchit une nouvelle étape dans l’intégration des robots policiers. Le déploiement de 1000 […] Plus Découvrez les technologies qui transforment votre quotidien aux côtés de 30 000 passionnés Accueil > Business > Robotique > La française Genesis AI automatise les gestes complexes des robots Découvrez les technologies qui transforment votre quotidien aux côtés de 30 000 passionnés🔥 Copyright © 2026 Groupe Publithings. Tous droits réservés. Découvrez les technologies qui transforment votre quotidien aux côtés de 30 000 passionnés🔥
Images (1): 
|
|||||
| Genesis AI unveils GENE-26.5 robotic brain for human-level manipulation | … | https://www.foxnews.com/tech/new-ai-bra… | 1 | May 09, 2026 08:00 | active | |
Genesis AI unveils GENE-26.5 robotic brain for human-level manipulation | Fox NewsURL: https://www.foxnews.com/tech/new-ai-brain-lets-robots-move-like-humans Description: Genesis AI unveils GENE-26.5, a robotic brain designed to help general-purpose robots perform complex physical tasks with human-level dexterity and coordination. Content:
This material may not be published, broadcast, rewritten, or redistributed. ©2026 FOX News Network, LLC. All rights reserved. Quotes displayed in real-time or delayed by at least 15 minutes. Market data provided by Factset. Powered and implemented by FactSet Digital Solutions. Legal Statement. Mutual Fund and ETF data provided by LSEG. Fox News Flash top headlines are here. Check out what's clicking on FoxNews.com. Genesis AI, a global full-stack robotics company, has unveiled GENE-26.5, a robotic brain designed to help general-purpose robots perform complex physical tasks with human-level manipulation. The company says the system pairs a robotics foundation model with a human-scale dexterous robotic hand. It also includes a new data engine. Together, these pieces help robots learn from human movement and handle tasks that require precision and coordination. Sign up for my FREE CyberGuy Report ROBOTS LEARN 1,000 TASKS IN ONE DAY FROM A SINGLE DEMO Genesis AI says its robotic hand can learn from human motion data to complete detailed, multistep tasks such as cooking an omelet. (Genesis AI) Theo Gervet, co-founder and president of Genesis AI, says the easiest way to understand GENE-26.5 is to think of it as the system guiding the robot's actions. "Think of GENE-26.5 like a robotic brain that takes in information and tells the robot what to do," Gervet said. "It is the industry's most advanced robotic brain, with the most advanced capabilities. We've proven this by releasing a few videos showing GENE-26.5 powering the most complex tasks ever performed by robots." He says that matters because most robots still struggle with detailed hand movements. They often repeat one task in a controlled setting, but real life is less predictable. "We've developed a way to feed GENE-26.5 massive amounts of data about how human hands move, so it can tell our robotic hands exactly how to move like a human's hands," Gervet said. "GENE-26.5 can also tell our robotic hands how to do tasks with many, many steps." He pointed to a cooking example to show the difference. "For example, powered by GENE-26.5, our robotic hands can follow a 20-step process to make a full omelet from start to finish," Gervet said. "That's why we're obsessed with innovating across the full-stack, from AI to hardware. By controlling every layer, we can build a cohesive system and solve the problem holistically. Our approach gives us a huge competitive advantage by harnessing unprecedented amounts of data, as that ultimately defines what foundation models can achieve." Human hands constantly adjust, even during simple actions. That level of control has been hard for robots to replicate. To explain, Gervet used a Rubik's Cube as an example. "Imagine you're playing with a Rubik's Cube. You have to hold it with the perfect grip strength. If you grip it too loosely, you'll drop it." He said people make small adjustments without noticing. "You may not even realize it, but your brain is taking notice of how the cube feels. Even if you're just holding the cube, your hands are never perfectly still." Those small movements are constant. "They're constantly making micro adjustments to make sure the cube doesn't slip and stays balanced," he said. "It takes a lot of complicated, intentional and coordinated movements that involve over 20 joints in your fingers, knuckles and wrists. Our robotic hands can do exactly that." Genesis AI built a robotic hand that mirrors the human hand in form and function. It pairs with a glove that captures motion and pressure. "The glove system helps us directly transfer information about how human hands move to our robot hands," Gervet said. He explained how the system captures detail. "When a human wears the gloves as they interact with objects or do their work, we can capture details about the exact movements their fingers and wrists make. Our robotic hands are built to exactly match a human's hands, so that data works extremely well." Genesis AI says the glove is 100 times cheaper than typical options. It has also shown up to five times greater data collection efficiency compared with traditional methods. AI VIDEO TECH FAST-TRACKS HUMANOID ROBOT TRAINING Genesis AI unveiled GENE-26.5, a robotic brain designed to help general-purpose robots perform complex physical tasks with humanlike precision. (Genesis AI) Robots have lacked usable training data for physical tasks. "Robots have always had a data problem," Gervet said. "When you think about the AI chatbots you use on your computer, they have the entire internet to access." Robots did not have that advantage. "The big problem comes from the fact that unless the robot's hand exactly matches a human's hand, any information you capture about how human hands move won't translate well," Gervet said. He said matching the human hand solves that gap. "We've solved this problem by creating a robotic hand that exactly matches a human hand." Genesis AI also uses other sources of data to train its system. "In addition to data from the glove, we use videos from humans wearing camera headbands so we can see how their hands move," Gervet said. "We also use massive amounts of internet videos." The company says its simulation system is a major accelerator, allowing AI to train itself in a fully virtual environment before moving into the real world. This helps teams test and improve systems much faster than traditional physical testing, which can be slow and expensive. For now, Genesis AI expects the first use cases to be in workplaces such as warehouses and manufacturing facilities. "We see our technology being used in industrial settings to start and then later in the home," Gervet said. He described a phased rollout. "To start, it can be deployed for industrial use in warehouses and for manufacturing logistics. We're already having conversations with industrial customers." After that, the technology could expand further. "After the industrial phase, we'll offer our technology to the service industry. Next, it can be offered to consumers in their homes." Gervet went on to say that "In addition, we’re hoping that in a home setting, our technology will be able to help handle daily chores, freeing up time for people to spend doing what they actually enjoy. Robots have been humans’ biggest fantasy for years. This is our collective hope, and we want to be the company to get us there." ROBOTS PERFORM LIKE HUMAN SURGEONS BY JUST WATCHING VIDEOS The company says its glove-based data system captures finger, wrist and pressure movements to train robots more efficiently. (Genesis AI) Gervet says safety testing is a core part of development. "Our technology goes through extensive testing and validation, first in simulation running millions of scenarios, then in controlled real-world environments," he said. "It has to earn its way into the room." He added that the company also follows established safety standards and industry regulations designed to govern how robots operate around people. He went on to say the company is currently showcasing individual components, including the robotic brain, robotic hands and data collection system and plans to unveil a full general-purpose robot that brings everything together. Early, small-scale deployments with select partners could begin later this year. This technology will likely show up first in places like warehouses, factories and service environments where the work is repetitive or physically demanding. Gervet says, "In the future, we see our technology being able to fill some of the critical labor gaps there are today. Our hope is that this will increase productivity, while creating space for people to focus on meaningful, creative and high-value work." Over time, that could change. Robots that can use the same tools as people may fit into existing spaces more easily, without needing everything redesigned around them. "The beauty of the technology is that it’s meant to fit seamlessly into the human world," Gervet said. "Humans will still lead, but our reach won’t be limited by what we can do with our own hands." Take my quiz: How safe is your online security? Think your devices and data are truly protected? Take this quick quiz to see where your digital habits stand. From passwords to Wi-Fi settings, you’ll get a personalized breakdown of what you’re doing right and what needs improvement. Take my Quiz here: Cyberguy.com. This can feel like another robot demo, but the difference is how these robot hands move. They are starting to handle objects more like people do, using the same kinds of motions and tools. That is what makes this worth paying attention to. If robots can work in spaces built for humans without everything being redesigned, that is when things start to change in a more noticeable way. It also raises a bigger question about where this shows up first and how quickly it spreads. Not everything will change overnight, but this is the kind of progress that tends to build quietly and then suddenly feel like it is everywhere. So, be on the lookout for general-purpose robots that can suddenly handle objects more like human hands and start showing up in places you might not expect. CLICK HERE TO DOWNLOAD THE FOX NEWS APP As robots move and handle objects more like humans, do you want one helping you at home, or would that feel like a step too far at this point? Let us know by writing to us at CyberGuy.com. Sign up for my FREE CyberGuy Report Copyright 2026 CyberGuy.com. All rights reserved. Kurt "CyberGuy" Knutsson is an award-winning tech journalist who has a deep love of technology, gear and gadgets that make life better with his contributions for Fox News & FOX Business beginning mornings on "FOX & Friends." Got a tech question? Get Kurt’s free CyberGuy Newsletter, share your voice, a story idea or comment at CyberGuy.com. Get a daily look at what’s developing in science and technology throughout the world. Subscribed You've successfully subscribed to this newsletter! This material may not be published, broadcast, rewritten, or redistributed. ©2026 FOX News Network, LLC. All rights reserved. Quotes displayed in real-time or delayed by at least 15 minutes. Market data provided by Factset. Powered and implemented by FactSet Digital Solutions. Legal Statement. Mutual Fund and ETF data provided by LSEG.
Images (1): 
|
|||||
| Meta koopt AI-bedrijf voor robots - Emerce | https://www.emerce.nl/nieuws/meta-koopt… | 1 | May 09, 2026 08:00 | active | |
Meta koopt AI-bedrijf voor robots - EmerceURL: https://www.emerce.nl/nieuws/meta-koopt-aibedrijf-robots Description: Meta neemt de medewerkers en technologie over van een start-up die software bouwt voor intelligentie in mensachtige robots. Content:
Meta neemt de medewerkers en technologie over van een start-up die software bouwt voor intelligentie in mensachtige robots. Dat melden Amerikaanse media, waaronder Techcrunch en Quartz. Assured Robot Intelligence (ARI) bouwt sinds vorig jaar aan systemen die robots in staat stellen menselijk gedrag in complexe en dynamische omgevingen te begrijpen, te voorspellen en zich daaraan aan te passen. Het overgenomen team wordt onderdeel van Meta’s AI-lab, Superintelligence Labs. De start-up bouwt zogeheten foundation models voor mensachtige robots. Waar ChatGPT in de basis een taalmodel is, richt het werk van ARI zich op de bouw van een wereldmodel. Machines die de modellen en software gebruiken, moeten als het ware al kijkend de wereld om zich heen begrijpen. Met de overname slaat Meta hetzelfde pad is als Tesla, dat in samenwerking met xAI aan vergelijkbare robotische systemen werkt met wereldmodellen. Foto: Possessed Photography / Unsplash Uw e-mailadres wordt niet op de site getoond Een robot als maatje op de werkvloer wordt steeds minder een vergezicht en steeds vaker praktijk van de dag. In China zijn ze al redelijk betaalbaar en lopen de... PostNL houdt experimenten met bezorgrobots ter ondersteuning van de menselijke pakketbezorger. Na deze initiële testfase gaat de pakketbezorger de kaders stellen waar binnen het nieuwe technologie kan opschalen. Volgens een nieuw rapport zullen er over tien jaar naar schatting twee miljoen mensachtige robots aan het werk zijn, en driehonderd miljoen in 2050.
Images (1): 
|
|||||
| Meta Acquires Robotics Startup To Boost Humanoid AI | https://www.techjuice.pk/meta-acquires-… | 1 | May 09, 2026 00:00 | active | |
Meta Acquires Robotics Startup To Boost Humanoid AIURL: https://www.techjuice.pk/meta-acquires-assured-robot-intelligence-humanoid-ai-2026/ Description: Meta has acquired Assured Robot Intelligence to accelerate its push into humanoid robotics and AI-driven machines. Content:
Meta Platforms completed the acquisition of Assured Robot Intelligence on May 1, 2026 for an undisclosed sum. The acquisition brings the startup developing artificial intelligence models for robots into Meta’s Superintelligence Labs research division as part of a major initiative to build humanoid technology. Meta described the San Diego and New York-based startup as operating at the frontier of robotic intelligence designed to enable robots to understand, predict and adapt to human behaviors in complex and dynamic environments. The Assured Robot Intelligence team including co-founders Lerrel Pinto, Xiaolong Wang and Xuxin Cheng will join Meta’s artificial intelligence research division where they will bring deep expertise in designing models and frontier capabilities for robot control and self-learning to whole-body humanoid control. Wang previously worked as a researcher at NVIDIA while Pinto co-founded Fauna Robotics before departing in 2025, with Amazon acquiring Fauna in March 2026 demonstrating broader industry momentum toward physical artificial intelligence applications. Meta’s robotics team is working on in-house humanoid hardware along with the underlying artificial intelligence that powers it, developing sensors, software and other technology for robots that the company plans to make available to others in the industry. Rather than competing primarily in end-user robot sales, Meta envisions its role as an enabling platform for the robotics industry comparable to the role Android and Qualcomm’s processors played in mobile computing. The acquisition aligns with Meta’s broader investment in artificial intelligence following the company’s announcement in late April 2026 raising its capital spending forecast to between $125 billion and $145 billion for the year. The startup had been building foundation models for humanoid robots to perform various types of physical labor including household chores, addressing critical challenges in high-value labor markets where physical automation could provide significant economic value. Abdul Wasay explores emerging trends across AI, cybersecurity, startups and social media platforms in a way anyone can easily follow. Bangladesh-based travel platform GoZayaan announced it will exit Pakistan after four years, citing strategic realignment toward markets with stronger long-term potential. The company entered Pakistan. Pakistan’s startup ecosystem has traditionally been dominated by fintech, e-commerce and software companies, but a new category is slowly beginning to emerge: defense and aerospace. Pakistan is preparing to launch a new platform to connect green startups with global investors. The initiative aims to bridge the funding gap for climate-focused. Pakistan and Japan are expanding technology cooperation through the “GO GLOBAL” event in Tokyo. The forum connects startups, investors, and industry leaders to explore collaboration. Premier Pakistan technology news website with special focus on startups, entrepreneurship and consumer products. © 2026 TechJuice.PK – All rights reserved.
Images (1): 
|
|||||
| Georgia Tech robots learn complex tasks faster than ever before | https://newatlas.com/robotics/sail-robo… | 1 | May 08, 2026 16:00 | active | |
Georgia Tech robots learn complex tasks faster than ever beforeURL: https://newatlas.com/robotics/sail-robots-human-scale-tasks/ Description: Georgia Tech's new AI system lets robots perform delicate tasks like folding towels and packing food with speed and accuracy exceeding human capabilities. Content:
Thanks to researchers at Georgia Tech, robots have taken several new steps towards replacing human labor – and not simply for dangerous tasks such as mining the depths of the Earth and exploring the Moon, or difficult tasks such as high-speed mass-assembly of thousands of cars. Instead, picture fine-motor, subtly complex tasks that have generally been beyond robotic dexterity and coordination: stacking cups, folding towels, packing food, and placing fruit onto plates – that is, the tasks of workers at hospitals, senior care facilities, child care centers, and restaurants. Now, if you’re a business owner who wants to pay nobody to do that work and pocket all the profit, you’ll be thrilled. If you’re the person who does such work, or your family members do, or you own a business serving people who do, or you live in a city whose tax-base depends on tax-payers who do such labor, you may see the replacement of humans differently. But first, let’s examine the genuinely remarkable technical breakthrough. In a recently-presented paper, Georgia Tech researchers Nadun Ranawaka Arachchige, Zhenyang Chen and colleagues explain how they have improved robots to perform domestic and retail work as accurately as, but more quickly than, people can. According to Shreyas Kousik, co-lead author on the study, he and his colleagues want to create a “general-purpose robot that can do any task that human hands can do." To make that work outside the lab, speed really matters – hence their innovation: the AI-based Speed Adaptation of Imitation Learning (SAIL) system. Drawing upon robotics, mechanical engineering, and machine learning, SAIL combines an algorithm to preserve consistent, smooth motion at high speed, high-fidelity motion tracking, self-adjusting speed based on motion complexity, and “action-scheduling” for latency in the real world. Compared to demonstration speeds in experiments of 12 simulated and two actual tasks, two different types of SAIL-enabled robotic arms worked up to four times faster in simulation and up to 3.2 times faster in reality. While designers have previously imbued camera- and sensor-using robots with offline Imitation Learning (IL) and Behavior Cloning to perform human-scale tasks, those systems had a limit: the speed of the human demonstration of the task for imitation. In turn, the demonstration speed limits bandwidth or throughput (the ratio of data output to data input) that industrial automation demands. SAIL smashes that barrier. Previously, working human-scale tasks more quickly that humans did was difficult for robots, because small environmental changes and robotic physical performance can change at high speed, resulting in errors and damage. As Kousik explains, “The challenge is that a robot is limited to the data it was trained on, and any changes in the environment can cause it to fail.” For instance, one of the experimental SAIL tasks was erasing a whiteboard. A stand-mounted whiteboard wobbles when wiped too quickly, but a human would automatically adjust for that change. Until now, robots didn’t adjust (which this barely related and hilarious video sort of demonstrates). “Understanding where speed helps and where it hurts is critical. Sometimes slowing down is the right decision,” explains Kousik, to which co-author Joffe adds, “The goal is not just to make robots faster, but to make them smart enough to know when speed helps and when it could cause mistakes.” To fulfill that goal, SAIL’s modules coordinate acceleration beyond training data, thereby maintaining smooth, fast, accurate motion and tracking, while adjusting speed as-needed and scheduling tasks according to hardware lag. So far, SAIL isn’t a panacea for robotic assimilation and acceleration of human activity, but it’s a significant step toward that goal. Which brings us back to the beginning, and the robotic job-pocalypse. According to the McKinsey Global Institute, by 2030, robots, AI, and other automation will terminate between 400 and 800 million jobs worldwide, which Robozaps says means “forcing up to 375 million workers (roughly 14% of the global workforce) to switch occupations entirely.” In the US alone, notes McKinsey, “30 percent of hours worked today could by automated by 2030” – that is, almost a third of the country. While some people claim that robots are no threat to employment, and if operating for public benefit could be a route towards universal basic income, other analysts highlight the complexity of trying to make such a technotopia possible. And that assumes the powers that be want such a world. If they don’t, who’s going to create 375 million jobs to prevent a global depression? As the Economic Policy Institute notes, when companies delete 100 retail jobs, an additional 122 people lose their jobs because those 100 retail workers can no longer buy as many goods and services. It’s even worse in manufacturing, because when corporations blow up 100 jobs, they indirectly double-tap another 744. Ultimately, robots won’t need to look or act like The Terminator to destroy civilization. They might just need to fold your towels. Source: Georgia Tech Sign up for our FREE daily New Atlas newsletter!
Images (1): 
|
|||||
| At the 2026 AGIBOT Conference: Embodied AI Is Moving Into … | https://www.geeky-gadgets.com/at-the-20… | 1 | May 07, 2026 08:00 | active | |
At the 2026 AGIBOT Conference: Embodied AI Is Moving Into Deployment Phase - Geeky GadgetsDescription: The conversation around embodied AI (Robot as a physical interface for Artificial Intelligence) is evolving. While previous years focused on whether Content:
Geeky Gadgets The Latest Technology News 9:25 am April 25, 2026 By Roland Hutchinson The conversation around embodied AI (Robot as a physical interface for Artificial Intelligence) is evolving. While previous years focused on whether robots could move, perceive, and interact, the current question is whether these systems can operate reliably enough to integrate into real-world production. At its 2026 Partner Conference, the robotics company AGIBOT announced a shift toward an embodied AI “deployment phase,” moving the company toward developing systems built for reliable, real-world performance. The focus was on a cohesive, layered strategy that integrated products, models, deployment techniques, and ecosystem infrastructure. At the technical level, AGIBOT’s architecture is built around locomotion, interaction, and manipulation. The premise is that these capabilities cannot be treated in isolation if robots are to operate in real-world workflows. Movement enables access, interaction enables coordination, and task execution generates value. The company’s approach ties these together into a unified stack spanning hardware, perception, control systems, operating systems, and embodied AI models, with the aim of reducing fragmentation and speeding up iteration across the system. That integration is reflected in its current updated third-gen product lineup. AGIBOT has built a range of robot products covering humanoid, wheeled, and quadruped forms, each aligned with different operational environments. The positioning matches the form factor to the task. Alongside this, the company introduced six AI models aligned with the three intelligence layers, including motion-control models, multimodal interaction systems, and task-oriented models designed to handle longer, more complex operations. AGIBOT presented seven production solutions spanning manufacturing, logistics, commercial services, inspection, and cleaning, all framed as already operating in real environments. The distinction is important. These are not custom integrations, but standardized, repeatable solutions designed to scale. To support that shift, AGIBOT is building out infrastructure layers that extend beyond the robot itself. Its AIMA (AI Machine Architecture) ecosystem is intended to function as a full-stack development environment, lowering the barrier for deploying and customizing embodied AI systems. At the same time, the company introduced a large-scale data initiative and a global robot rental network, Sharebot, which allows partners to access robots as a service rather than through ownership. It reduces upfront costs, accelerates adoption, and creates a continuous loop in which deployment generates data, data improves models, and improved models feed back into deployment. Underlying all of this is a clear attempt to define the industry’s direction. AGIBOT outlined an “XYZ curve” as a framework for embodied AI development, with the past few years representing a phase where robots learned to move, and the coming years focused on whether they can consistently perform useful work. The company positions 2026 as the beginning of that transition. What APC 2026 ultimately presented was a system-level view of embodied AI. Robots do not operate in isolation, and neither can the systems that support them. The result is a reframing of what progress looks like, a system that can be deployed, iterated, and scaled. In that sense, the industry may be entering a phase where we finally get to see Artificial Intelligence becoming readily available in the physical world. Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Geeky Gadgets may earn an affiliate commission. Learn about our Disclosure Policy.
Images (1): 
|
|||||
| Reconova targets embodied intelligence with robots deployed in airports | https://kr-asia.com/reconova-targets-em… | 1 | May 07, 2026 08:00 | active | |
Reconova targets embodied intelligence with robots deployed in airportsURL: https://kr-asia.com/reconova-targets-embodied-intelligence-with-robots-deployed-in-airports Description: The company builds on its background in computer vision technology. Content:
Written by Cheng Zi Published on 30 Apr 2026 5 mins read On April 29, at the third China Embodied Intelligent Robot Industry Conference and Exhibition, Reconova delivered a keynote on breaking through bottlenecks in the scenario-based commercialization of embodied intelligence. For the company, which has spent 14 years in artificial intelligence, the message was clear: machines are improving in their ability to understand the world, and may soon be ready to perform physical work. At a time when much of the industry emphasizes general-purpose capability and scale, it is positioning itself around real-world deployment and practical execution. Reconova was founded in 2012. Since then, it has operated through two distinct eras of AI. In the early phase, the central technical challenge was perception: enabling machines to interpret images, recognize objects, and understand scenes. This period coincided with the rapid expansion of deep learning, and intense competition among computer vision companies. Over time, that segment underwent a sharp consolidation. At its peak, thousands of companies claimed to compete in the space, capital flowed aggressively, and valuations rose quickly. A prolonged correction followed, marked by tighter financing, limited commercialization at scale, and increasingly homogeneous competition that compressed margins. Around 2019, many companies began to falter. Former unicorns were sold at discounts or shut down, outcomes that became increasingly common. At the time, security and finance were among the most targeted sectors. Reconova instead focused on less prominent use cases: passenger processing in civil aviation airports, commercial real estate applications in shopping malls, and driver assistance safety systems for commercial freight vehicles. From the outside, that appeared to be a conservative choice. That restraint, however, helped Reconova survive a period of high attrition while maintaining a leading market position, the company said. That focus appears to have translated into a defensible position. According to Frost & Sullivan, by 2024 revenue, Reconova ranked first in China’s visual intelligence products market for civil aviation enterprises, with an 8.9% share. Its products are deployed in roughly one-third of China’s civil airports. Among large hub airports handling more than ten million passengers annually, coverage rises to two-thirds. In the current AI cycle, the technical focus has shifted. Large models have expanded capabilities beyond perception to include action. For Reconova, this marks an inflection point. Jhan Dennis, founder and chairman of Reconova, described the transition: “Over the past 12 years, we have been building eyes, using vision to perceive and understand the physical world,” he said. “But now we are starting to move forward, toward the brain and the hands. On the basis of understanding the world, we are starting to make decisions, carry out execution, and help people get things done.” The company is expanding its focus from perception and cognition to decision-making and execution, with the aim of building a closed-loop system. It is positioning itself as a provider of embodied intelligence products for commercial scenarios and complex operations. Much of the current narrative around embodied intelligence emphasizes general-purpose capability. Systems that can adapt across multiple scenarios tend to attract stronger investor interest. That framing can disadvantage companies focused on vertical applications. Jhan takes a different view. General-purpose capability, he said, defines competition among platform companies and depends on scale, ecosystems, and early data network effects. In contrast, barriers in vertical scenarios are built through detailed understanding of workflows and repeated problem-solving with customers, not through model size alone. On the technical front, Reconova outlines a three-layer framework: Reconova’s commercialization strategy reflects these constraints. Jhan said complex, unstructured, and specialized scenarios are likely to reach commercial viability before general-purpose applications. General-purpose robots face dual constraints of technical capability and cost. They must generalize across tasks while meeting procurement thresholds for enterprise customers. Achieving both simultaneously remains difficult. In contrast, specialized systems can be optimized within known constraints, making them more viable commercially. Civil aviation is Reconova’s initial entry point for embodied intelligence. Its first deployment scenario is baggage handling. Baggage handling is among the most labor-intensive processes in aviation. Recruitment is difficult, turnover is high, and efficiency varies with weather and shift schedules. Airports have struggled with these issues for years. In practice, the environment presents multiple challenges. Baggage varies widely in shape and material, from rigid suitcases to soft bags and irregular items. Each requires different handling approaches. The physical environment is also inconsistent, with narrow pathways and tight equipment spacing, requiring real-time navigation. In addition, operations require close coordination between humans and machines, where delays in perception or decision-making could introduce safety risks. These constraints limit the effectiveness of general-purpose robots in such settings. While they may function across multiple scenarios, consistent performance in demanding environments remains difficult. Cost structures also limit their return on investment in labor-replacement use cases. Reconova has responded by developing a robot designed specifically for airport baggage handling. At the 2025 International Airport Expo, its AntOne robot demonstrated the ability to move and stack baggage of varying shapes in a simulated transfer zone. The company said the system incorporates a human-machine collaborative operating model. The robot performs repetitive transport and stacking tasks, while human workers intervene in edge cases. According to Reconova, this division of labor improves overall efficiency compared with fully manual operations. Jhan said pilot deployments at airports indicate that AntOne reduces labor dependence and physical strain on workers. He added that system throughput has increased by 30%, while baggage damage rates have declined to 0.12%. Reconova is conducting trials at multiple airports and plans to begin commercial deployment in the second half of the year. It is also exploring international markets, including Southeast Asia and the Middle East, where similar operational challenges exist. In a field often defined by broad ambitions, Reconova has taken a narrower approach, focusing on a specific problem and measurable outcomes in real environments. Within the embodied intelligence landscape, it does not fit neatly into either general-purpose robotics or traditional computer vision. It positions itself as a provider of systems designed for complex scenarios and precise physical operations. As with previous technology cycles, interest in robotics may fluctuate. Systems that demonstrate reliability in demanding conditions are more likely to persist. Reconova’s strategy, centered on depth over breadth, reflects that view and defines its position in the current market. KrASIA features translated and adapted content that was originally published by 36Kr. This article was written by Xiao Xi for 36Kr. Loading... Subscribe to our newsletters KrASIA A digital media company reporting on China's tech and business pulse.
Images (1): 
|
|||||
| New social pet robot uses local AI to learn complex … | https://interestingengineering.com/ai-r… | 1 | May 05, 2026 16:00 | active | |
New social pet robot uses local AI to learn complex human behaviorURL: https://interestingengineering.com/ai-robotics/familiar-robot-consumer-physical-ai-reveal Description: The Familiar companion robot uses expressive movement and multimodal AI to interact with people beyond traditional task-based machines. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation all with fewer ads or a completely ad-free experience. All Rights Reserved, IE Media, Inc. Colin Angle’s robot features a touch-sensitive coat, vision system, and microphones to interpret and respond to people. A new kind of robot is taking shape, and it is not built for factories. It is designed for people. At the Future of Everything conference, robotics pioneer Colin Angle unveiled a quadruped machine that focuses on interaction and companionship. The system, called a “Familiar,” represents a shift in how engineers approach physical AI. Angle, best known for cofounding iRobot and launching the Roomba, now leads Familiar Machines & Magic. The company has operated in stealth until now. The first Familiar is a four-legged robot designed to engage with people. It does not rely on a screen. Instead, it uses motion, sound, and touch. The machine features 23 degrees of freedom for expressive movement. Engineers added a touch-sensitive outer layer, along with cameras and microphones. These systems help the robot interpret its surroundings and respond naturally. Its onboard AI runs locally, using a compact multimodal model. This setup combines vision, audio, language, and memory in real time. The goal is to create behavior that evolves through repeated interaction. Angle said, “The next era of robotics is not just about dexterity or humanoid form – it’s about machines that can build and sustain human connection.” He added, “Today, we’re emerging from stealth to share our vision for systems that move beyond task execution and become a natural part of daily life.” Most investment in physical AI targets industrial use. Companies focus on robots that lift, sort, or transport goods. That market continues to grow rapidly. Angle’s team sees a different opportunity. They aim to build machines that people interact with daily. That requires a different design philosophy. Consumer-facing robots must understand context and emotion. They must respond in ways that feel intuitive. According to the company, physical presence plays a key role in this. FM&M argues that embodied systems can outperform screen-based AI in emotional tasks. People respond more strongly to physical agents than to chatbots. The team behind the project brings experience from major tech and robotics groups. Their background includes work at Disney Research, MIT, Amazon, and Boston Dynamics. Angle positioned the new robot as a step beyond earlier consumer machines. “iRobot proved that robots could deliver value at scale,” he said. “But they were still task machines.” “My goal has always been to create systems that understand context, remember interactions, and behave with consistency over time. That’s what we’re doing at Familiar Machines & Magic.” Unlike humanoid robots, the Familiar avoids human-like form. Engineers chose a quadruped design to improve approachability and movement. The focus remains on presence and interaction. The company has not announced a release timeline. It also has not detailed specific use cases. Today’s reveal marks a technology preview, not a product launch. Still, the direction is clear. FM&M wants to scale robots that people choose to live with. The company emphasizes on-device AI to reduce latency and protect privacy. The Familiar suggests a shift in robotics. Instead of machines that complete tasks, engineers are building systems that build relationships. Aamir is a seasoned tech journalist with experience at Exhibit Magazine, Republic World, and PR Newswire. With a deep love for all things tech and science, he has spent years decoding the latest innovations and exploring how they shape industries, lifestyles, and the future of humanity. Premium Follow
Images (1): 
|
|||||
| POCO soft robot companion rethinks human-AI connection | https://www.designboom.com/technology/p… | 1 | May 05, 2026 16:00 | active | |
POCO soft robot companion rethinks human-AI connectionDescription: poco is a soft robotic companion that examines alternative relationships between humans and artificial intelligence. Content:
POCO is a soft robotic companion developed by designer Mehrnaz Amouei that examines alternative relationships between humans and artificial intelligence. The project focuses on interaction models based on presence, responsiveness, and clearly defined limitations, rather than systems that interpret or direct emotional states. As AI increasingly operates within personal and emotional contexts, questions emerge around dependency, interpretation, and control. POCO addresses these concerns by proposing a relational framework in which the system functions alongside the user without assuming authority. Instead of diagnosing or guiding behavior, the device is designed to respond, reflect, and maintain boundaries that remain visible to the user. The project is informed by a year-long research process involving qualitative interviews, interdisciplinary input, and iterative prototyping. Findings indicated a preference for systems that offer availability and responsiveness without projecting certainty or control. In response, the design introduces the concept of ‘constructive interdependence,’ where limitations are embedded as part of the interaction model. The system communicates what it can and cannot do through its behavior and states. POCO’s form remains ambiguous, between object, creature, and companion | all images courtesy of Mehrnaz Amouei Physically, POCO is developed as a soft, tactile object that connects to a smartphone, which functions as its computational component. Interaction is based on touch, using capacitive sensors that respond to gestures such as holding or stroking. Movement is expressed through slow, rhythmic actions that resemble breathing, reinforcing a sense of presence without relying on mechanical articulation. Engagement with the device is structured as a reciprocal process. The system does not initiate interaction independently but responds to user input, establishing a shared rhythm. States of activity and rest are visibly communicated, reinforcing awareness of the system’s operational boundaries. Through its integration of material, behavior, and interaction logic, POCO robot companion positions AI as a participant within a relational system rather than a directive tool. The project frames trust not as a function of expanded capability, but as a result of transparency, limitation, and balanced interaction between user and device. robot’s variations adapt to users, environments, and emotional preferences while maintaining a consistent identity a soft textile body wraps around the device, transforming rigid technology into a huggable presence at human scale, POCO moves through spaces as a quiet presence, less a device and more a companion that belongs a soft robotic companion designed as a quiet emotional presence that integrates into everyday life a prototype setup showing the robotic device’s tactile interface a working prototype explores tactile interaction, and how AI can exist in a physical, touchable form project info: name: POCO | Soft Robotic Companion for Everyday Life designer: Mehrnaz Amouei | @minazez designboom has received this project from our DIY submissions feature, where we welcome our readers to submit their own work for publication. see more project submissions from our readers here. edited by: christina vergopoulou | designboom happening now! florim brings a sense of handcrafted authenticity to contemporary architectural surfaces, presenting sensicolore.
Images (1): 
|
|||||
| Whale Cloud and AGIBOT Announce Strategic Partnership to Accelerate Global … | https://en.antaranews.com/news/413431/w… | 1 | May 05, 2026 08:00 | active | |
Whale Cloud and AGIBOT Announce Strategic Partnership to Accelerate Global Expansion of Embodied AI - ANTARA NewsDescription: Whale Cloud, a global leader in providing full-stack digital and intelligent capabilities for telecommunications and enterprise customers, and AGIBOT, a ... Content:
© 2020 Reporter: PR WireEditor: PR Wire Copyright © ANTARA 2026
Images (1): 
|
|||||
| Meta compra Assured Robot Intelligence para avanzar en robots humanoides … | https://pisapapeles.net/meta-compra-ass… | 1 | May 04, 2026 08:00 | active | |
Meta compra Assured Robot Intelligence para avanzar en robots humanoides con IADescription: Meta suma talento en robótica para desarrollar sistemas que permitan a futuros humanoides moverse y adaptarse a entornos reales. Content:
Dispositivos que han pasado por nuestras manos. Aquí podrás encontrar todo lo nuevo en tecnología móvil. ¿Tienes dudas? Estás en el lugar indicado. Rumores del mundo móvil. Nada está confirmado. Entrevistas a personas notables dentro del mundo de la tecnología ¿Te gusta jugar? Aquí podrás revisar reviews, noticias y más. Meta compró Assured Robot Intelligence, una startup que desarrolla IA para robots, como parte de un plan más amplio para entrar en el mercado de robots humanoides, según detalló Bloomberg. La operación se cerró el viernes y no se revelaron los términos financieros. La adquisición suma a Meta un equipo especializado en crear sistemas capaces de ayudar a los robots a entender lo que ocurre a su alrededor, anticipar conductas humanas y adaptarse a espacios cambiantes. La compañía busca avanzar en máquinas con forma humana que puedan moverse como personas y apoyar tareas físicas. Assured Robot Intelligence le permitirá a Meta sumar experiencia en IA aplicada al control de robots humanoides. La compañía pretende desarrollar máquinas capaces de coordinar movimiento, percepción y aprendizaje, en un sector donde también están trabajando empresas como Tesla, Google y Amazon. El equipo de la firma adquirida, incluidos sus cofundadores Lerrel Pinto y Xiaolong Wang, se integrará a Meta Superintelligence Labs. Del mismo modo, trabajarán junto a Meta Robotics Studio, grupo creado el año pasado para desarrollar la tecnología base de futuros robots. La compra no apunta solo a investigar robots dentro de Meta, sino que, además, la firma también trabajaría en hardware humanoide propio, sensores, software y sistemas de IA que podrían quedar disponibles para otras compañías del sector. La trayectoria de los fundadores refuerza el interés de Meta por sumar experiencia directa en robótica avanzada: Meta va más allá de fabricar sus propios robots; además, buscará crear una base tecnológica que otros fabricantes puedan adoptar, como ocurrió en los teléfonos móviles con Android y los chips de Qualcomm.
Images (1): 
|
|||||
| Meta acquires Assured Robot Intelligence to build the Android of … | https://thenextweb.com/news/meta-acquir… | 1 | May 04, 2026 08:00 | active | |
Meta acquires Assured Robot Intelligence to build the Android of humanoid robotsURL: https://thenextweb.com/news/meta-acquires-assured-robot-intelligence-humanoid Description: Meta bought ARI, a robotics AI startup, and folded it into Superintelligence Labs. The goal: be the platform every humanoid manufacturer needs. Content:
TL;DRMeta acquired Assured Robot Intelligence, a startup co-founded by former Fauna Robotics co-founder Lerrel Pinto and former Nvidia researcher Xiaolong Wang, to bolster its humanoid robotics platform strategy. The deal, which brings whole-body robot control models and tactile sensor technology into Meta Superintelligence Labs, reveals Meta’s ambition to be the Android of humanoids: provide the intelligence layer and let others build the machines. Meta acquired Assured Robot Intelligence, a startup co-founded by former Fauna Robotics co-founder Lerrel Pinto and former Nvidia researcher Xiaolong Wang, to bolster its humanoid robotics platform strategy. The deal, which brings whole-body robot control models and tactile sensor technology into Meta Superintelligence Labs, reveals Meta’s ambition to be the Android of humanoids: provide the intelligence layer and let others build the machines. Lerrel Pinto co-founded Fauna Robotics, a startup that built an approachable bipedal robot called Sprout. He left in 2025. Amazon acquired Fauna in March, along with its 50 employees and its $50,000, three-and-a-half-foot-tall dancing humanoid, to enter the consumer robotics market. Pinto then co-founded Assured Robot Intelligence with Xiaolong Wang, a former Nvidia researcher and associate professor at UC San Diego who won the MLSys 2024 Best Paper Award for work on AI model optimisation. On Friday, Meta acquired ARI and both founders joined Meta Superintelligence Labs. The acquisition closed the same day it was announced. Financial terms were not disclosed. The interesting question is not what Meta paid for a startup whose employees were concentrated in San Diego and New York. It is what Meta intends to do with the technology, and what that intention reveals about the company’s theory of how the humanoid market will develop. Meta’s stated goal for robotics is to replicate what Google’s Android operating system and Qualcomm’s chips did for the smartphone industry: build the foundation that everyone else builds on. The company launched Meta Robotics Studio last year, hired former Cruise CEO Marc Whitten to lead the effort, and began recruiting roughly 100 engineers to develop in-house humanoid hardware alongside the AI models that power it. CTO Andrew Bosworth has described humanoid robots as Meta’s next bet of comparable scale to augmented reality, a category in which Meta has already spent tens of billions through its Reality Labs division. The ARI acquisition adds a specific capability to this effort: robot control models that enable humanoids to understand, predict, and adapt to human behaviour in unstructured environments. The platform strategy is explicit. Meta intends to develop sensors, software, and AI models for robots and make them available to the rest of the industry, meaning the technology could be used by manufacturers that Meta does not own or control. This is the Android model applied to physical machines. In smartphones, Google gave away the operating system and captured value through search, advertising, and the Play Store ecosystem. In robotics, Meta would give away the intelligence layer and capture value through the data, the model ecosystem, and the integration with Meta’s existing platforms, where 3.3 billion people already interact daily. Meta has been acquiring AI talent aggressively, hiring five founding members of Thinking Machines Lab, including a researcher whose six-year package reportedly reached $1.5 billion. The ARI acquisition fits the same pattern: small team, frontier capability, immediate integration into the Superintelligence Labs research division. TNW City Coworking space - Where your best work happens A workspace designed for growth, collaboration, and endless networking opportunities in the heart of tech. ARI’s technical contribution centres on what the company calls “robotic intelligence designed to enable robots to understand, predict and adapt to human behaviors in complex and dynamic environments.” In practice, this means AI models for whole-body humanoid control, the ability to coordinate a robot’s limbs, balance, and movement in response to real-time sensory input from an unpredictable physical world. Wang’s award-winning work on activation-aware weight quantisation, the same technique that made Nebius’s $643 million acquisition of Eigen AI valuable this week, is relevant here: compressing AI models so they run efficiently on the limited compute available inside a robot, rather than requiring a connection to a remote data centre. The company also developed e-Flesh, a tactile sensor that measures deformations in 3D-printable microstructures using magnets and magnetometers. Tactile sensing is one of the unsolved problems in humanoid robotics. A robot that can see its environment through cameras and lidar still cannot feel the difference between gripping an egg and gripping a tennis ball without tactile feedback. The gap between how robots learn in simulation and how they perform in the physical world remains the central obstacle to deployment at scale. ARI’s work on self-learning for robot control, combined with its sensor technology, addresses both sides of that gap: better models and better sensory input. The humanoid robotics market has moved from speculative to competitive in the span of 18 months. Tesla plans to begin large-scale production of its Optimus V3 humanoid between July and August, with annual capacity targets of one million units by late 2026 and a price point between $20,000 and $30,000. 1X Technologies has opened a factory in Hayward, California, to produce 10,000 NEO humanoid robots in its first year, with first-year production capacity selling out within five days of preorders opening. Apptronik has raised $520 million at a $5 billion valuation, partnering with Google DeepMind and its Gemini Robotics models. Amazon has made two robotics acquisitions in a single month. Unitree is targeting 20,000 humanoid shipments in 2026. Morgan Stanley projects the global humanoid robot market will reach $38 billion by 2035 and $5 trillion by 2050. The competitive dynamics are clarifying into three tiers. The first tier is vertically integrated manufacturers, companies like Tesla and 1X that design, build, and sell the complete robot. The second tier is platform providers, companies that supply the intelligence layer, the operating system, or the key components that multiple manufacturers use. The third tier is the component suppliers, chipmakers and sensor companies that sell to both. Meta is positioning itself in the second tier, and it is not alone. Google, through DeepMind’s Gemini Robotics programme and its partnership with Apptronik, is pursuing a similar platform strategy. Europe is developing its own approach to the humanoid race, with companies and research institutions pursuing strategies that emphasise safety, industrial precision, and regulatory compliance over the speed-to-market approach favoured by American and Chinese competitors. Meta’s history with hardware platforms is instructive. The company missed mobile. Facebook Home, its 2013 attempt to become the default interface on Android phones, was discontinued within a year. The company then spent more than $50 billion on Reality Labs attempting to own the next computing platform through virtual and augmented reality, a bet that has yet to produce returns at anything approaching the scale of its advertising business. The Ray-Ban Meta smart glasses are the closest the company has come to a successful hardware product outside of its core social media platforms, and even those are essentially an accessory for Meta’s AI assistant rather than a standalone computing device. The robotics bet is different in one respect. Meta is not attempting to manufacture the hardware at scale itself. It is attempting to provide the intelligence, the models, the sensor technology, and the software stack, and let others build the machines. This is a lower-capital, higher-leverage strategy than the Reality Labs approach, and it plays to Meta’s genuine strengths in AI research, open-source model distribution, and platform economics. But it depends on the humanoid market developing the way the smartphone market developed: with hundreds of manufacturers needing a common software platform. If the market instead consolidates around a few vertically integrated players, each with proprietary AI, the Android model does not apply. Tesla is not looking for an operating system. Neither is 1X. The companies that might want Meta’s intelligence layer are the ones that do not yet exist, the humanoid equivalents of Samsung and Xiaomi and Oppo, manufacturers that can build bodies but need someone else to provide the brain. Meta is betting those companies are coming. The ARI acquisition is the latest investment in making sure that when they arrive, Meta’s technology is what they reach for first. Alina Maria Stan builds connections that people actually feel. As co-founder and COO of Tekpon, she turns product intuition into real moment (show all) Alina Maria Stan builds connections that people actually feel. As co-founder and COO of Tekpon, she turns product intuition into real moments of discovery, shaping how teams find and adopt SaaS every day. Since 2020, she has led Tekpon’s brand voice, media strategy, and growth plays with a clear focus on human outcomes behind every metric. Before Tekpon, Alina followed curiosity across industries and countries. She was CEO of King Casino Bonus and led affiliate and brand strategy at Extremoo Media and Fable Media in Denmark, where she learned how to build partnerships that last. Early on, she sharpened her CRM and pricing instincts at K.H. ApS, always asking why customers choose what they choose. Her approach is rooted in more than a decade of international experience and two master’s degrees, one in Sustainable Consumption from the Technical University of Munich and one in Consumer Affairs Management from Aarhus University. Get the most important tech news in your inbox each week. The heart of tech A Tekpon Company Copyright © 2006—2026, Cogneve, INC. Made with <3 in Amsterdam.
Images (1): 
|
|||||
| Meta compra Assured Robot Intelligence para construir el Android de … | https://wwwhatsnew.com/2026/05/04/meta-… | 1 | May 04, 2026 08:00 | active | |
Meta compra Assured Robot Intelligence para construir el Android de los robots humanoidesURL: https://wwwhatsnew.com/2026/05/04/meta-adquiere-assured-robot-intelligence-humanoides/ Description: Meta acaba de adquirir Assured Robot Intelligence (ARI), una startup especializada en IA para robots, con el objetivo declarado de resolver "los desafíos críticos de los mercados laborales de alto valor". Lo publica Mariella Moon en Engadget este 2 de mayo. El precio de la operación no se ha revelado, pero el movimiento es estratégico: Meta compra Assured Robot Intelligence para construir el software que gobierne humanoides. El equipo fundador se une a Superintelligence Labs. Sin precio revelado. Content:
Publicado el 4 mayo, 2026 Meta acaba de adquirir Assured Robot Intelligence (ARI), una startup especializada en IA para robots, con el objetivo declarado de resolver «los desafíos críticos de los mercados laborales de alto valor». Lo publica Mariella Moon en Engadget este 2 de mayo. El precio de la operación no se ha revelado, pero el movimiento es estratégico: el equipo al completo de ARI, incluidos sus tres cofundadores, se incorpora a los Superintelligence Labs de Meta, el nuevo laboratorio de IA que dirige Alexandr Wang. Mark Zuckerberg quiere construir el sistema operativo de los robots humanoides. Y va en serio. ARI es una startup fundada por Xiaolong Wang, Xuxin Cheng y Lerrel Pinto, tres investigadores de robótica con perfiles académicos notables. Pinto también cofundó Fauna Robotics, que fue adquirida por Amazon para su propio proyecto de robots humanoides, lo que da idea del nivel del equipo que Meta se acaba de llevar. El objetivo de la empresa era construir lo que Wang llama un «agente físico de propósito general», es decir, un sistema capaz de aprender directamente de la experiencia humana y ejecutar tareas en el mundo real con un cuerpo humanoide. En un post en X, Wang explicó que desde el principio sabían que ese agente tendría que ser humanoide y que el escalado llegaría a través del aprendizaje directo de lo que hacen las personas. La arquitectura técnica de ARI se centra en el control de todo el cuerpo (whole-body humanoid control) y en el aprendizaje autónomo, los dos problemas más difíciles de resolver en robótica moderna. No es visión por ordenador clásica: es enseñar al robot a moverse como un humano, con toda la complejidad que eso conlleva. El CTO de Meta, Andrew Bosworth, lleva al menos desde 2025 articulando una visión muy clara: Meta quiere ser el Android de la robótica. No fabricar robots, sino crear el software que otros fabricantes puedan licenciar. La misma apuesta que hizo Google con los móviles, pero para humanoides. «El software es el cuello de botella», dijo Bosworth, que proyectaba empezar con una mano robótica con destreza y escalar desde ahí. La adquisición de ARI encaja perfectamente en esa hoja de ruta: el equipo trae experiencia profunda en cómo diseñar modelos y capacidades de frontera para el control robótico. Meta no parte de cero. Cuenta con Superintelligence Labs, liderado por Alexandr Wang (el mismo que antes dirigía Scale AI), ya investido como Chief AI Officer. Tiene recursos de infraestructura masivos, acceso a datos a una escala que pocas empresas en el mundo pueden igualar y una estrategia de IA abierta (familia Llama) que le ha granjeado una comunidad de desarrolladores. Para un problema que requiere aprender de la experiencia humana, eso es un activo enorme. El momento no es casual. Hay al menos tres competidores directos con movimientos relevantes en los últimos meses. Amazon acaba de quedarse con Fauna Robotics, cofundada por el mismo Lerrel Pinto que ahora se va a Meta, para construir su propia flota de robots en almacenes y centros de distribución. Tesla lleva años desarrollando el robot Optimus y ha tomado la decisión, anunciada este año, de dejar de producir los modelos S y X en su fábrica de Fremont, California, para reconvertir ese espacio en líneas de producción de robots humanoides. Figure AI, 1X y Apptronik también están en carrera, con rondas de inversión multimillonarias en los últimos dos años. El hardware de los robots mejora rápido. Según el razonamiento de Bosworth, eso hace que el software sea el diferenciador real. Quien resuelva primero el control general del cuerpo humanoide a escala tendrá una ventaja estructural difícil de replicar. Llevo cubriendo movimientos de Meta en IA desde que se llamaba Facebook AI Research en 2013, y pocas veces he visto a la empresa comprar algo tan claramente alineado con una estrategia a diez años. La adquisición de ARI no es una apuesta especulativa: es la pieza que faltaba para darle credibilidad técnica a la visión del Android robótico. Lo que más me convence es la coherencia del equipo. Pinto viene de fundar Fauna Robotics (Amazon lo quiso), Wang ha publicado trabajo puntuado en NeurIPS y Cheng ha trabajado en sistemas de locomoción de última generación. Cuando los tres se van juntos a la misma empresa, es porque creen en la visión. Lo que más me preocupa es el timing competitivo. Meta ya recortó 8.000 empleados en mayo de 2026 y reorientó toda su estructura hacia la IA, apostando a que los ahorros de plantilla financian la infraestructura futura. Si el negocio de robots tarda más de cinco años en generar ingresos reales, la narrativa interna se complica. Y Amazon, con la distribución de Fauna Robotics y una cadena de suministro que ya existe, tiene una ventaja operativa real sobre una empresa que arranca desde el software. La pregunta a doce meses no es si Meta puede construir buenos modelos para robots. Es si puede construirlos más rápido que Tesla, que tiene hardware propio, instalaciones de producción reconvertidas y un dataset de conducción autónoma que lleva años generando datos del mundo físico. La vigilancia de los empleados de Meta para entrenar agentes de IA y el plan de Superintelligence Labs son señales de que Zuckerberg entiende que el dato es el moat. Si consigue que los humanoides aprendan de las interacciones humanas a escala, la apuesta puede funcionar. Si no, habrá pagado muy caro por talento que tardará años en producir algo con nombre. ARI desarrolla IA para control de robots humanoides, con foco en el control de todo el cuerpo y en sistemas de aprendizaje que permiten al robot aprender directamente de la experiencia humana, sin depender de programación manual de cada movimiento. No se han revelado los términos económicos de la adquisición. Engadget confirmó el movimiento a través de un portavoz de Meta que citó Bloomberg como primera fuente. Tesla apuesta por el hardware propio con el robot Optimus y una planta de producción dedicada, mientras Meta quiere desarrollar el software que licenciar a fabricantes terceros, siguiendo el modelo Android. Son estrategias complementarias, aunque ambas compiten por el mismo talento y los mismos datos de entrenamiento. por Natalia Polo Análisis diario, herramientas y tutoriales sobre IA en wwwhatsnew.
Images (1): 
|
|||||
| GitHub - amitb-quantum/roboapi: The unified API layer for robotics. Connect … | https://github.com/amitb-quantum/roboapi | 1 | May 03, 2026 16:00 | active | |
GitHub - amitb-quantum/roboapi: The unified API layer for robotics. Connect any robot, any brand, with one SDK. Like Stripe, but for robots. · GitHubURL: https://github.com/amitb-quantum/roboapi Description: The unified API layer for robotics. Connect any robot, any brand, with one SDK. Like Stripe, but for robots. - amitb-quantum/roboapi Content:
We read every piece of feedback, and take your input very seriously. To see all available qualifiers, see our documentation. The unified API layer for robotics. Connect any robot, any brand, with one SDK. Every robot manufacturer ships a different SDK, a different protocol, and a different data format. A Boston Dynamics Spot speaks nothing like a Universal Robots UR5. A Figure humanoid has nothing in common with an Agility Robotics Digit. Every team building on top of robots rewrites the same integration layer from scratch. This is a multi-billion dollar tax on the robotics industry. RoboAPI is the Stripe for Robotics — a single unified API that abstracts every robot into one clean developer experience. One SDK. One API key. Every robot. That's it. No ROS knowledge required. No brand-specific SDKs. No protocol translation. Browse the full interactive API docs at http://localhost:8000/docs RoboAPI connects to any ROS2 robot via rosbridge. The turtle draws a full circle — driven entirely through the unified RoboAPI layer. 🐢 RoboAPI uses a pluggable adapter pattern. To add any robot: Register it in adapters/__init__.py and it's immediately available through the full API. RoboAPI is in early development and we welcome contributions — especially: See CONTRIBUTING.md for guidelines. The robotics industry is at its Stripe moment. Before Stripe, every company built custom payment integrations. Before Twilio, everyone wrote their own SMS stack. The pattern is always the same: fragmented, complex, infrastructure problem → one abstraction layer wins → everything builds on top. Robotics is there right now. Dozens of manufacturers, dozens of protocols, thousands of teams rebuilding the same middleware. RoboAPI is the abstraction layer. MIT — see LICENSE 🚧 Early development — API may change. Not yet recommended for production. ⭐ Star this repo to follow progress. 💬 Open an issue to request a robot adapter or report a bug. Built with FastAPI · ROS2 · roslibpy The unified API layer for robotics. Connect any robot, any brand, with one SDK. Like Stripe, but for robots. There was an error while loading. Please reload this page. There was an error while loading. Please reload this page. There was an error while loading. Please reload this page. There was an error while loading. Please reload this page. There was an error while loading. Please reload this page. There was an error while loading. Please reload this page.
Images (1): 
|
|||||
| Think Robots Are Impressive Now? Just Wait Until They Have … | https://www.cnet.com/tech/computing/thi… | 1 | May 03, 2026 08:00 | active | |
Think Robots Are Impressive Now? Just Wait Until They Have 6G - CNETURL: https://www.cnet.com/tech/computing/think-robots-are-impressive-now-just-wait-until-they-have-6g/ Description: This next-generation network technology won't just make our phones faster; it'll unlock new capabilities in robots, turning them into all-sensing, always-learning fleets. Content:
This next-generation network technology won't just make our phones faster; it'll unlock new capabilities in robots, turning them into all-sensing, always-learning fleets. The confluence of two seemingly distinct technologies will result in new capabilities for robots. Why are there so many robots at a show focused on phones? This is the question I asked myself as I roamed the halls of Mobile World Congress, on the lookout for the most exciting technology that will define the next few years. The first and most obvious answer is that robots draw crowds. A dancing humanoid is an easy way to attract people to your booth. But to see the robots at this year's MWC purely as a publicity stunt would be to ignore the bigger conversation happening around robots and connectivity. Already in 2026, we've seen major leaps forward in robotics, with companies including Boston Dynamics and phone-maker Honor showing off humanoid robots designed for industry and home environments. But there is yet another level to unlock, and it relies on 6G -- the next-generation network technology set to succeed 5G in 2030 and beyond. On the surface, 6G and robotics might seem distinctly unrelated -- beyond being technologies of a future that we're not living in quite yet. But in this future, 6G will open new doors for humanoid robots that'll transform them from clunky, standalone mechanical figurines into efficient fleets, where individuals will form part of an all-sensing, always-learning ecosystem. This will happen first in industry, then in hospitality and care environments, before potentially landing in our homes. It's an exciting prospect, but as the experts I spoke to at MWC last month cautioned, there'll be some big leaps in technology required before they, and we, are ready for that. To understand how 6G will unlock new possibilities for robots, let's start with the special capabilities the network technology will have. The first is that 6G will act as a sensor network, with sensors embedded into both the robots and their environments, Qualcomm's executive vice president of Robotics Nakul Duggal told me. This allows the 6G radio to act like radar -- constantly scanning and mapping its surroundings in real time to detect obstacles. Imagine a robot attempting to navigate a crowded environment: The 6G network should quickly and cheaply help create a kind of virtual map for it to do so safely. Second, there's the pure speed at which 6G will communicate vast reams of data. The 5G networks we currently use aren't necessarily built to handle AI requests, but the 6G networks will be, providing a consistent, low-latency, relatively low-power way to process intelligence and deliver that intelligence to robots, according to Frank Long, associate director of intelligent services at deep tech research firm Cambridge Consultants. Private 5G networks combined with edge AI (relying on devices for computing, not just the cloud) can fill the gap for now, but public networks, not so much. By contrast, Long said, "with 6G you can pretty much have that quality of service guarantee." Cambridge Consultants brought a demo of an autonomous humanoid robot to MWC that can pick up and place down a box based on where it sees you pointing. The gesture recognition, plus the ability to react in real time, while varying its grip to pick up something that might be on an angle, requires an enormous amount of compute power. (The demo was powered by a private 5G network.) The robot was able to pick up this box and place it on a spot I pointed to. Whether robots are connected to the cloud, or to each other in a peer-to-peer fleet, the network will need to handle their intelligence demands at speed. For robots to be constantly talking to the infrastructure around them -- and to each other -- a strong, reliable uplink will be required, explained Anshuman Saxena, general manager of robotics at chipmaker Qualcomm. He gave the example of two robots working in a retail environment where one is unloading soda cans from a truck, and another is restocking shelves. They'll need to align on how to read the space around them to complete each task, including understanding how many cans will need placing, and when they'll be ready. "The only way is this robot, while shelving, goes to the back door entry of the truck that is getting unloaded and sees what is available," said Saxena. "Or the robot that's unloading is communicating the bigger picture to every other robot, so that we have a view of where the things are placed, so that they can plan." This is what's known as long-horizon planning, where a robot isn't just focusing on the immediate task but thinking about how that task fits into a broader context over a longer timeframe within a dynamic and unstructured environment. In other words, it's performing the kind of ongoing mental multitasking that humans do on a daily basis, reacting at speed to what's going on around us, while also considering what's next. In the Cambridge Consultant demo, the robot was capable of thinking 16 steps ahead. Meanwhile, lightning-fast 6G will help robots make split-second decisions, based on feedback not just from their own sensor-packed bodies, but from other robots and tech in the environment. "The retail stores have cameras," said Saxena. "It's not a robot, but it can be the eyes of the robot." In your own home, you might have only a single humanoid robot. But that won't be as different from the retail scenario as you may think. That's because many of the devices you own, including your phone and security cameras, can already communicate with each other, and the robot will be just another one in the mix. Or maybe you'll have one humanoid and a bunch of smaller robots designed for specific tasks. "There is a fleet aspect in the products that we use," Duggal said. "You don't feel that, but that is exactly how the product is working." Keep in mind that your phone is both a physical object itself and all the software and data that are managed elsewhere. The phone also provides feedback to refine that software, as will the 6G-equipped robots. "So a robot is going to be performing a certain physical task, and while it may perform it in your home, if it's also performing the same task in many other homes, there is this aspect of learning and deployment," Duggal said. This continuous learning is perhaps one of the biggest challenges that 6G is expected to help solve in robotics. Robots and AI will need massive amounts of real-world data that today's networks can't keep up with, even for mundane tasks. For example: picking up and serving you a cup of coffee, which involves dexterity and balance, with the added element of heat. A robotic arm might not care about the temperature. "But if it is hot, how would we react?" said Saxena. "We would just quickly leave it, which is a very fast reaction time." The speed of 6G networks will be essential. By the time a robot arrives in our homes, we will want to know that it shouldn't hand us a scalding-hot drink and how to protect itself from damage. Much of this learning might have taken place in hotels or restaurants, where overnight, robots load and unload dishwashers and reset the kitchen. The robot will bring that training into your home, where it'll still need to further learn about your unique layout and routine. This will likely be a time-consuming process. Qualcomm is working with several robotics companies, including Neura Robotics, which develops robots for both industrial and home use. "It's going to be incredibly challenging," said Long. "Put it this way, members of my immediate family still struggle with opening the baby gate in my stairs, even after extensive training. So a robot, I think, might be a few years away from opening that baby gate." But 6G is not expected to roll out widely until at least 2030. What are the robots that companies are already building and deploying to do until then? They're making the leaps and bounds they can with the networks of today. "So you're not waiting for 6G," Saxena said, "but when the connectivity comes along, you are talking about experiences which can be way beyond what robotics can do [today]." While the confluence of robotics and 6G will indeed unlock some hitherto unseen next-level robotics, there is plenty that robots can learn in the meantime -- particularly when it comes to improving dexterity -- to prime them to take advantage of better connectivity. That's especially true if we're ever to consider inviting humanoids into our homes, an idea that feels, at least for now, like something worth delaying until at least the 6G-enabled 2030s -- if not beyond.
Images (1): 
|
|||||
| Robots in Chinese literature circa 1902 | The Tangled Woof | https://andrewbatson.com/2022/06/07/rob… | 1 | May 03, 2026 08:00 | active | |
Robots in Chinese literature circa 1902 | The Tangled WoofURL: https://andrewbatson.com/2022/06/07/robots-in-chinese-literature-circa-1902/ Description: The concept of the "robot," a mechanical replacement for a human worker, seems to have been one of those things that was just in the air at the turn of the twentieth century, across the world. As is now well known, the English word was coined by the Czech writer Karel Capek (who credited his… Content:
The concept of the “robot,” a mechanical replacement for a human worker, seems to have been one of those things that was just in the air at the turn of the twentieth century, across the world. As is now well known, the English word was coined by the Czech writer Karel Capek (who credited his brother Josef for the inspiration, from the Czech word robota, forced labor). In the interesting short article, “Techno-Utopias And Robots In China’s Past Futures” in the new, free anthology Proletarian China: A Century of Chinese Labour, Craig A. Smith details the early history of robots in Chinese literature, which is not completely unlike the Western science fiction of the day. Here are some excerpts: The idea of animated or mechanical humanoid servants and labourers appeared in classical Chinese texts. Mozi, a utilitarian philosopher active in the fifth century BCE, even created mechanical birds and beasts, and is now the namesake of a technology company. However, the concept of a ‘machine-man’ (机器人, the modern Chinese word for robot) only made its way from elite texts into the popular imagination towards the end of the Qing Dynasty. Around the turn of the century, the entire world became fascinated with the idea of humanoid automatons and their potential for labour. The most memorable example of this in the West is the Tin Woodman from The Wonderful Wizard of Oz (1900), a depressed cyborg lumberjack yearning for a heart. Chinese fiction was in step and introduced labour automatons but with decidedly Chinese characteristics. In 1905 and 1906, the newspaper Southern News serialised a lengthy novel by Wu Jianren entitled The New Story of the Stone (新石头记). Although other Chinese science fiction writers penned stories with automatons at the time, Wu’s novel was a wonderland, its plot following Jia Baoyu, the protagonist of the eighteenth-century Dream of the Red Chamber (红楼梦), China’s most famous novel, into a twentieth-century technological utopia. Passing through a technological device called a ‘civilisation mirror’ (文明镜), Jia enters this utopia and is immediately served tea by a talking automaton ‘boy’ servant. The journey then proceeds through a melange of advanced technologies, including flying machines and submarines. It might have been around this time that Kang Youwei wrote the Book of Great Unity (大同书). The complete volume did not appear in regular print until 1935, eight years after his death, leading to controversy and numerous studies on the dating of the text. Tang Zhijun’s extensive research has shown that Kang most likely finished his manuscript in 1902, a finding corroborated by Wang Hui. Building on a few short chapters from [the Confucian classic] The Book of Rites (礼记), and contextualising these ideas within the modern reality of nation-states and new political economies, Kang envisioned a future world with no suffering. He saw robots playing an important role in his Confucian utopia, yet his position as a member of the literati class shaped his understanding of how robots would bring an end to the traditional hierarchies: ‘There will be no slaves or servants, but their functions will be performed by machines, shaped like birds and beasts.’ Kang imagined that ‘in the time of the Great Peace, there will be no suffering. Labourers will only find enjoyment.’ This will be possible because they will only put their skills to use in creating works ofart, as the heavy lifting will all be done by robots. Like H.G. Wells, Kang saw technological advancements bringing an end to toil and opening the door to universal leisure: ‘One will order by telephone, and food will be conveyed by mechanical devices—possibly a table will rise up from the kitchen below, through a hole in the floor. On the four walls will be lifelike, “protruding paintings”.’ This great trust in the emancipatory potential of science continued throughout the twentieth century, and revolutionaries, including Mao Zedong in his youth, found Kang’s work inspirational. However, largelydue to his promotion of constitutional monarchy, Kang is now remembered as a conservative opponent of revolution. Δ This site uses Akismet to reduce spam. Learn how your comment data is processed.
Images (1): 
|
|||||
| AI + Robotics: The Next Evolution After LLMs | https://www.c-sharpcorner.com/article/a… | 1 | May 02, 2026 00:00 | active | |
AI + Robotics: The Next Evolution After LLMsURL: https://www.c-sharpcorner.com/article/ai-robotics-the-next-evolution-after-llms/ Description: Explore the convergence of AI and robotics! Discover how AI is transforming robots into intelligent systems, enabling autonomous action and real-world impact. Content:
Artificial intelligence has rapidly evolved from simple rule-based systems to powerful large language models (LLMs). Now, the next major shift is happening at the intersection of AI and robotics. Companies like Google, Tesla, and Boston Dynamics are leading this transformation by combining intelligent software with physical machines.This convergence is enabling machines not just to think—but to act in the real world.What is AI + Robotics?AI + Robotics refers to the integration of:Artificial intelligence (decision-making, learning)Robotics (physical interaction, movement)Together, they create systems that can:Perceive their environmentMake decisionsPerform physical actionsThis goes beyond traditional automation by enabling adaptive and intelligent behavior.From LLMs to Physical IntelligenceLLM EraFocus on language understandingText generation and reasoningVirtual interactionsAI + Robotics EraReal-world perceptionPhysical task executionAutonomous systemsThis shift marks the transition from digital intelligence to physical intelligence.Key Components of AI-Powered Robotics1. Computer VisionRobots use AI to:Recognize objectsUnderstand environmentsTrack movement2. Motion PlanningAI helps robots:Plan pathsAvoid obstaclesOptimize movements3. Sensor IntegrationRobots rely on sensors such as:CamerasLiDARGPSAI processes this data to make decisions.4. Learning and AdaptationRobots can:Learn from experienceImprove performance over timeAdapt to new environmentsHow AI is Transforming RoboticsAutonomous Decision-MakingRobots can make decisions without human control, enabling:Self-driving vehiclesAutonomous dronesSmart manufacturing systemsReal-Time ProcessingAI allows robots to:Analyze data instantlyRespond to changesOperate efficiently in dynamic environmentsHuman-Robot CollaborationAI enables robots to:Work alongside humansAssist in complex tasksImprove productivityReal-World Use CasesManufacturingAutomated assembly linesQuality inspection systemsPredictive maintenanceHealthcareSurgical robotsPatient care assistanceMedical diagnostics supportLogistics and WarehousingAutonomous delivery robotsInventory managementWarehouse automationAutonomous VehiclesSelf-driving carsDelivery dronesSmart transportation systemsAdvantages of AI + RoboticsIncreased efficiency and productivityAbility to perform dangerous tasksReduced human errorContinuous operation without fatigueScalability across industriesChallenges and RisksHigh development and deployment costsSafety concerns in real-world environmentsEthical issues around automationDependency on high-quality dataComplex system integrationDevelopers must consider these challenges when building robotic systems.AI + Robotics vs Traditional RoboticsFeatureTraditional RoboticsAI-Powered RoboticsFlexibilityLowHighDecision MakingPre-programmedIntelligentAdaptabilityLimitedContinuous learningUse CasesRepetitive tasksComplex environmentsEfficiencyModerateHighAI is transforming robots from rigid machines into intelligent systems.Impact on DevelopersNew Skill RequirementsDevelopers need to learn:AI and machine learningRobotics frameworksSensor integrationReal-time systemsCross-Disciplinary KnowledgeAI + Robotics requires understanding of:Software engineeringHardware systemsData processingOpportunities for InnovationDevelopers can build:Autonomous systemsSmart devicesIntelligent applicationsFuture of AI + RoboticsThe future of this field is highly promising. We can expect:Fully autonomous factoriesAdvanced humanoid robotsSmart cities with robotic infrastructureAI-driven logistics and transportationIntegration with IoT and cloud systemsAI + Robotics will redefine industries and everyday life.SummaryAI + Robotics represents the next major evolution after large language models. By combining intelligent decision-making with physical capabilities, these systems can interact with the real world in ways that were not possible before.For developers, this opens up new opportunities to build innovative and impactful solutions. While challenges exist, the potential of AI-powered robotics makes it one of the most exciting areas in modern technology. Artificial intelligence has rapidly evolved from simple rule-based systems to powerful large language models (LLMs). Now, the next major shift is happening at the intersection of AI and robotics. Companies like Google, Tesla, and Boston Dynamics are leading this transformation by combining intelligent software with physical machines. This convergence is enabling machines not just to think—but to act in the real world. AI + Robotics refers to the integration of: Artificial intelligence (decision-making, learning) Robotics (physical interaction, movement) Together, they create systems that can: Perceive their environment Make decisions Perform physical actions This goes beyond traditional automation by enabling adaptive and intelligent behavior. Focus on language understanding Text generation and reasoning Virtual interactions Real-world perception Physical task execution Autonomous systems This shift marks the transition from digital intelligence to physical intelligence. Robots use AI to: Recognize objects Understand environments Track movement AI helps robots: Plan paths Avoid obstacles Optimize movements Robots rely on sensors such as: Cameras LiDAR GPS AI processes this data to make decisions. Robots can: Learn from experience Improve performance over time Adapt to new environments Robots can make decisions without human control, enabling: Self-driving vehicles Autonomous drones Smart manufacturing systems AI allows robots to: Analyze data instantly Respond to changes Operate efficiently in dynamic environments AI enables robots to: Work alongside humans Assist in complex tasks Improve productivity Automated assembly lines Quality inspection systems Predictive maintenance Surgical robots Patient care assistance Medical diagnostics support Autonomous delivery robots Inventory management Warehouse automation Self-driving cars Delivery drones Smart transportation systems Increased efficiency and productivity Ability to perform dangerous tasks Reduced human error Continuous operation without fatigue Scalability across industries High development and deployment costs Safety concerns in real-world environments Ethical issues around automation Dependency on high-quality data Complex system integration Developers must consider these challenges when building robotic systems. AI is transforming robots from rigid machines into intelligent systems. Developers need to learn: AI and machine learning Robotics frameworks Sensor integration Real-time systems AI + Robotics requires understanding of: Software engineering Hardware systems Data processing Developers can build: Autonomous systems Smart devices Intelligent applications The future of this field is highly promising. We can expect: Fully autonomous factories Advanced humanoid robots Smart cities with robotic infrastructure AI-driven logistics and transportation Integration with IoT and cloud systems AI + Robotics will redefine industries and everyday life. AI + Robotics represents the next major evolution after large language models. By combining intelligent decision-making with physical capabilities, these systems can interact with the real world in ways that were not possible before. For developers, this opens up new opportunities to build innovative and impactful solutions. While challenges exist, the potential of AI-powered robotics makes it one of the most exciting areas in modern technology. ©2026 C# Corner. All contents are copyright of their authors.
Images (1): 
|
|||||
| Zalando to install up to 50 AI-powered Nomagic robots in … | https://www.manilatimes.net/2026/03/20/… | 0 | May 01, 2026 16:00 | active | |
Zalando to install up to 50 AI-powered Nomagic robots in its European fulfilment centresDescription: Zalando is supercharging its logistics backbone with the roll-out of up to 50 AI-driven Nomagic robots across its European fulfilment network. This expansion al... Content: |
|||||
| Dogonić legendę. Chiński humanoid od Unitree biega niemal tak szybko … | https://www.chip.pl/2026/04/chinski-hum… | 1 | Apr 30, 2026 00:00 | active | |
Dogonić legendę. Chiński humanoid od Unitree biega niemal tak szybko jak Usain BoltURL: https://www.chip.pl/2026/04/chinski-humanoid-od-unitree-biega-niemal-tak-szybko-jak-usain-bolt Description: Jesteśmy coraz bliżej momentu, w którym roboty zaczną poruszać się z gracją i prędkością profesjonalnych lekkoatletów. Jedną z firm, która w niebezpiecznie Content:
Najnowsze nagranie jest tego dowodem. Widzimy na nim robota, który podczas testów na bieżni lekkoatletycznej osiągnął zawrotną prędkość sprintu wynoszącą 10 metrów na sekundę. Na tym oczywiście nie koniec, bo cel firma ma ambitny – pobić rekord ustanowiony przez Usaina Bolta. Osiągnięcie prędkości 10 m/s (co przekłada się na około 36 km/h) to wynik, który oszałamia i niebezpiecznie zbliża maszynę do rekordu świata, który Usain Bolt ustanowił w 2009 roku – 100 metrów w 9,58 s ze średnią pęskością 10,44 metrów na sekundę. Robot Unitree jest więc o krok od dorównania legendzie. Co ciekawe, urządzenie pomiarowe na bieżni wskazało w pewnym momencie nawet 10,1 m/s, choć firma zachowuje chłodną głowę i zaznacza, że mogło dojść do drobnego błędu pomiarowego. Żeby jeszcze lepiej uzmysłowić Wam skalę postępu w tej dziedzinie – zaledwie rok temu rekord świata dla pełnowymiarowych humanoidów wynosił skromne 3,3 m/s. Skok wydajności, jakiego dokonało Unitree w ciągu kilkunastu miesięcy, jest po prostu bezprecedensowy. Firma zdetronizowała słynnego Atlasa od Boston Dynamics, który poruszał się z prędkością około 2,5 m/s. Ale plany firmy są jeszcze większe, bo zgodnie z zapowiedziami, jeszcze w tym roku zobaczymy, jak ich maszyny złamią barierę 10 sekund w biegu na 100 metrów. Czytaj też: Robot z AliExpress? Unitree wprowadza model R1 na globalny rynek Unitree nie jest jednak jedyną firmą, która chce uczynić ze swoich robotów prawdziwych sprinterów. Rywalizacja w Chinach przypomina prawdziwe igrzyska olimpijskie dla maszyn. Podczas World Humanoid Robot Games 2025, model Tien Kung Ultra wygrał bieg na 100 metrów z czasem 21,50 sekundy, a w kwietniu zeszłego roku ten sam robot ukończył pierwszy na świecie półmaraton dla humanoidów w czasie 2 godzin i 40 minut. Z kolei w lutym tego roku firma MirrorMe zaprezentowała model Bolt, który przy wzroście 175 cm również potrafi rozpędzić się do 10 m/s. Czytaj też: Panther to pierwszy robot humanoidalny, który naprawdę posprząta Twój dom Na tym nie koniec, bo już 19 kwietnia odbędzie się druga edycja Humanoid Robot Half Marathon w Pekinie, gdzie ponad 70 zespołów przeprowadzało nocne testy na torach w strefie technologicznej. Eksperci przewidują, że masowy start kilkudziesięciu robotów biegających ramię w ramię będzie widokiem, który na stałe zmieni nasze postrzeganie robotyki. Źródło: Unitree Portal technologiczny z ponad 29-letnią historią, piszący o nauce i technice, smartfonach, motoryzacji, fotografii. Technologie mamy we krwi!
Images (1): 
|
|||||
| Walmart-backed robotics group Symbotic in $4.5bn talks to merge with … | https://news.sky.com/story/walmart-back… | 0 | Apr 29, 2026 16:00 | active | |
Walmart-backed robotics group Symbotic in $4.5bn talks to merge with SoftBank SPACDescription: A supplier of robots to Walmart distribution centres is in talks to merge with a SoftBank-sponsored special purpose acquisition company that would value it at a... Content: |
|||||
| Subscribe to read | https://www.ft.com/content/e1da7cbc-5c1… | 1 | Apr 29, 2026 16:00 | active | |
Subscribe to readURL: https://www.ft.com/content/e1da7cbc-5c12-4d82-bfc8-de3d80e4475a Description: Japanese investor has raised multiple Spacs and has been looking for a deal as market cools Content:
Then €69 per month. Complete digital access to quality FT journalism on any device. Cancel anytime during your trial. Essential digital access to quality FT journalism on any device. Pay a year upfront and save 20%. Complete digital access to quality FT journalism with expert analysis from industry leaders. Pay a year upfront and save 20%. FT Weekend newspaper delivered Saturday plus complete digital access. Check whether you already have access via your university or organisation. Terms & Conditions apply Discover all the plans currently available in your country Digital access for organisations. Includes exclusive features and content. See why over a million readers pay to read the Financial Times.
Images (1): 
|
|||||