AUTOMATION HISTORY
1191
Total Articles Scraped
2288
Total Images Extracted
Scraped Articles
New Automation| Action | Title | URL | Images | Scraped At | Status |
|---|---|---|---|---|---|
| Mignons, bien finis, programmables, on a essayé les robots Pixar … | https://www.bfmtv.com/tech/objets-conne… | 1 | Mar 07, 2026 00:03 | active | |
Mignons, bien finis, programmables, on a essayé les robots Pixar du chinois Robosen, ont-ils ce qu'il faut pour illuminer votre Noël?Description: Pour les fêtes de fin d'année, la marque chinoise spécialisée dans la robotique, Robosen, lance une collection de mini robots connectés utilisant les personnages de Pixar. Tech&Co vous livre son avis. Content:
Si les enfants des années 90 et 2000 se souviennent sans doute du Furby, un petit animal robotisé aux multiples mimiques, ceux des années 2020 pourraient de leur côté porter un grand intérêt aux produits signés par l'entreprise chinoise Robosen. Pour cette fin d'année 2025, c'est une collection Pixar qui attend les plus jeunes (mais aussi les fans) pour un prix loin d'être aussi exorbitant que les robots les plus intelligents que l'on peut déjà trouver sur le marché. Des mini-robots que Tech&Co a pu prendre en main, et qui ont la particularité de pouvoir être personnalisés en fonction des besoins, bien qu'ils ne soient pas aussi évolués que d'autres modèles bien plus onéreux. Concrètement, chaque personnage est vendu séparément et peut être placé sur un socle qui viendra l'alimenter. Ils ne peuvent pas bouger sur un bureau, contrairement à certains petits robots de compagnie comme Emo ou Eilik. En revanche, ils disposent d'un certain nombre de mouvements et s'accompagnent d'une série de sons (en français, avec les voix officielles des films Pixar) qui peuvent être joués à la demande. Pour ce faire, il suffit d'appuyer sur le bouton "Lecture" du socle sur lequel on pose la figurine. Parmi les personnages disponibles, on peut compter sur Woody, Buzz l'éclair, Lotso, le petit alien ou encore Rex et Jessie de Toy Story. A cela s'ajoutent Wall-E et Eve du film éponyme. Sur le moment, on s'en amuse. Les petits mouvements fonctionnent bien avec les différents sons disponibles par défaut. Il y a aussi un réel souci du détail. Lotso, par exemple, a l'odeur de fraise qu'est censé dégager le personnage dans le film (mais aussi les peluches vendues en magasin). Robosen n'a pas simplement mis quelques rouages et engrenages dans ses robots, il y en a à tous les niveaux: les bras, les sourcils ou encore les chapeaux. On constate un effort de réalisme par rapport à l'antique Furby qui avait fait le bonheur des enfants aujourd'hui adultes. Mais une fois qu'on a fait le tour des voix, que faire? C'est là que le site Robosen Studio entre en jeu. Il nécessite un compte et ne fonctionne que sur les navigateurs Chromium, comme Chrome, Edge, ou la plupart des navigateurs actuels à l'exception de Safari et Firefox. Vous devez simplement connecter la base (avec un personnage dessus) via un câble USB-C pour ensuite avoir la possibilité d'importer un fichier audio. Une musique, un message particulier ou encore un son trouvé sur internet, tout est possible. En revanche, le robot ne permet pas de modifier, ou ne serait-ce que raccourcir le fichier qui lui est soumis. Prévoyez donc un peu de montage sur Audacity par exemple. Et pour préservez la magie auprès de votre enfant, il faudra y mettre des fichiers reprenant les voix des personnages que vous détenez. Une fois le fichier téléchargé, le logiciel accessible depuis le navigateur vous propose de caler le rythme du son sur une série de mouvements préprogrammés. Mais il est aussi possible de personnaliser les séquences. L'interface est loin d'être compliquée à comprendre, mais elle n'est pas facile pour autant. Il faudra obligatoirement un adulte pour s'occuper de cette partie de l'utilisation: on imagine mal un enfant se mettre à programmer ce personnage. Pas besoin d'être un expert en Python pour autant. S'il est suffisamment à l'aise avec une interface web et sait lire, il devrait pouvoir se débrouiller rapidement seul, une fois que vous l'aurez accompagné. Car si l'interface n'est pas agaçante, elle demande tout de même des manipulations complexes pour réussir à avoir un résultat convaincant, pour peu que l'on se décide à gérer les mouvements de A à Z - cela peut aller jusqu'à une trentaine de manipulations de différentes jauges, des temps de mouvement aux minuteurs liés au rythme du son utilisé. On peut néanmoins imaginer un parent le faire avec son enfant, de quoi amuser la galerie. Surtout, on peut aussi profiter des contenus partagés par la communauté en cas de panne d'inspiration. Les mini-robots de Robosen doivent donc être vus comme un premier pas vers de la robotique plus évoluée. Il ne s'agit pas d'écrire du code, mais l'interface est suffisamment évoluée pour permettre de personnaliser les mouvements comme bon nous semble, avec les limitations que l'on peut imaginer compte tenu du prix relativement bas de ces mini-robots. De plus, on doutera tout de même de l'intérêt sur le moyen terme, si bien qu'il ne serait pas étonnant qu'au final, cela devienne davantage des figurines d'exposition qu'un robot que l'on active régulièrement. Robosen ne s'en cache d'ailleurs pas: ils visent avant tout les fans des licences qu'ils commercialisent, et compte tenu des prix d'une jolie figurine, ces mini-robots ne sont pas si onéreux. Sont-ils rentables? Absolument pas. Mais les parents fans de Pixar pourront toujours se trouver une excuse et se dire qu'ils initient leurs enfants à la robotique. C'est en partie faux, mais on ne les jugera pas. La marque commercialise déjà des modèles bien plus convaincants, mais aussi bien plus onéreux. C'est le cas avec ses produits Transformers, qui peuvent se transformer automatiquement, mais qui peuvent coûter jusqu'à 1.799 euros. Le Buzz l'éclair avec 23 articulations intelligentes, et donc un rendu forcément plus premium, est quant à lui proposé à 599 euros. Au-delà de l'intérêt qui ne sera pas évident pour tous, ces mini-robots souffrent toutefois d'un manque d'interaction avec leur environnement. Robosen ne vendant pas (encore?) de socle supplémentaire en plus de celui que vous recevez dans un pack de départ, il ne sera même pas possible de faire interagir les personnages entre eux. Ils ne sont d'ailleurs pas programmés pour: si ce n'est Wall-E et Eve qui disposent "d'effets synchronisés", aucun autre personnage ne semble vraiment fait pour converser avec ses camarades, et il n'y a d'ailleurs pas de micro pour qu'ils puissent le faire dans le futur. Sur ce point, Furby faisait mieux puisqu'il proposait une telle option il y a de cela plusieurs années. Son propriétaire humain ne pourra pas non plus "discuter" avec lui. Plutôt objets de collection ou cadeaux étonnants à faire, les mini-robots de Robosen ont surtout pour eux leur prix d'appel. Avec un tarif démarrant à 90 euros (à peine plus cher qu'un Furby), on ne peut pas dire que l'entreprise n'a pas fait un effort pour attirer le geek ou l'enfant qui sommeille en nous. Casques bleus blessés, Beyrouth massivement bombardé, Poutine appelle à un cessez-le-feu... Ce qu'il faut retenir du septième jour de la guerre au Moyen-Orient © Copyright 2006-2026 BFMTV.com. Tous droits réservés. Site édité par NextInteractive
Images (1): 
|
|||||
| Are We Going Too Far By Allowing Generative AI To … | https://www.forbes.com/sites/lanceeliot… | 0 | Mar 07, 2026 00:03 | active | |
Are We Going Too Far By Allowing Generative AI To Control Robots, Worriedly Asks AI Ethics And AI LawDescription: Generative AI such as ChatGPT is increasingly being used to control robots. This bodes for concern since the AI might produce faulty instructions and endanger h... Content: |
|||||
| Robots aspirateurs, automatisations et énergie : ce que change la … | https://www.maison-et-domotique.com/168… | 1 | Mar 07, 2026 00:03 | active | |
Robots aspirateurs, automatisations et énergie : ce que change la mise à jour Home Assistant 2026.3 - Maison et DomotiqueDescription: Home Assistant 2026.3 apporte le nettoyage pièce par pièce pour les aspirateurs robots, un assistant vocal Android avec wake word local, des automatisations plus fiables et de nombreuses améliorations de l’interface et de l’énergie. Content:
La mise à jour Home Assistant 2026.3 est disponible et poursuit la cadence mensuelle du projet. Cette version n’est pas centrée sur une seule grosse nouveauté spectaculaire, mais sur une multitude d’améliorations concrètes issues de la communauté. L’équipe s’est d’ailleurs volontairement concentrée sur l’intégration de contributions open-source en attente afin d’enrichir l’écosystème. Au final, le résultat est impressionnant : nouvelles possibilités pour les aspirateurs robots, amélioration des automatisations, évolution du tableau de bord énergie, intégration du wake word Android et une longue liste d’intégrations supplémentaires. Voyons les nouveautés les plus marquantes. L’une des nouveautés les plus pratiques concerne les robots aspirateurs. Jusqu’ici, lancer le nettoyage d’une pièce précise n’était pas toujours simple depuis Home Assistant, même si les applications des fabricants proposaient cette fonction. La version 2026.3 introduit un système officiel permettant d’associer les pièces de la carte du robot aspirateur aux zones définies dans Home Assistant. Concrètement, si votre robot a identifié les pièces de votre maison (salon, cuisine, bureau…), il est désormais possible de les mapper directement avec les zones de Home Assistant. Une fois cette correspondance créée, de nouvelles actions apparaissent dans les automatisations. Vous pouvez par exemple déclencher une action du type : Et le robot ira directement dans la zone concernée. Cela ouvre aussi la porte à des scénarios très pratiques : Un scénario peut lancer automatiquement le nettoyage de la cuisine après le dîner. Un autre peut nettoyer le bureau uniquement les jours de télétravail. Ou encore déclencher un nettoyage ciblé lorsque la présence détecte que toute la famille est sortie. Pour l’instant, cette fonctionnalité est supportée par plusieurs intégrations populaires comme Roborock, Ecovacs et Matter, mais d’autres devraient suivre rapidement. Les automatisations gagnent un nouvel outil très utile : Continue on error. Dans Home Assistant, lorsqu’une action échoue dans une automatisation, l’exécution s’arrête généralement immédiatement. Cela peut poser problème dans certains scénarios critiques. Prenons un exemple concret. Vous avez une automatisation de sécurité qui doit : Si l’allumage d’une lampe échoue pour une raison quelconque (ampoule déconnectée, appareil indisponible), l’automatisation pouvait s’interrompre avant l’envoi de la notification. Avec cette nouvelle option, il est désormais possible de dire à Home Assistant de continuer l’exécution même si une action échoue. Cette fonctionnalité existait déjà en YAML depuis longtemps, mais elle devient maintenant accessible directement dans l’interface graphique des automatisations. Résultat : des scénarios plus fiables et plus faciles à construire. Autre nouveauté majeure : l’application Android de Home Assistant introduit le wake word local. Concrètement, votre smartphone peut désormais écouter un mot clé (comme “Hey Jarvis”) et déclencher l’assistant vocal sans avoir à toucher l’écran. La détection se fait directement sur le téléphone, sans passer par le cloud. Cela repose sur le moteur open-source Micro Wake Word développé pour le projet. Une fois activée, l’expérience devient très proche des assistants vocaux classiques : Vous pouvez par exemple dire : “Hey Jarvis, allume la lumière du salon” Le téléphone capte la commande, l’envoie à Home Assistant et exécute l’action. Cette fonctionnalité présente plusieurs avantages intéressants. Elle permet de transformer un ancien smartphone ou une tablette Android en assistant vocal mural. Parfait pour créer un point de contrôle dans une pièce sans acheter de matériel supplémentaire. Elle fonctionne aussi même sans connexion Internet, puisque la détection du mot clé est locale. Le seul inconvénient pour l’instant concerne la consommation de batterie. Le système peut utiliser environ 15 % de batterie par jour, car Android ne permet pas encore d’utiliser les puces spécialisées de détection vocale. À noter : cette fonction n’est malheureusement pas possible sur iOS, Apple ne permettant pas ce type d’accès aux applications tierces. Le tableau de bord énergie continue d’évoluer lui aussi. Plusieurs améliorations rendent l’interface plus claire et plus pratique à utiliser. La première concerne l’organisation des données. L’onglet principal est désormais nommé Électricité au lieu de “Énergie”, afin d’éviter toute confusion avec les autres sources comme le gaz ou l’eau. Les graphiques gagnent aussi en lisibilité. Lorsque vous survolez un histogramme, la date exacte apparaît désormais dans l’infobulle, ce qui permet d’identifier immédiatement le jour correspondant. Autre nouveauté intéressante : les badges en haut du tableau affichent maintenant les valeurs instantanées comme la puissance actuelle ou le débit d’eau. Cela permet de voir en un coup d’œil la consommation en temps réel. Pour ceux qui utilisent Home Assistant pour optimiser leur facture énergétique (solaire, délestage, suivi de consommation…), ces petits détails rendent l’analyse beaucoup plus confortable. Le tableau de bord principal reçoit lui aussi quelques améliorations. La barre latérale peut maintenant afficher : Ces informations apparaissent directement dans le résumé du système. Autre détail pratique : les fenêtres ouvertes peuvent désormais apparaître dans la section sécurité. Un rappel utile avant de quitter la maison. Les dashboards Home Assistant introduisent également une nouveauté intéressante : le footer personnalisable. En plus du header, il est désormais possible d’ajouter un pied de page contenant n’importe quelle carte. Cela permet par exemple d’y placer : Cette zone reste visible en bas de l’écran et peut servir de raccourci permanent vers certaines actions importantes. Une amélioration simple… mais qui ouvre beaucoup de possibilités pour organiser ses interfaces. Sous le capot, Home Assistant passe à Python 3.14. Ce genre de changement peut sembler anodin, mais il a un impact direct sur les performances globales du système. Les nouvelles versions de Python apportent régulièrement des optimisations importantes. Comme Home Assistant repose entièrement sur ce langage, toute amélioration profite automatiquement à l’ensemble du système. Résultat : démarrage plus rapide, scripts plus réactifs et utilisation plus fluide. Comme souvent, la mise à jour apporte aussi une longue liste de nouvelles intégrations. Parmi les plus intéressantes : Cette version met clairement en avant la force de l’écosystème : la communauté open-source. De nombreux développeurs ont contribué à enrichir la plateforme, ce qui explique la taille impressionnante de la liste d’améliorations. La version 2026.3 ne cherche pas à impressionner avec une seule fonctionnalité spectaculaire. Elle améliore plutôt des dizaines de petits détails qui rendent Home Assistant plus agréable au quotidien. Entre le contrôle pièce par pièce des aspirateurs robots, l’assistant vocal Android, les automatisations plus robustes et les améliorations du tableau énergie, cette version apporte des outils très concrets pour automatiser la maison. Et comme souvent avec Home Assistant, ce n’est qu’un aperçu de ce qui arrive : plusieurs évolutions importantes autour des automatisations et de la voix sont déjà en préparation pour les prochaines mises à jour. On a hâte ! Pour ceux qui veulent tester les nouveautés, l’environnement de tests Home Assistant a été mis à jour dans la foulée ;-) Tags : home assistant Saisissez votre réponse en chiffreshuit + seize = Toutes les marques citées, noms de produits ou de services, ainsi que les logos sont les propriétés de leurs sociétés respectives. L’auteur ne saurait être tenu responsable d’un quelconque dommage subi, manque à gagner ou d’une quelconque perte de données consécutives à une manipulation décrite dans ce blog. Nous déclinons également toute responsabilité vis-à-vis des erreurs ou omissions détectées sur ce blog. Nous nous engageons, sans aucune obligation, à modifier le contenu, à améliorer le blog et à corriger toute erreur ou omission, à tout moment et sans préavis. Nous nous efforcerons d’actualiser les informations en temps utile sans toutefois être responsables d’éventuelles inexactitudes.
Images (1): 
|
|||||
| Programmable Robots Market Size to Worth USD US$ 10.2 | https://www.globenewswire.com/news-rele… | 1 | Mar 07, 2026 00:03 | active | |
Programmable Robots Market Size to Worth USD US$ 10.2Description: The Programmable Robots Market is experiencing robust growth fueled by increasing adoption in education, industry, and continuous technological... Content:
January 24, 2024 05:39 ET | Source: Persistence Market Research Persistence Market Research New York, Jan. 24, 2024 (GLOBE NEWSWIRE) -- Programmable robots are witnessing increasing adoption across educational institutions, commercial enterprises, and industrial settings. The global market for programmable robots is anticipated to reach US$ 3.2 billion by 2023, with a projected compound annual growth rate (CAGR) of 12.1%. By 2033, the industry is expected to achieve sales of US$ 10.2 billion Research has unveiled the potential of using biodegradable components to create artificial muscles, paving the way for compostable robots in the future. Soft robotics, which focuses on designing robots from flexible and pliable materials like elastomers, hydrogels, and textiles, is a growing field. The increasing adoption of programmable robots across educational institutions, commercial sectors, and industrial settings is driving the demand for these robots. Continuous technological advancements and innovations in these domains are propelling market growth. The rise in the global programmable robots market is attributed to the mounting adoption of automation in manufacturing facilities, rising awareness regarding the benefits of artificial intelligence (AI), and the advent of deep learning systems. The demand for these robots is likely to increase in the future owing to their ability to handle any job as programmed or instructed to them via programming languages such as C/C++, Java, and Python. These robots can efficiently manage tasks such as packing, sorting, and others without human intervention and error and help the players maximize their profits. Such adoption of robotics solutions for the e-commerce industry fuels the programmable robots market growth. With the increasing adoption of programmable robots in educational institutions, commercial sectors, and industrial environments, the demand for such robots is poised for growth, driven by ongoing technological advancements and innovations. Recent research has showcased the potential of biodegradable components in constructing artificial muscles, paving the way for the development of compostable robots in the future. The emerging field of soft robotics is dedicated to crafting robots from materials like elastomers, hydrogels, and textiles, imparting flexibility and softness to their designs. In response to these challenges, a new generation of materials and manufacturing techniques is being explored, including shape-memory polymers and programmable textiles capable of changing shape. For example, researchers led by Ellen Rumley, a graduate student at CU Boulder, are actively working on biodegradable artificial muscles. These muscles enable robotic arms and legs to mimic lifelike movements and eventually biodegrade into the soil over time. This breakthrough addresses the issues of technological waste and unsustainable disposal practices, marking a significant advancement in the field of robotics Seeking Deeper Insights into Competitor Analysis? Request a Sample of the Report Now! https://www.persistencemarketresearch.com/samples/33467 Programmable Robots Market Report Scope: Programmable Robots: Market Dynamics: The rapid advancement of technology, driven by developments in robotics, artificial intelligence, and deep learning systems, is a driving force behind the expanding programmable robots market. Continuous research and development efforts will further bolster this market in the coming years. Programmable robots are gaining popularity in research and education, offering a versatile platform for understanding and developing robotic technology. Their adaptability across a wide range of tasks positions them for increasing prominence. From artificial intelligence-enabled robots to drones, programmable robots are finding applications in industries like housecleaning, administration, and security, including bomb detection and disposal. These robots offer efficiency and precision, particularly in manufacturing, where they excel at repetitive and error-free tasks. Their adaptability and reconfigurability make them valuable assets in various industrial processes, enhancing flexibility and productivity. The growing automation, the growing popularity of robots for educational purposes, and the rising Internet of Things technology. However, the high cost of robots is expected to hinder the growth of the market. Programmable robots are a powerful tool to make Science, Technology, Engineering, and Mathematics (STEM) education more interactive and fun for kids and students of different age groups. These robots assist children in learning all the aspects of electronics coding, engineering, and computer science. It helps children to develop one of the basic and crucial cognitive skills of mathematical and computational thinking at a very early age. These skills help them to develop the mental capability to solve problems of various kinds through an orderly series of actions. LEGO Mindstorms, Sphero, Dash and Dot, Ozobot, and VEX Robotics are some of the educational programmable robots that can be controlled via smartphone or tablet and are equipped with sensors and cameras. These robots help students to develop and learn skills in analytical, critical, practical, and creative thinking, which leads to their adoption in research and education and further fosters the programmable robots market growth. The rising awareness of practical learning is one of the major driving factors anticipated to boost the programmable robots market growth exponentially. In addition, the advancement of programmable robots transformed the way children use to get educated. Children of all age groups, ranging from kindergarten to graduate universities, benefitted from the learning with the help of programmable robots. Governments, schools, and universities are making efforts to integrate robotics learning into their education system to develop cognitive skills and learning in children and students. A large number of educational robotics (ER) initiatives have been implemented to teach and motivate learners of different age groups. For example, Fischertechnik’s learning environment supports the learning and teaching materials and kits for STEM, technology & programming. It is used for learning and understanding various industry 4.0 applications via various schools and training sessions. Thus, such application of programmable robots and initiatives to promote robotics fuels the adoption and development of robots, which further fuels the programmable robots market. In a nutshell, the Persistence Market Research report is a must-read for start-ups, industry players, investors, researchers, consultants, business strategists, and all those who are looking to understand this industry. Get a glance at the report at - https://www.persistencemarketresearch.com/market-research/programmable-robots-market.asp This growth is fueled by continuous technological advancements and innovations in the field, making programmable robots more versatile and capable than ever before. A noteworthy development in this market is the exploration of biodegradable components for creating artificial muscles, opening up possibilities for compostable robots in the future. Additionally, the emerging field of soft robotics is revolutionizing robot design by using flexible and pliable materials, such as elastomers, hydrogels, and textiles. To meet the challenges of creating these advanced robots, researchers are exploring new materials like shape-memory polymers and programmable textiles that can change shape as needed. This market is not only pushing the boundaries of technology but also addressing environmental concerns, as biodegradable components pave the way for robots that can naturally decompose, reducing technological waste and contributing to a more sustainable future. The Programmable Robots Market is a testament to the boundless potential of robotics in various industries, from education to healthcare and beyond. Competitive Landscape The programmable robot market sees numerous technology companies vying for dominance. Success in this competitive arena necessitates offering a diverse product range, effective marketing strategies, and a high level of technical expertise. Collaborative efforts between companies to leverage their strengths often result in the development of innovative products. Research and development are pivotal in the creation of new products and technologies that confer a competitive edge. Companies continually seek ways to enhance existing products or introduce novel ones to maintain their competitive stance. In April 2023, SynSense, a pioneer in neuromorphic chips, announced plans to secure over 200 million RMB ($29 million) in B-round financing. Zurich-based Maxvision secured $10 million in funding in March through Ausvic Capital, followed by an undisclosed investment in April from Chinese venture capital firm RunWoo and multimodal biometrics firm Maxvision. In May 2023, Sphero RVR+ unveiled its latest and most advanced robot, designed for middle and high schools, as well as makerspaces. The Sphero RVR+ Multi-Pack, designed for classrooms, equips teachers with six RVR+ robots and an Educator Guide featuring step-by-step activities. This multi-pack option enables educators to seamlessly integrate computer science concepts into their middle and high school classrooms and makerspaces, requiring no prior programming experience Programmable Robots Market Outlook by Category By Component: By Application: By Region: About Persistence Market Research: Business intelligence is the foundation of every business model employed by Persistence Market Research. Multi-dimensional sources are being put to work, which include big data, customer experience analytics, and real-time data collection. Thus, working on “micros” by Persistence Market Research helps companies overcome their “macro” business challenges. Persistence Market Research is always way ahead of its time. In other words, it tables market solutions by stepping into the companies’/clients’ shoes much before they themselves have a sneak pick into the market. The pro-active approach followed by experts at Persistence Market Research helps companies/clients lay their hands on techno-commercial insights beforehand, so that the subsequent course of action could be simplified on their part. Contact Us: Persistence Market ResearchTeerth Technospace, Unit B-704Survey Number - 103, BanerMumbai Bangalore HighwayPune 411045, IndiaEmail: sales@persistencemarketresearch.comWeb: https://www.persistencemarketresearch.com
Images (1): 
|
|||||
| Home Assistant 2026.3 trae control por voz en Android y … | https://www.redeszone.net/noticias/lanz… | 1 | Mar 07, 2026 00:03 | active | |
Home Assistant 2026.3 trae control por voz en Android y un cambio crítico en PythonDescription: Controla tu aspirador por zonas, vigila el consumo en tiempo real y usa la voz en Android. Descubre las novedades de la última versión de Home Assistant. Content:
Navegar por redeszone.net con publicidad personalizada, seguimiento y cookies de forma gratuita. i Para ello, nosotros y nuestros socios i necesitamos tu consentimiento i para el tratamiento de datos personales i para los siguientes fines: Las cookies, los identificadores de dispositivos o los identificadores online de similares características (p. ej., los identificadores basados en inicio de sesión, los identificadores asignados aleatoriamente, los identificadores basados en la red), junto con otra información (p. ej., la información y el tipo del navegador, el idioma, el tamaño de la pantalla, las tecnologías compatibles, etc.), pueden almacenarse o leerse en tu dispositivo a fin de reconocerlo siempre que se conecte a una aplicación o a una página web para una o varias de los finalidades que se recogen en el presente texto. La mayoría de las finalidades que se explican en este texto dependen del almacenamiento o del acceso a la información de tu dispositivo cuando utilizas una aplicación o visitas una página web. Por ejemplo, es posible que un proveedor o un editor/medio de comunicación necesiten almacenar una cookie en tu dispositivo la primera vez que visite una página web a fin de poder reconocer tu dispositivo las próximas veces que vuelva a visitarla (accediendo a esta cookie cada vez que lo haga). La publicidad y el contenido pueden personalizarse basándose en tu perfil. Tu actividad en este servicio puede utilizarse para crear o mejorar un perfil sobre tu persona para recibir publicidad o contenido personalizados. El rendimiento de la publicidad y del contenido puede medirse. Los informes pueden generarse en función de tu actividad y la de otros usuarios. Tu actividad en este servicio puede ayudar a desarrollar y mejorar productos y servicios. La publicidad que se presenta en este servicio puede basarse en datos limitados, tales como la página web o la aplicación que esté utilizando, tu ubicación no precisa, el tipo de dispositivo o el contenido con el que está interactuando (o con el que ha interactuado) (por ejemplo, para limitar el número de veces que se presenta un anuncio concreto). La información sobre tu actividad en este servicio (por ejemplo, los formularios que rellenes, el contenido que estás consumiendo) puede almacenarse y combinarse con otra información que se tenga sobre tu persona o sobre usuarios similares(por ejemplo, información sobre tu actividad previa en este servicio y en otras páginas web o aplicaciones). Posteriormente, esto se utilizará para crear o mejorar un perfil sobre tu persona (que podría incluir posibles intereses y aspectos personales). Tu perfil puede utilizarse (también en un momento posterior) para mostrarte publicidad que pueda parecerte más relevante en función de tus posibles intereses, ya sea por parte nuestra o de terceros. El contenido que se te presenta en este servicio puede basarse en un perfilde personalización de contenido que se haya realizado previamente sobre tu persona, lo que puede reflejar tu actividad en este u otros servicios (por ejemplo, los formularios con los que interactúas o el contenido que visualizas), tus posibles intereses y aspectos personales. Un ejemplo de lo anterior sería la adaptación del orden en el que se te presenta el contenido, para que así te resulte más sencillo encontrar el contenido (no publicitario) que coincida con tus intereses. La información sobre qué publicidad se te presenta y sobre la forma en que interactúas con ella puede utilizarse para determinar lo bien que ha funcionado un anuncio en tu caso o en el de otros usuarios y si se han alcanzado los objetivos publicitarios. Por ejemplo, si has visualizado un anuncio, si has hecho clic sobre el mismo, si eso te ha llevado posteriormente a comprar un producto o a visitar una página web, etc. Esto resulta muy útil para comprender la relevancia de las campañas publicitarias. La información sobre qué contenido se te presenta y sobre la forma en que interactúas con él puede utilizarse para determinar, por ejemplo, si el contenido (no publicitario) ha llegado a su público previsto y ha coincidido con sus intereses. Por ejemplo, si hasleído un artículo, si has visualizado un vídeo, si has escuchado un “pódcast” o si has consultado la descripción de un producto, cuánto tiempo has pasado en esos servicios y en las páginas web que has visitado, etc. Esto resulta muy útil para comprender la relevancia del contenido (no publicitario) que se te muestra. Se pueden generar informes basados en la combinación de conjuntos de datos (como perfiles de usuario, estadísticas, estudios de mercado, datos analíticos) respecto a tus interacciones y las de otros usuarios con el contenido publicitario (o no publicitario) para identificar las características comunes (por ejemplo, para determinar qué público objetivo es más receptivo a una campaña publicitaria o a ciertos contenidos). La información sobre tu actividad en este servicio, como tu interacción con los anuncios o con el contenido, puede resultar muy útil para mejorar productos y servicios, así como para crear otros nuevos en base a las interacciones de los usuarios, el tipo de audiencia, etc. Esta finalidad específica no incluye el desarrollo ni la mejora de los perfiles de usuario y de identificadores. El contenido que se presenta en este servicio puede basarse en datos limitados, como por ejemplo la página web o la aplicación que esté utilizando, tu ubicación no precisa, el tipo de dispositivo o el contenido con el que estás interactuando (o con el que has interactuado) (por ejemplo, para limitar el número de veces que se te presenta un vídeo o un artículo en concreto). Se puede utilizar la localización geográfica precisa y la información sobre las características del dispositivo Al contar con tu aprobación, tu ubicación exacta (dentro de un radio inferior a 500 metros) podrá utilizarse para apoyar las finalidades que se explican en este documento. Con tu aceptación, se pueden solicitar y utilizar ciertas características específicas de tu dispositivo para distinguirlo de otros (por ejemplo, las fuentes o complementos instalados y la resolución de su pantalla) en apoyo de las finalidades que se explican en este documento. Por solo 1.67 al mes, disfruta de una navegación sin interrupciones por toda la red del Grupo ADSLZone: adslzone.net, movilzona.es, testdevelocidad.es, lamanzanamordida.net, hardzone.es, softzone.es, redeszone.net, topesdegama.com y más. Al unirte a nuestra comunidad, no solo estarás apoyando nuestro trabajo, sino que también te beneficiarás de una experiencia online sin publicidad ni cookies de seguimiento. La nueva versión mensual de Home Assistant ya está con nosotros, y en RedesZone os vamos a contar todas las novedades que incorpora esta nueva versión. A diferencia de versiones anteriores donde teníamos una gran cantidad de cambios, en este caso, lo más destacable es que tenemos muchas nuevas integraciones para ser más versátil. Si tienes robots aspiradores en casa, ahora podrás controlarlos de forma mucho más avanzada a través de este sistema de domótica. Si quieres descubrir todas las novedades de esta nueva versión, y un cambio crítico que han realizado en Python, a continuación, os explicamos todos los detalles. Un mes más, tenemos una nueva versión del popular sistema de domótica de Home Assistant. Como suele ser habitual, han incorporado nuevas integraciones, mejoradas las ya existentes (en cuanto a la calidad del código fuente), e incluso han mejorado el panel de energía, las posibilidades con los robots aspiradores y mucho más. Eso sí, debes estar muy atento a cambios críticos en Python que podrían afectar a tus aplicaciones instaladas de HACS, o a scripts manuales que tengas escritos en este lenguaje. Esta nueva versión no incorpora demasiadas novedades, se han limitado a mejorar lo que ya teníamos, aunque sí debemos destacar la mejora que han introducido en los robots aspiradores. Ahora podremos realizar todas estas acciones cuando vayamos a añadir robots aspiradores a nuestro sistema de Home Assistant: La configuración es bastante sencilla, simplemente debemos irnos a «Dispositivos e integraciones«, irnos a nuestro robot aspirador, y buscar la sección de «Mapeo«. Aquí verás una lista de las habitaciones detectadas por el robot, así que tendremos asignarlas a las diferentes áreas de la casa. Ahora mismo esta funcionalidad de las áreas está disponible para robots aspiradores que usan Matter, también es compatible con la marca Ecovacs y con Roborock. De momento, ninguna marca más es compatible con esta característica, aunque es posible que marcas como Dreame o Xiaomi empiecen a desarrollar sus dispositivos para ser compatible con esta nueva función. Respecto a las mejoras en el panel de energía, en la pestaña «Ahora» tenemos tarjetas de tipo mosaico que mostrarán el consumo de enegría, el caudal de gas y el caudal de agua en tiempo real, y todo de un vistazo. Por supuesto, es completamente necesario que tengamos algún tipo de dispositivo o sensor que mida todo esto, y podamos integrarlo en el sistema de Home Assistant. Además, ahora el agua también incluye un gráfico que nos indicará dónde se «gasta» dicho agua, como teníamos en el panel de electricidad. Otro cambio interesante que han añadido, es que, para reducir la ambigüedad, la segunda pestaña del panel de energía ya no es «Energía» sino «Electricidad«, ya que el panel abarca también el gas y el agua. Otra mejora importante en las automatizaciones de esta nueva versión, es que en la sección de «Acciones» o «Entonces hacer», se ha añadido una opción de «Continuar en caso de error«. Esto ya estaba presente en Home Assistant, pero solamente a través de lenguaje YAML, no estaba en la interfaz gráfica de usuario. Esta funcionalidad está presente en los tres puntos verticales, en la parte de «Continuar en caso de error», justo debajo de «deshabilitar». Esta característica permite que, en caso de que una acción falle, el resto de acciones se puedan ejecutar sin que la automatización se vea interrumpida. Otra novedad interesante es que tenemos detección de palabras de activación en smartphones Android, aunque ahora mismo se trata de una función experimental. Gracias a esta característica, podremos hacer uso de Home Assistant Voice directamente desde nuestro smartphone, como si tuviéramos un satélite siempre con nosotros. La activación se realiza mediante las tres palabras clave de siempre (Okay Nabu, Hey Jarvis y Hey Mycroft), todo se hace de forma local en el dispositivo, no se envía audio a la nube en ningún momento, ni tampoco se requiere procesamiento en el servidor. Esta funcionalidad tiene un impacto importante en la batería de nuestro smartphone: la detección de palabras de activación requiere acceso continuo al micrófono y aumentará el uso de procesador, así que la autonomía de la batería se reducirá radicalmente. Una opción para reducir este consumo tan elevado, es hacer ciertas automatizaciones para que solamente en ciertos casos se habilite, como, por ejemplo, si está cargando nuestro smartphone, o si entramos en casa donde el cargador lo tendremos cerca. Este consumo de batería se podría reducir si Google abriera la API para la detección de palabras clave a través de hardware, pero de momento no es posible. Otros cambios que debemos mencionar, es que las páginas de configuración de Matter, Z-Wave, ZigBee y Bluetooth se han reorganizado para tener mayor claridad. Ahora también tenemos la posibilidad de eliminar elementos de la lista de tareas, así como elegir «Año» en el editor de tarjetas, el apnel de seguridad también mostrará las cubiertas de ventanas, y tendremos tarjetas de pie de página en la vista de «Secciones», igual que tenemos en el encabezado. Como podéis ver, tenemos novedades muy importantes que hacen avanzar a Home Assistant para convertirse en una referencia en domótica en el hogar. En esta nueva versión tenemos integraciones nuevas muy interesantes para seguir ampliando la compatibilidad del sistema de domótica. No debemos olvidar que las integraciones son el «cerebro» del sistema, ya que permiten integrar diferentes dispositivos en Home Assistant para, posteriormente, interactuar con ellas de forma fácil y rápida. Algunas integraciones que han incorporado son las de Ghost, el sistema de música Hegel Amplifier, la batería de Homevolt, el sistema de monitorización en la nube de inversores solares de Hypontech Cloud, así como también de Indevolt. Otras integraciones son las de las marcas IntelliClima, Liebherr, MTA New York City Transit, MyNeomitis, Powerfox Local, Redgtech, System Nexa 2, Teltonika, Trane Local, así como Zinvolt. Si estás buscando un sistema de copia de seguridad en la nube, ahora tenemos compatibilidad con IDrive e2 que es compatible con Amazon S3, para guardar nuestros backups a salvo. También tenemos compatibilidad con OneDrive of Business, la versión empresarial de OneDrive, donde podremos guardar nuestras copias de seguridad. Como podéis ver, tenemos una gran cantidad de integraciones nuevas en esta versión, además, se han mejorado algunas integraciones existentes: Otros cambios están relacionados con los dispositivos de Alexa que ahora soporta dispositivos de calidad de aire, los humificadores de VeSync ahora tienen más funciones, si tienes KNX ahora podrás configurar el número de entidades y enviar la hora actual directamente desde la interfaz gráfica. También tenemos mejoras en la integración de Uptime Kuma, de Radarr, de Proxmox VE, Mealie así como en Portainer, por si quieres ver el estado de todos estos servicios directamente desde Home Assistant. Os recomendamos leer todos los cambios en las integraciones en las notas oficiales de Home Assistant 2026.3. El cambio más importante de esta versión que debes revisar con cuidado, es que tenemos la nueva versión Python 3.14, lo que supone un cambio bastante importante. Ahora tenemos mejoras en el rendimiento del sistema de domótica gracias a la actualización de Python, la nueva versión incluye un intérprete más rápido, tiempo de inicio inferior, y un mejor uso de la memoria RAM. Aunque no es algo que vayas a notar de la noche a la mañana, lo cierto es que todo esto contribuye a mejorar la experiencia con Home Assistant. En principio, no deberías tener problemas, pero es posible que tengas integraciones instaladas mediante HACS o scripts propios en Python que sí den problemas, así que antes de actualizar a esta nueva versión, prueba en una máquina virtual o en tu entorno de pruebas, que todo funciona correctamente. Algunos cambios incompatibles con esta nueva versión está relacionado con las luces, y es que en «color_temp» ya no se admite el uso de «mireds» para configurar el color de las luces, ahora tenemos que usar color_temp_kelvin en su lugar. También se han eliminado atributos de estado de entidad como color_temp, kelvin, min_mireds y max_mireds. Ahora debemos usar color_temp_kelvin, min_color_temp_kelvin y max_color_temp_kelvin. Si usas la integración de tadoº, ahora el seguimiento de dispositivos móviles se ha eliminado de la integración, así que los dispositivos móviles y sus entidades asociadas ya no están disponibles, esto soluciona problemas de reautenticación y reduce la carga de la API de tadoº en la nube. Si usas una «template» de tipo «fans» también tenemos cambios, pero solamente si hay errores de sintaxis. En las notas oficiales de esta nueva versión, están detallados todos los cambios incompatibles que debes valorar.
Images (1): 
|
|||||
| Home Assistant 2026.3 envoie les robots aspirateurs nettoyer pièce par … | https://www.igen.fr/domotique/2026/03/h… | 1 | Mar 07, 2026 00:03 | active | |
Home Assistant 2026.3 envoie les robots aspirateurs nettoyer pièce par pièce - iGenerationDescription: Pour une fois que Maison avait de l’avance sur Home Assistant, cela valait bien une mention : la mise à jour mensuelle de la domotique open source sortie hier ajoute une fonctionnalité que l’app d’Apple proposait déjà. Avec la version 2026.3, le co... Content:
Ouvrir le menu principal iGeneration Recherche Compte iGeneration Soutenez le travail d'une rédaction indépendante. Rejoignez la plus grande communauté Apple francophone ! Nicolas Furno jeudi 05 mars 2026 à 08:40 • 14 Pour une fois que Maison avait de l’avance sur Home Assistant, cela valait bien une mention : la mise à jour mensuelle de la domotique open source sortie hier ajoute une fonctionnalité que l’app d’Apple proposait déjà. Avec la version 2026.3, le contrôle des robots aspirateurs peut désormais se faire pièce par pièce. Si vous disposez d’un tel appareil, vous pourrez associer chaque pièce repérée par le robot à l’une des zones configurées dans Home Assistant et ensuite utiliser des automatisations, l’interface ou, à l’avenir, un assistant vocal pour demander de nettoyer tel ou tel endroit. Cette nouveauté est proposée pour tous les robots Matter qui savent gérer les pièces, ce qui n’est pas le cas de tous les modèles. Home Assistant oblige, les robots aspirateurs peuvent gérer directement la fonctionnalité même sans le standard, et c’est le cas au lancement pour les produits de Roborock ainsi que ceux d’Ecovacs. Les autres marques pourront rejoindre la liste à l’avenir, qu’elles utilisent Matter ou non. Aspirateurs-robots dans Apple Maison : attention à la gestion des pièces Parmi les autres changements de la mise à jour, plutôt riche ce mois-ci, signalons des améliorations appréciables sur le tableau de bord énergie. Pour simplifier sa configuration, les paramètres sont désormais séparés en trois sections pour gérer l’électricité, l’eau et le gaz. Par ailleurs, la vue « Maintenant » introduite avec Home Assistant 2025.12 gagne des pastilles en haut de l’écran pour afficher les consommations instantanées d’électricité, d’eau et de gaz si vous avez l’équipement adéquat. Pour finir, la vue dédiée à l’électricité a été réorganisée pour mieux mettre en avant les statistiques globales, notamment sur mobile. La mise à jour met aussi en avant une option particulièrement utile pour les automatisations et jusque-là bien cachée, à tel point que j’ai découvert son existence en lisant les notes de version. Chaque action pouvait déjà être configurée pour continuer en cas d’erreur, au lieu d’arrêter toute l’exécution de l’automatisation ou du script en cours. Il fallait toutefois modifier ce paramètre en YAML, mais la nouvelle version l’affiche dans le menu contextuel de chaque action. Dans bien des situations, notamment si vous voulez allumer/éteindre de nombreuses lumières ou ouvrir/fermer de multiples volets, c’est le choix qui conviendra le mieux. L’assistant de Home Assistant peut maintenant être activé à la voix sur les appareils Android. C’est l’app associée qui se charge de repérer en local le déclencheur vocal, ce qui a pour effet négatif de consommer bien plus d’énergie. Néanmoins, cela peut être utile pour les tablettes Android utilisées pour afficher un tableau de bord. Pour les smartphones, il sera possible d’activer ou désactiver la fonctionnalité depuis des automatisations, de quoi l’associer à la charge de l’appareil ou à la géolocalisation, puisqu’elle n’a pas de sens hors de chez soi. Comme toujours, la mise à jour enrichit le catalogue d’intégrations et on peut notamment relever l’ajout de l’électroménager connecté de Liebherr. La prise en charge du standard Matter progresse avec l’ajout des détecteurs de monoxyde de carbone et des capteurs TVOC pour la qualité de l’air, même s’il n’y a toujours pas Matter 1.5 et ses caméras. Enfin, dans les aspects moins visibles, Home Assistant a mis à jour Python sous le capot et ce changement promet des gains de performances, notamment un démarrage plus rapide. Vous trouverez le détail des changements apportés par cette version dans l’article de blog qui l’accompagne. Soutenez MacGeneration sur Tipeee Précommandez-le dès maintenant et profitez-en pour découvrir nos nouveaux goodies, ou prolonger votre abonnement au Club iGen à tarif réduit. Un livre pour raconter 50 ans d'Apple, une journée à Lyon pour les célébrer ensemble. 06/03/2026 à 22:45 • 9 06/03/2026 à 20:30 • 13 06/03/2026 à 19:05 • 12 06/03/2026 à 18:36 • 12 06/03/2026 à 17:28 • 19 06/03/2026 à 15:30 • 3 06/03/2026 à 12:35 • 9 06/03/2026 à 10:54 • 22 06/03/2026 à 10:28 • 7 06/03/2026 à 09:09 • 35 06/03/2026 à 08:01 • 21 06/03/2026 à 06:21 • 17 05/03/2026 à 23:55 • 6 05/03/2026 à 22:20 • 5 05/03/2026 à 20:15 • 5 05/03/2026 à 19:35 • 17 Le Club iGen c'est : Soutenez le travail d'une rédaction indépendante. Rejoignez la plus grande communauté Apple francophone ! iOS 26 : notre petit guide des nouveautés Découvrez Home Assistant Le guide de macOS Sonoma Sauvegardez vos données Tout savoir sur les raccourcis clavier sur Mac Tout savoir sur les raccourcis clavier sur iPad Fièrement publié depuis 1999 par MacGeneration SARL. Service de presse en ligne reconnu par la CPPAP sous le numéro 0929 W 93490. ISSN 1773-200X. Tous droits réservés.
Images (1): 
|
|||||
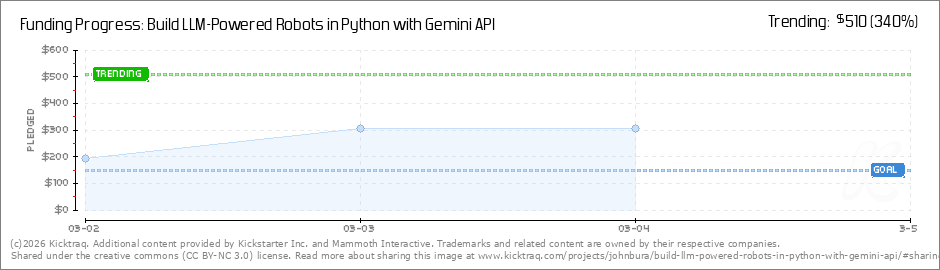
| Build LLM-Powered Robots in Python with Gemini API by Mammoth … | http://www.kicktraq.com/projects/johnbu… | 8 | Mar 07, 2026 00:03 | active | |
Build LLM-Powered Robots in Python with Gemini API by Mammoth Interactive :: KicktraqURL: http://www.kicktraq.com/projects/johnbura/build-llm-powered-robots-in-python-with-gemini-api/ Description: This book gives you the language to unlock your next mechanical move. Content: Images (8): 

|
|||||
| Honor's Humanoid Robot Ambitions Signal a New Front in China's … | https://www.webpronews.com/honors-human… | 0 | Mar 04, 2026 16:00 | active | |
Honor's Humanoid Robot Ambitions Signal a New Front in China's Tech Hardware WarsDescription: Keywords Content: |
|||||
| Honor to Show Off its First Humanoid Robot at MWC … | https://www.androidheadlines.com/2026/0… | 1 | Mar 04, 2026 16:00 | active | |
Honor to Show Off its First Humanoid Robot at MWC 2026URL: https://www.androidheadlines.com/2026/02/honor-humanoid-robot-phone-mwc-2026-launch.html Description: Honor is launching its first humanoid robot at MWC 2026 along with a working prototype of its intriguing "Robot Phone." Content:
Sign Up! envelope_alt Get the latest Android News in your inbox every day arrow_right Sign up to receive the latest Android News every weekday: Only send updates once a week Android Headlines / Mobile Events News / Honor's First Humanoid Service Robot to Debut at MWC 2026 At MWC 2026 in Barcelona, Honor will show off its first humanoid service robot and a prototype of its Robot Phone. The company is investing billions to become the leader in consumer robotics, with a focus on shopping assistance and AI-driven tasks. China currently dominates shipments in 2025 (over 13,000 units shipped worldwide) and has prices that are much lower than those of Western companies like Tesla. It seems like the robotics industry is ready to make another big step forward this year. China wants to be a big player in this technology and is investing heavily for it. Honor, best known for its smartphones, will officially unveil its first humanoid service robot this weekend at MWC 2026. This will be the company’s first step into a sector currently experiencing explosive growth. Honor’s move is the result of a massive multibillion-dollar initiative focused on “embodied AI.” That is, intelligence that lives in a physical, moving body. While competitors like Xiaomi and Oppo are also exploring AI agents, Honor is positioning itself as the first major smartphone manufacturer to dive headfirst into the humanoid consumer-service segment. Many humanoid robots today are designed for heavy lifting in factories or logistics. However, Honor is aiming for something more personal. According to reports, this new machine is optimized for consumer services, specifically tasks like shopping assistance. Interestingly, Honor’s humanoid robot won’t be traveling alone. The firm plans to showcase it alongside the first working prototype of its “Robot Phone.” This tech concept device features a unique gimbal-mounted pop-up camera that can autonomously track subjects, effectively acting as a tiny, desk-bound robot that follows your movement. Honor is entering the market at a time when China has firmly taken the lead in the robotics industry. According to data from the research firm Omdia, the global market saw a staggering 500% revenue growth in 2025 alone. Last year, out of the 13,000 humanoid robots shipped worldwide, the vast majority originated in China. Local companies like AgiBot and Unitree are currently outperforming Western rivals in terms of shipment volumes and pricing. For instance, while a Tesla Optimus might cost between $20,000 and $30,000, Chinese models are entering the market at much lower price points—some as low as $6,000. Honor’s upcoming entry will add even more pressure to the global competition. As we wait for the official keynote on March 1st, the big question remains: how ready is this robot for current homes? Whether we see a fully functional prototype or a conceptual vision, we won’t have to wait long to find out. Jean has been a mobile-tech enthusiast since ever. He likes to always be up-to-date on the latest news in the industry and write about it. He specializes in Android, smartphones, tablets, wearables, apps, and some gaming. Copyright ©2026 Android Headlines. All Rights Reserved. Main Deals & More Android News Sign Up! envelope_alt Get the latest Android News in your inbox every day arrow_right Sign up to receive the latest Android News every weekday: Only send updates once a week
Images (1): 
|
|||||
| Honor Will Unveil, its First AI Humanoid Robot and Robot … | https://www.gizmochina.com/2026/02/24/h… | 1 | Mar 04, 2026 16:00 | active | |
Honor Will Unveil, its First AI Humanoid Robot and Robot Phone Concept at MWC 2026 - GizmochinaDescription: Honor unveils its first AI humanoid robot and Robot Phone concept at MWC 2026, expanding beyond smartphones into AI-driven devices Content:
Honor Device Co. is set to make a major announcement at MWC Barcelona this weekend with the unveiling of its first humanoid robot. The company says the robot is designed mainly for consumer service tasks such as shopping assistance and everyday support. This move signals Honorâs entry into the fast-growing humanoid robotics segment, an area that has recently gained strong global attention due to rapid AI advancements. Honor claims it will be the first smartphone brand among its direct competitors to launch a humanoid robot. The company aims to position itself as a leader in next-generation AI experiences, moving beyond traditional mobile devices and exploring embodied AI technology. The humanoid robot will be showcased under the âHonor Robot Phoneâ concept, which highlights how artificial intelligence could integrate more deeply into daily life. Honor is also expected to present new agentic AI services designed to work across smartphones and connected devices. This strategy is part of a larger multibillion-dollar expansion plan focused on artificial intelligence, new AI applications, and building a smarter ecosystem. Similar moves are being seen across the industry, with rivals like Xiaomi, Oppo, and Vivo also investing heavily in AI innovation. Chinese startups such as Unitree are currently leading the momentum in AI robotics with advanced demonstrations, showing how competitive the space has become. The event, themed âBelievers in AI Future,â will also include the launch of several new devices. These include the Honor Magic V6 foldable smartphone, which features improved durability, a larger battery, and a slimmer design. Honor will also introduce the AI-powered MagicPad4 tablet and MagicBook Pro 14 laptop, both designed for productivity and lightweight performance. Since becoming independent from Huawei in 2020, Honor has expanded rapidly with backing from Shenzhen government investment entities and state-owned enterprises. The company has also expressed plans for a future IPO, reflecting its long-term ambition to grow beyond smartphones and establish itself as a broader AI technology leader. Read More:
Images (1): 
|
|||||
| Xiaomi trials humanoid robots in its EV factory | https://www.cnbc.com/2026/03/04/xiaomi-… | 1 | Mar 04, 2026 16:00 | active | |
Xiaomi trials humanoid robots in its EV factoryURL: https://www.cnbc.com/2026/03/04/xiaomi-humanoid-robots-ev-factory-.html Description: Two humanoid robots can complete 90% of the work in three hours, Xiaomi President Lu Weibing told CNBC. Content:
In this article Xiaomi trialed its humanoid robots in its electric vehicle production plants, the company's president told CNBC, as it looks to boost productivity in its factories. Two humanoid robots can complete 90% of the work in three hours, Lu Weibing told CNBC in an interview at the Mobile World Congress trade show in Barcelona, Spain. They can complete tasks like installing nuts and moving materials, he said. "To integrate robots into our production lines, the biggest challenge is for them to keep up with the pace," Weibing added. "In Xiaomi's car factory, every 76 seconds, a new car gets off the assembly line. The two humanoid robots are able to keep up our pace." Lu said that having humanoid robots working in factories and improving productivity was a key focus for Xiaomi. In the future, humanoid robots will be able to "replace humans for certain work" and "accomplish work that humans couldn't do," he added. Xiaomi first debuted its CyberOne humanoid robot in 2022, but it is currently not selling the product. However, Lu said the use of its robots in production plants was still in its early stages. "The robots in our production lines weren't doing an official job, more like the interns," Lu told CNBC. Still, the trial highlights the pace at which Chinese companies are investing in and improving robotic capabilities. There are a plethora of Chinese firms, some of which have recently gone public, developing the technology. Experts expect Chinese firms to ramp up production of robots this year, with the country itself an early adopter of the technology. Analysts at RBC Capital Markets forecast a global total addressable market for humanoids of $9 trillion by 2050, with China accounting for more than 60% of that. Xiaomi built its business around selling a whole host of consumer electronics products, but in recent years launched an electric vehicle business, which is growing fast. While Lu said he was "bullish" on robotics, he also said it was "too early to say" how big the market will be. Other companies in China have also expanded into robotics. Chinese EV startup XPeng has developed its own humanoid, while on Sunday, smartphone player Honor debuted its first model. In the U.S., Elon Musk has sought to position Tesla as a robotics and AI firm. In January, Musk said Tesla was ending production of its Model S and X vehicles and would use the factory in Fremont, California, to build Optimus humanoid robots. Got a confidential news tip? We want to hear from you. Sign up for free newsletters and get more CNBC delivered to your inbox Get this delivered to your inbox, and more info about our products and services. © 2026 Versant Media, LLC. All Rights Reserved. A Versant Media Company. Data is a real-time snapshot *Data is delayed at least 15 minutes. Global Business and Financial News, Stock Quotes, and Market Data and Analysis. Data also provided by
Images (1): 
|
|||||
| Tesla Rival Xiaomi Deploys Humanoid Robot With 3 Hours Of … | https://www.benzinga.com/markets/tech/2… | 1 | Mar 04, 2026 16:00 | active | |
Tesla Rival Xiaomi Deploys Humanoid Robot With 3 Hours Of Autonomous Operating Time At EV Assembly Plant - Xiaomi (OTC:XIACF) - BenzingaDescription: Xiaomi successfully deployed humanoid robots in EV assembly plant, achieving 3 hours of autonomous operations with 90.2% success rate. Content:
A newsletter built for market enthusiasts by market enthusiasts. Top stories, top movers, and trade ideas delivered to your inbox every weekday before and after the market closes. Xiaomi Corp (OTC:XIACY) (OTC:XIACF) has shared that it deployed humanoid robots in its EV assembly plant as the auto industry looks towards incorporating robotics into production activities. The Chinese tech giant shared that the humanoid robots it deployed successfully achieved 3 hours of autonomous operations, placing self-tapping nuts in the die-casting workshop, CnEVPost reported on Monday, citing a post on Chinese social media platform Weibo by Xiaomi. The robots achieved a 90.2% success rate at the task, the report said. Xiaomi is reportedly considering other applications for its robots, which incorporate a Vision-Language-Action (VLA) approach combined with reinforcement learning. The report also cited Xiaomi CEO Lei Jun, who, in a post on the Chinese social media platform WeChat, predicted that the tech company would see more humanoid robots being deployed at its production facilities in the next five years. Musk had also shared plans to establish an Optimus Academy to train the robot by using Tesla’s reality generator. The Optimus academy would help Tesla train the robots using the same technology it uses for Full Self-Driving (FSD) training. Boston Dynamics says Atlas is capable of lifting objects weighing up to 110 lbs and can function smoothly in temperature ranges from -4° to 104° F. It also boasts the capability of replicating a task learned by a single unit to the entire fleet. Check out more of Benzinga’s Future Of Mobility coverage by following this link. Photo courtesy: Shutterstock © 2026 Benzinga.com. Benzinga does not provide investment advice. All rights reserved. To add Benzinga News as your preferred source on Google, click here. The news comes as more auto manufacturers are entering the robotics sector, with Xpeng Inc. (NYSE:XPEV) announcing that it was establishing a facility in Guangzhou, China, to target large-scale production of its IRON humanoid robot by the end of 2026. Meanwhile, Xpeng also aims to produce over 1 million units of the IRON robot by the end of the decade and has touted deploying the robot in sectors like tour guiding, retail services and more. Tesla Inc. (NASDAQ:TSLA) CEO Elon Musk also shared that the company faces its biggest competitive threat in the robotics sector from Chinese companies. Musk has been bullish on Tesla's Optimus, sharing that the robot could become the first-ever von Neumann probe and aid colonization efforts on other planets in Space. Tesla also faces competition from Hyundai Motor-backed Boston Dynamics, which recently shared details regarding its Atlas humanoid robot. The robot, according to the company, is scheduled to be deployed in the South Korean automaker’s production facility in Georgia.
Images (1): 
|
|||||
| Xiaomi humanoid robot achieves 90% success in EV nut installation | https://interestingengineering.com/ai-r… | 1 | Mar 04, 2026 16:00 | active | |
Xiaomi humanoid robot achieves 90% success in EV nut installationURL: https://interestingengineering.com/ai-robotics/china-xiaomi-humanoid-robot-ev-factory Description: Chinese tech giant Xiaomi has joined a growing list of companies who are deploying humanoids on factory floors in manufacturing processes. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation. Engineering-inspired textiles, mugs, hats, and thoughtful gifts We connect top engineering talent with the world's most innovative companies. We empower professionals with advanced engineering and tech education to grow careers. We recognize outstanding achievements in engineering, innovation, and technology. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation. Engineering-inspired textiles, mugs, hats, and thoughtful gifts We connect top engineering talent with the world's most innovative companies We empower professionals with advanced engineering and tech education to grow careers. We recognize outstanding achievements in engineering, innovation, and technology. All Rights Reserved, IE Media, Inc. The robot performed the installation task within 76 seconds, fulfilling the fastest cycle time requirement. Chinese technology company Xiaomi announced on March 2 that it has deployed humanoid robots in EV assembly operations. Xiaomi CEO Li Jun revealed this development on his official WeChat account. According to company sources, the humanoid worked at a self-tapping nut installation workstation in Xiaomi EV’s die-casting workshop. It achieved a success rate of 90.2% by working for three consecutive hours during the task. The humanoid completed the process in 76 seconds, meeting the production line’s fastest cycle time requirement. Xiaomi said that the deployment of its humanoids marks a key step towards its vision of “large-scale application in automotive manufacturing scenarios.” Speaking to Chinese tech outlet ITHome, the Beijing-based firm revealed the deployments and validation tests are ongoing at other production stations, with further updates to be announced later. In the task, the humanoid robot picked up self-tapping nuts precisely from an automatic feeding device and placed them onto positioning fixtures. In the next step, it coordinated with slide belt conveyors and automatic positioning to complete the automated tightening of floor components after integrated die-casting. According to Xiaomi, the greatest challenge is achieving precise alignment and relatable engagement of the self-tapping nuts. The spline structure inside the nuts, the non-fixed gripping posture, and interference from magnetic forces significantly increased assembly complexity. The Beijing-based tech giant adopted an end-to-end data-driven approach to solve this problem using a joint training framework. It leveraged a 4.7-billion-parameter Vision-Language-Action (VLA) model developed in-house, combined with reinforcement learning. This approach reduces dependence on manual training data and enables the robot to adapt and learn quickly, and learn from its environment. With multimodal input from different sensing techniques, such as vision, touch, and joint position awareness, the robot is less likely to misinterpret complex situations. This process improves the stability and overall performance of the robot. To control full-body movement, Xiaomi uses a hybrid system that blends traditional optimization-based control with reinforcement learning. The optimization controller updates in under one millisecond, allowing the robot to respond in real time. Meanwhile, the reinforcement learning system was trained using hundreds of millions of simulated disturbances in a virtual environment. The training helps the robot stay balanced even in extreme conditions and allows what it learned in simulation to transfer directly to the real-world robot without additional retraining. In an interview last year, Xiaomi CEO Lei Jun shed light on the company’s goal to deploy humanoid robots at a large scale in its factories within the next five years. The company also plans to expand the use of humanoid robots in household settings, which he said “could open a new trillion-yuan market”. Last week, the BMW Group announced its intentions to pilot humanoid robots at its Leipzig plant in Germany this summer. Meanwhile, Tesla CEO Elon Musk has already revealed that Optimus Version 3 will be launching later this year, with the current model already performing basic factory tasks. As global automakers and tech firms accelerate real-world trials, Xiaomi’s latest deployment underscores how humanoid robots are steadily moving from experimental prototypes toward practical roles on factory floors. Atharva is a full-time content writer with a post-graduate degree in media & amp; entertainment and a graduate degree in electronics & telecommunications. He has written in the sports and technology domains respectively. In his leisure time, Atharva loves learning about digital marketing and watching soccer matches. His main goal behind joining Interesting Engineering is to learn more about how the recent technological advancements are helping human beings on both societal and individual levels in their daily lives. Exclusive content, expert insights and a deeper dive into engineering and tech. No ads, no limits. Exclusive content, expert insights and a deeper dive into engineering and tech. No ads, no limits. Premium Follow
Images (1): 
|
|||||
| Xiaomi debuts humanoid robot for EV plant | https://www.azernews.az/region/255178.h… | 1 | Mar 04, 2026 16:00 | active | |
Xiaomi debuts humanoid robot for EV plantURL: https://www.azernews.az/region/255178.html Description: Xiaomi has announced the deployment of a humanoid robot at its electric vehicle manufacturing plant, AzerNEWS reports. Content:
By Alimat Aliyeva Xiaomi has announced the deployment of a humanoid robot at its electric vehicle manufacturing plant, AzerNEWS reports. The robot operated autonomously for three hours at the self-tapping nut installation station in the foundry. During testing, it achieved a 90.2% operational success rate with an average production cycle of 76 seconds. The task involved precise gripping of fasteners, accurate positioning, and automatic tightening following the integrated casting of components. The system is powered by Xiaomi’s proprietary VLA model, Robotics-0, which features 4.7 billion parameters and is enhanced with reinforcement learning. Its control architecture integrates visual perception, tactile feedback, and joint position control, allowing the robot to maintain stability and adapt to minor variations on the assembly line. Xiaomi states that this is the first step toward scaling humanoid robots in automotive manufacturing. Future plans include expanding their use to additional assembly tasks, such as quality inspection and component handling. This innovation not only boosts efficiency but could also address labor shortages and improve workplace safety by taking over repetitive or physically demanding tasks. Xiaomi’s move strengthens its position against competitors like Tesla and Xpeng, who are also investing heavily in humanoid robotics for industrial applications. Interestingly, Xiaomi is exploring the possibility of giving the robot limited collaborative capabilities with human workers, opening the door to hybrid assembly lines where humans and humanoids work side by side. Here we are to serve you with news right now. It does not cost much, but worth your attention. Choose to support open, independent, quality journalism and subscribe on a monthly basis. By subscribing to our online newspaper, you can have full digital access to all news, analysis, and much more. You can also follow AzerNEWS on Twitter @AzerNewsAz or Facebook @AzerNewsNewspaper Thank you! © Azernews.az 2026
Images (1): 
|
|||||
| Chi sono (e come sono) i robot umanoidi che costruiscono … | https://it.motor1.com/news/719500/robot… | 1 | Mar 03, 2026 08:00 | active | |
Chi sono (e come sono) i robot umanoidi che costruiscono autoURL: https://it.motor1.com/news/719500/robot-umanoidi-produzione-auto/ Description: Apollo, Optimus o Figure 01. Loro sono solo l'inizio, vale quindi la pena conoscerli meglio. Ecco chi sono e dove lavorano Content:
Per un'esperienza più personalizzata Navigate su questo e su molti altri siti senza banner pubblicitari, tracciamento personalizzato e annunci video. Uomini e macchine. Fin dall'antichità, l'essere umano ha costruito e utilizzato macchine per svolgere alcune attività. Nel 1927 un film muto diretto da Fritz Lang (Metropolis) ha immaginato come sarebbe stato l'anno 2026. Secondo Fritz Lang i ricchi sarebbero stati molto distanti dai poveri e l'"uomo-macchina" avrebbe sostituito in tutto l'essere umano. Il film Metropolis ha ispirato (o è stato citato) in tanti altri film di fantascienza, solo per citarne alcuni: la saga di Star Wars (dal 1977); Blade Runner (1982) o Terminator (dal 1984). In Italia, nel 1980, Alberto Sordi ha raccontato il rapporto uomo-robot nel film "Io e Caterina. Nel 2004 Audi ha presentato la concept car RSQ in "Io, Robot" e di recente il film "I Mitchell contro le macchine" (2021) ha mostrato cosa potrebbe accadere all'essere umano se gli smartphone si ribellassero e ci mettessero contro un esercito di robot. Insomma, il cinema ci ha abituato da anni a una realtà in cui i robot convivono con noi e adesso ci siamo. Il settore auto (un colosso da un trilione di dollari) è stato il primo a fare uso su larga scala della robotica e con l'intelligenza artificiale siamo arrivati a chiamarli per nome: Apollo, Optimus o Figure 01. Loro sono solo l'inizio, vale quindi la pena conoscerli meglio. È il 19 agosto 2021, Tesla organizza la Giornata dell'intelligenza artificiale (AI) e presenta un prototipo di robot umanoide chiamato Optimus, in omaggio al personaggio cinematografico di Transformers "Optimus Prime". A distanza di tre anni, mentre fa notizia il licenziamento di centinaia di persone che hanno lavorato ai Tesla Supercharger, la casa rilascia un nuovo video in cui Optimus lavora in fabbrica. Stando all'azienda Optimus sarà venduto a clienti esterni entro la fine del 2025. Continuerà a essere ottimizzato di anno in anno e i lettori più attenti ricorderanno anche il polverone suscitato a fine 2023 dalla notizia che il robot aveva ferito un operaio. Incidenti di percorso. Gennaio 2024: la startup di robotica Figure firma un accordo con BMW per introdurre i suoi robot umanoidi nello stabilimento di Spartanburg, nella Carolina del Sud (USA). I robot, spiega una nota ufficiale, sono destinati ad automatizzare attività di produzione “difficili, pericolose o noiose”. “La robotica monouso ha saturato il mercato commerciale per decenni, ma il potenziale della robotica generica è completamente inutilizzato”, dice Brett Adcock, CEO di Figure. “I robot di Figure consentiranno alle aziende di aumentare la produttività, ridurre i costi e creare un ambiente più sicuro e coerente”. Quanti siano i robot attualmente in fase di sperimentazione non è noto, ma l'esperimento è destinato a riguardare fabbriche in tutto il mondo. Figure 01 assembla BMW Un altro annuncio è datato 2024: la società di robotica Apptronik collabora con Mercedes per sperimentare Apollo, un robot bipede alto un metro e 70 cm che può sollevare fino a 25 kg. "Si tratta di una nuova frontiera e vogliamo comprendere il potenziale sia della robotica che della produzione automobilistica per colmare le lacune di manodopera in aree quali il lavoro poco qualificato, ripetitivo e fisicamente impegnativo e per liberare i membri del nostro team altamente qualificati sulla linea di produzione per costruire le auto più desiderabili del mondo", dice il capo della produzione Mercedes, Jörg Burzer. Anche in questo caso non sappiamo quanti robot siano in fase di sviluppo, ma ci aspettiamo notizie molto presto. Aprile 2024, Sanctuary AI, società nata nel 2018 con l'obiettivo di creare "la prima intelligenza simile a quella umana in robot a uso generale", annuncia che collaborerà con Magna (il colosso che produce e assembla auto per conto di vari brand, tra cui Mercedes, Jaguar e BMW). "Integrando robot AI a uso generale nelle nostre strutture di produzione per compiti specifici, possiamo potenziare le nostre capacità per consegnare prodotti di alta qualità ai nostri clienti", dice Todd Deaville, vicepresidente della divisione Advanced Manufacturing Innovation presso Magna. Quindi benvenuto Phoenix, potete vederlo in azione nel video qui sotto: Nelle fabbriche di auto ci sono robot di tutti i tipi. Quelli "umanoidi" sono solo gli ultimi arrivati e vanno ad affiancare robot chiamati articolati, a braccio articolato, collaborativi a sei assi, cartesiani (costituiti essenzialmente da attuatori lineari), cilindrici... Per questo gli umanoidi vengono anche identificati con l'appellativo di "robot bipedi" e li troviamo in fabbriche di vario genere. Digit, per esempio, ha due braccia e due gambe di metallo e dà una mano nei magazzini di Amazon per impacchettare le consegne. Digit lavora nei magazzini di Amazon Oltre a lavorare in fabbrica questi robot con sembianze umane stanno iniziando a essere impiegati anche nell'area dei servizi. Al Salone di Pechino, Omoda e Jaecoo hanno presentato Mornine, un androide intelligente realizzato in collaborazione con AiMoga (partner strategico di Chery) che nel video qui sotto vediamo impegnato nella descrizione di un'auto per la vendita. Riusciranno queste macchine a fare meglio dell'essere umano sotto ogni aspetto? In Giappone, nonostante la costante crescita tecnologica, i maestri Takumi (gli artigiani più esperti che lavorano in Nissan o in Toyota) sono ancora capaci di superare i robot nella finitura dei prodotti di alta qualità. Ma l'artigianato ha ancora un futuro? Leggi anche Vogliamo la tua opinione! Cosa vorresti vedere su Motor1.com? - Il team di Motor1.com DI TENDENZA ULTIMI ARTICOLI Consigliati per te Gli interni del nuovo SUV ibrido di Kia Renault aggiorna per il 2026 le sue Austral, Espace e Rafale In Finlandia le gomme da neve si provano così Le auto più vendute d'Italia a febbraio 2026: la classifica ZTL Roma, stop alle elettriche gratis dal 1° luglio 2026 Offerta Mercedes CLA, vantaggi e svantaggi I prezzi di benzina e gasolio salgono sempre più Foto Video Per un'esperienza più personalizzata Navigate su questo e su molti altri siti senza banner pubblicitari, tracciamento personalizzato e annunci video.
Images (1): 
|
|||||
| Samsung to use humanoid robots and agentic AI to reshape … | https://www.notebookcheck.net/Samsung-t… | 1 | Mar 02, 2026 16:01 | active | |
Samsung to use humanoid robots and agentic AI to reshape its global factories by 2030 - NotebookCheck.net NewsDescription: Samsung has revealed its manufacturing roadmap for the coming years. The company will push humanoid robots and agentic AI to transform its factories by 2030. Content:
Samsung Electronics has given a glimpse of its global production vision. The South Korean giant will lean into two of the most disruptive technologies in the industry to overhaul the way it brings products to the market: humanoid robots and agentic AI. Samsung is active in robot development, but has been limited to commercial products such as vacuums. However, it has been investing in companies developing humanoid robots, including Rainbow Robotics. The electronics maker intended to deploy Rainbow Robotics’ RB-Y1 on its manufacturing lines. The other main pillar of Samsung’s 2030 manufacturing transformation strategy is AI. Samsung states it will enhance quality and productivity at every production step (from material warehousing to shipment) with agentic AI. It will also deploy AI applications to improve workplace safety and environmental health. Samsung will reveal more about its AI strategy at the Mobile World Congress (MWC) in Barcelona in March. The company will host a side-line event, which will also detail its governance strategy for overseeing its AI deployment. Meanwhile, Samsung is not alone in bringing humanoids to the factory. Prominent Apple supplier Foxconn announced in October 2025 that it would begin using Nvidia-powered bipedal robots to assemble AI servers within 6 months. Hyundai has also ordered 30,000 6-feet-2-inches Atlas robots from its subsidiary, Boston Dynamics. The humanoids will work across Hyundai’s car factories in the US. Yonhap News Agency
Images (1): 
|
|||||
| Toyota Puts Humanoid Robots on the Assembly Line: What Seven … | https://www.webpronews.com/toyota-puts-… | 0 | Mar 02, 2026 16:01 | active | |
Toyota Puts Humanoid Robots on the Assembly Line: What Seven Machines in Ontario Signal for the Future of ManufacturingDescription: Keywords Content: |
|||||
| Watch: Humanoid robots work together using the same AI 'brain' … | https://www.euronews.com/next/2026/02/0… | 1 | Mar 02, 2026 16:01 | active | |
Watch: Humanoid robots work together using the same AI 'brain' | EuronewsURL: https://www.euronews.com/next/2026/02/05/watch-humanoid-robots-work-together-using-the-same-ai-brain Description: Until now, humanoid robots have largely worked on their own. A new AI system is designed to run them together. Content:
Europe Today Euronews' flagship morning TV show with the news and insights that drive Europe, live from Brussels every morning at 08.00. Also available as a newsletter and podcast. The Ring The Ring is Euronews’ weekly political showdown, where Europe’s toughest debates meet their boldest voices. In each episode, two political heavyweights from across the EU face off to propose a diversity of opinions and spark conversations around the most important issues of EU affairs and the wider European political life. No Comment No agenda, no argument, no bias, No Comment. Get the story without commentary. My Wildest Prediction Dare to imagine the future with business and tech visionaries The Big Question Deep dive conversations with business leaders Euronews Tech Talks Euronews Tech Talks goes beyond discussions to explore the impact of new technologies on our lives. With explanations, engaging Q&As, and lively conversations, the podcast provides valuable insights into the intersection of technology and society. The Food Detectives Europe's best food experts are joining forces to crack down on fraud. Euronews is following them in this special series: The Food Detectives Water Matters Europe's water is under increasing pressure. Pollution, droughts, floods are taking their toll on our drinking water, lakes, rivers and coastlines. Join us on a journey around Europe to see why protecting ecosystems matters, how our wastewater can be better managed, and to discover some of the best water solutions. Video reports, an animated explainer series and live debate - find out why Water Matters, from Euronews. Climate Now We give you the latest climate facts from the world’s leading source, analyse the trends and explain how our planet is changing. We meet the experts on the front line of climate change who explore new strategies to mitigate and adapt. Europe Today Euronews' flagship morning TV show with the news and insights that drive Europe, live from Brussels every morning at 08.00. Also available as a newsletter and podcast. The Ring The Ring is Euronews’ weekly political showdown, where Europe’s toughest debates meet their boldest voices. In each episode, two political heavyweights from across the EU face off to propose a diversity of opinions and spark conversations around the most important issues of EU affairs and the wider European political life. No Comment No agenda, no argument, no bias, No Comment. Get the story without commentary. My Wildest Prediction Dare to imagine the future with business and tech visionaries The Big Question Deep dive conversations with business leaders Euronews Tech Talks Euronews Tech Talks goes beyond discussions to explore the impact of new technologies on our lives. With explanations, engaging Q&As, and lively conversations, the podcast provides valuable insights into the intersection of technology and society. The Food Detectives Europe's best food experts are joining forces to crack down on fraud. Euronews is following them in this special series: The Food Detectives Water Matters Europe's water is under increasing pressure. Pollution, droughts, floods are taking their toll on our drinking water, lakes, rivers and coastlines. Join us on a journey around Europe to see why protecting ecosystems matters, how our wastewater can be better managed, and to discover some of the best water solutions. Video reports, an animated explainer series and live debate - find out why Water Matters, from Euronews. Climate Now We give you the latest climate facts from the world’s leading source, analyse the trends and explain how our planet is changing. We meet the experts on the front line of climate change who explore new strategies to mitigate and adapt. "Humanoid robots designed for different tasks can now share a single artificial intelligence 'brain' that coordinates their actions across multiple locations simultaneously." A UK-based company has unveiled an AI system that can virtually work as a “shared brain” for fleets of robots built for different purposes across factories, services, and homes simultaneously. Companies like Tesla, Boston Dynamics and XPeng have showcased humanoid robot prototypes in recent years, but these demonstrations typically feature robots operating on their own. The UK firm’s approach is designed to manage multiple humanoid robots together under a single AI. Shared control systems are already common for industrial robots, however, applying the same approach to robots that rely on human-like movement and manipulation has been rare. The AI system, called KinetIQ, can assign tasks to entire robot fleets and control individual movements simultaneously in seconds, according to Humanoid, the robotics company behind the new system. Data from individual robots is shared across the system, helping improve performance fleet-wide. In a video released by Humanoid, a woman asks a bipedal humanoid robot to order cocoa powder and olive oil. In the next scene, wheeled robots in a warehouse-like environment use five-fingered hands to grasp a glass bottle and a soft paper bag, and then put them in a hard container box before packing them into a paper bag. Once the order reaches the home, the bipedal robot unpacks the bag and places the items as instructed by the woman’s voice commands. According to Humanoid, the wheeled robots seen in the video are designed for industrial use, such as back-of-store grocery picking, container handling and packing, while the bipedal robots are intended for service roles and domestic use. The company describes the bipedal robot as an “intelligent assistant” capable of voice interaction, online ordering, and grocery handling. Humanoid has previously managed to have a 179 cm bipedal robot walk in just two days after its assembly, a process that typically takes weeks or months in humanoid robotics. The robot is designed to carry loads of up to 15 kilograms, with the company positioning it as a response to labour shortages, physically demanding work and unpaid domestic care. Humanoid said the capabilities shown in the video have already been tested in real-world pilot projects, and that a beta version of the wheeled robots will be available for sale early next year. For more on this story, watch the video in the media player above. Video editor • Roselyne Min Browse today's tags
Images (1): 
|
|||||
| Segway Robotics teams up with NVIDIA on new AI kit … | https://www.investing.com/news/stock-ma… | 0 | Mar 01, 2026 16:00 | active | |
Segway Robotics teams up with NVIDIA on new AI kit By Investing.comDescription: Segway Robotics teams up with NVIDIA on new AI kit Content: |
|||||
| Toyota porta in fabbrica i robot umanoidi Digit | https://www.tecnoandroid.it/2026/02/26/… | 1 | Mar 01, 2026 00:01 | active | |
Toyota porta in fabbrica i robot umanoidi DigitURL: https://www.tecnoandroid.it/2026/02/26/toyota-porta-in-fabbrica-i-robot-umanoidi-digit-1783640/ Description: Toyota introduce i robot umanoidi Digit nello stabilimento canadese del RAV4. L'azienda punta sull'automatizzazione dei flussi interni. Content:
Negli stabilimenti automobilistici, i robot umanoidi non sono più solo una promessa futuristica. Tali dispositivi stanno iniziando a muoversi tra le linee produttive con la stessa naturalezza di un operaio esperto. A tal proposito, Toyota da tempo osserva l’evoluzione dell’automazione. Ora l’azienda ha deciso di fare un passo avanti e portare in campo i robot Digit, creati da Agility Robotics. Si tratta di sette di tali umanoidi che verranno impiegati nello stabilimento canadese dove nasce il SUV RAV4. Il compito dei robot sarà quello di gestire i flussi interni di componenti, scaricando le cassette di ricambi dai veicoli automatizzati. Un lavoro ripetitivo e faticoso, che finora gravava sulle spalle degli operatori. La vera novità sta nel modo in cui tali umanoidi vengono integrati. Il modello scelto da Toyota è quello del “Robots as a Service“, che permette di avere i robot pronti all’uso e collegati a una piattaforma cloud, Agility Arc. Quest’ultima è capace di coordinare le flotte, ottimizzare percorsi e ridurre tempi morti. Tutto il sistema si regge sull’intelligenza artificiale che permette ai robot di adattarsi rapidamente ai flussi di lavoro già esistenti. Il tutto senza stravolgere l’organizzazione dello stabilimento. Digit non è una novità assoluta. Agility Robotics lo ha già testato in contesti logistici impegnativi, per aziende come Amazon, Schaeffler e GXO. È un modello maturo, capace di operare con autonomia e precisione. Toyota vuole sfruttarne appieno tale potenziale, trasformando Digit in uno strumento che velocizzi la produzione senza aggiungere complessità. Nel frattempo, la lista dei produttori interessati ai robot umanoidi continua a crescere. I robot attuali sono in grado di camminare, sollevare pesi, coordinare il lavoro. Nel contesto attuale, gli umanoidi sono progettati per diventare parte integrante della produzione quotidiana, e che potrebbero cambiare radicalmente il modo in cui si costruiscono le auto (e non solo). Ciao sono Margareth, per gli amici Maggie, la vostra amichevole web writer di quartiere. Questa piccola citazione dice già tanto di me: amo il cinema, le serie tv, leggere e cantare a squarciagola i musical a teatro. Se a questo aggiungiamo la passione per la fotografia e la tecnologia direi che è facile intuire perché ho deciso di studiare e poi lavorare con la comunicazione. 2012 – 2023 Tecnoandroid.it – Gestito dalla STARGATE SRLS – P.Iva: 15525681001 Testata telematica quotidiana registrata al Tribunale di Roma CON DECRETO N° 225/2015, editore STARGATE SRLS. Tutti i marchi riportati appartengono ai legittimi proprietari. Questo articolo potrebbe includere collegamenti affiliati: eventuali acquisti o ordini realizzati attraverso questi link contribuiranno a fornire una commissione al nostro sito. Inserisci qualcosa di speciale: Tienimi connesso fino a quando non esco Password dimenticata? Ti sarà inviata una nuova password via email. Hai ricevuto una nuova password? Accedi qui.
Images (1): 
|
|||||
| Гуманоїдні роботи Agility працюватимуть на заводі | https://expert.com.ua/211252-humanoidni… | 1 | Mar 01, 2026 00:01 | active | |
Гуманоїдні роботи Agility працюватимуть на заводіURL: https://expert.com.ua/211252-humanoidni-roboty-agility-pracyuvatymut-na-zavodi.html Description: Toyota уклала контракт на використання семи гуманоїдних роботів для роботи на заводі з виробництва позашляховиків RAV4 в рамках угоди «роботи як послуга» Content:
Після річного пілотного проекту канадська виробнича дочірня компанія Toyota уклала контракт на використання семи гуманоїдних роботів для роботи на заводі з виробництва позашляховиків RAV4 в рамках угоди «роботи як послуга». «Після оцінки ряду роботів ми раді впровадити Digit для поліпшення досвіду членів команди та подальшого підвищення операційної ефективності на наших виробничих потужностях», — заявив у своїй заяві президент Toyota Motor Manufacturing Canada (TMMC) Тім Холландер. Робот Digit, про який йдеться, побудований компанією Agility Robotics, яка відокремилася від Університету штату Орегон у 2015 році. Digit призначений для роботи в промислових умовах без присутності людей, часто з’єднуючи дві автоматизовані виробничі лінії. У цьому випадку роботи будуть розвантажувати контейнери з автозапчастинами з автоматизованого складського тягача. Хоча сім роботів, які виконують ручну важку роботу, можуть здатися невеликим кроком у порівнянні з ефектними роликами, де металеві люди виконують сальто, насправді впровадження гуманоїдних роботів на реальних робочих місцях є рідкісним і складним. Продемонструвати можливості в лабораторії — це одне, але інтегрувати їх у робочий процес компанії, включаючи технічне обслуговування та заряджання, — не так просто. «Коли технологічні компанії витрачають реальний час на розуміння завдань, які потрібно виконувати, реальних робочих процесів, що відбуваються… саме тоді ми побачимо значне зростання їхнього впровадження», — сказав Рам Девараджулу, віцепрезидент Cambridge Consultants, на саміті Humanoids Summit наприкінці 2025 року. Agility є одним із лідерів у виведенні роботів із лабораторій, а Digits працює в аналогічному режимі для логістичних провайдерів, таких як GXO, Schaeffler та Amazon. Компанія має власний хмарний програмний пакет під назвою Arc, за допомогою якого користувачі можуть керувати парком своїх роботів, і стверджує, що штучний інтелект буде мати вирішальне значення для зниження витрат на впровадження. «Витрати на впровадження… можуть значно перевищувати ціну робота», — заявив Прас Велагапуді, технічний директор Agility, в інтерв’ю минулого року. «Інструменти штучного інтелекту дозволяють нам зменшити витрати на впровадження, скоротити час на налаштування робота і досягнення ним необхідного рівня продуктивності». TMMC і Agility використають цю співпрацю як можливість для впровадження інших сценаріїв використання, які звільнять працівників від повторюваних фізичних завдань і дозволять їм зосередитися на більш цінній роботі. Компанія також готує роботів нового покоління, які будуть безпечними для роботи поряд з людьми. Сучасні гуманоїдні роботи, які мають достатню силу для підйому важких вантажів, все ще вважаються занадто ненадійними для автономної роботи в оточенні людей. Конкурент Figure AI протягом 10 місяців минулого року тестував своїх роботів Figure 02 на заводі BMW, де, за даними компанії, вони розвантажили 90 000 деталей. Інші компанії, які використовують гуманоїдів у пілотних програмах, включають Apptronic, Unitree, Tesla, Boston Dynamics, 1X Technology та Reflex Robotics. При повному або частковому відтворенні матеріалів обов'язково посилайтеся на HiTech.Expert. Про проект та рекламні можливості сайту HITech.Expert Редакція: gbogapov@gmail.com © 1999-2023 HiTech.Expert. Хостинг: Mirohost.net
Images (1): 
|
|||||
| Toyota внедряет роботов-гуманоидов Digit для сборки RAV4 | https://hightech.fm/2026/02/20/toyota-d… | 1 | Mar 01, 2026 00:01 | active | |
Toyota внедряет роботов-гуманоидов Digit для сборки RAV4URL: https://hightech.fm/2026/02/20/toyota-digit Description: На канадском заводе Toyota начали работать семь человекоподобных роботов Agility Robotics модели Digit. Они помогают разгружать комплектующие и ускоряют процесс сборки кроссоверов RAV4, демонстрируя, как роботы постепенно входят в автопроизводство. Content:
На канадском заводе Toyota начали работать семь человекоподобных роботов Agility Robotics модели Digit. Они помогают разгружать комплектующие и ускоряют процесс сборки кроссоверов RAV4, демонстрируя, как роботы постепенно входят в автопроизводство. На канадском заводе Toyota семь роботов Digit присоединились к процессу сборки RAV4 после года тестирования, сообщает TechCrunch. Роботы Digit сосредоточатся на работе с грузами. Их задача — разгружать контейнеры с комплектующими с автоматических тележек, которые курсируют по цеху. Благодаря фирменному облачному сервису Arc компания Agility Robotics позволяет управлять роботами удалённо. Agility Robotics уже поставляет своих роботов в логистические компании, включая гиганта интернет-торговли Amazon. При этом представители компании отмечают, что интеграция роботов в инфраструктуру клиента часто обходится дороже самой покупки, поэтому здесь активно применяют ИИ для управления процессом. Не только Toyota проявляет интерес к человекоподобным роботам. TSMC планирует внедрять роботов Agility на своих фабриках по производству чипов. Agility также разрабатывает следующее поколение гуманоидных роботов, которые будут безопаснее работать рядом с людьми. Существующие модели способны поднимать тяжёлые грузы, но требуют строгого соблюдения техники безопасности. Сейчас многие автопроизводители, особенно китайские компании, тестируют человекоподобных роботов на своих предприятиях. Это шаг к более автоматизированному и гибкому производству, где роботы помогают людям выполнять тяжёлую и рутинную работу. Читать далее: Вселенная внутри черной дыры: наблюдения «Уэбба» подтверждают странную гипотезу Испытания ракеты Starship Илона Маска вновь закончились взрывом в небе Сразу четыре похожих на Землю планеты нашли у ближайшей одиночной звезды Обложка: Agility Robotics Пройдите, пожалуйста, мини-опрос, который поможет нам стать еще интереснее и полезнее для вас!
Images (1): 
|
|||||
| Ð¡ÐµÐ¼Ñ ÑеловекоподобнÑÑ ÑобоÑов Agility помогÑÑ Ñо ÑбоÑкой Toyota RAV4 в … | https://pcnews.ru/news/sem_celovekopodo… | 1 | Mar 01, 2026 00:01 | active | |
Ð¡ÐµÐ¼Ñ ÑеловекоподобнÑÑ ÑобоÑов Agility помогÑÑ Ñо ÑбоÑкой Toyota RAV4 в Ðанаде - PCNEWS.RUDescription: ÐÑе компÑÑÑеÑнÑе новоÑÑи на PCNews.ru. ÐÑÑ Ð½Ð¾Ð²Ð°Ñ Ð¸Ð½ÑоÑмаÑиÑ, о компÑÑÑеÑÐ°Ñ Ð¸ инÑоÑмаÑионнÑÑ ÑÐµÑ Ð½Ð¾Ð»Ð¾Ð³Ð¸ÑÑ . СиндикаÑÐ¸Ñ Ð½Ð¾Ð²Ð¾ÑÑей, ÑÑаÑей, пÑеÑÑ-Ñелизов Ñо вÑÐµÑ ÑайÑов компÑÑÑеÑной (ÐТ или IT) ÑемаÑики. Content:
ÐÑÑоÑиÑеÑки на авÑоÑбоÑоÑнÑÑ Ð¿ÑедпÑиÑÑиÑÑ Ð¸ÑполÑзовалиÑÑ Ð³Ð»Ð°Ð²Ð½Ñм обÑазом манипÑлÑÑоÑÑ Ð¸ ÑобоÑизиÑованнÑе Ñележки, но в наÑи дни Ñам Ð½Ð°Ñ Ð¾Ð´ÑÑ Ð¿Ñименение и ÑеловекоподобнÑе ÑобоÑÑ. Ðа канадÑком пÑедпÑиÑÑии Toyota Motor наÑали ÑкÑплÑаÑиÑоваÑÑÑÑ ÑÐµÐ¼Ñ ÑеловекоподобнÑÑ ÑобоÑов Agility Robotics модели Digit. ÐÑÑоÑник изобÑажениÑ: Agility Robotics Ðак оÑмеÑÐ°ÐµÑ TechCrunch, пеÑед ÑÑим Toyota около года ÑеÑÑиÑовала даннÑÑ ÑобоÑов, но ÑепеÑÑ Ð¾Ð½Ð¸ пÑивлеÑÐµÐ½Ñ Ðº пÑоÑеÑÑÑ Ð²ÑпÑÑка кÑоÑÑовеÑов RAV4 на поÑÑоÑнной оÑнове. Ðак и во Ð¼Ð½Ð¾Ð³Ð¸Ñ ÑлÑÑаÑÑ Ð² наÑи дни, ÑеловекоподобнÑе ÑобоÑÑ Digit ÑоÑÑедоÑоÑаÑÑÑ Ð½Ð° манипÑлÑÑиÑÑ Ñ Ð³ÑÑзами. Ðм бÑÐ´ÐµÑ Ð¿Ð¾ÑÑÑено ÑазгÑÑжаÑÑ ÐºÐ¾Ð½ÑейнеÑÑ Ñ ÐºÐ¾Ð¼Ð¿Ð»ÐµÐºÑÑÑÑими Ñ Ð°Ð²ÑомаÑиÑеÑÐºÐ¸Ñ Ñележек, кÑÑÑиÑÑÑÑÐ¸Ñ Ð¿Ð¾ канадÑÐºÐ¾Ð¼Ñ Ð·Ð°Ð²Ð¾Ð´Ñ Toyota. ÐÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ñ Agility Robotics Ñже ÑÐ½Ð°Ð±Ð¶Ð°ÐµÑ Ñвоими ÑобоÑами неÑколÑко логиÑÑиÑеÑÐºÐ¸Ñ ÐºÐ¾Ð¼Ð¿Ð°Ð½Ð¸Ð¹, вклÑÑÐ°Ñ Ð³Ð¸Ð³Ð°Ð½Ñа инÑеÑнеÑ-ÑоÑговли Amazon. ФиÑменнÑй облаÑнÑй ÑеÑÐ²Ð¸Ñ Arc позволÑÐµÑ Ð¸Ð¼ ÑдалÑнно конÑÑолиÑоваÑÑ ÑабоÑÑ ÑобоÑов. Ðо Ñловам пÑедÑÑавиÑелей Agility, ÑÑоимоÑÑÑ Ð¸Ð½ÑегÑаÑии ÑобоÑов в инÑÑаÑÑÑÑкÑÑÑÑ ÐºÐ»Ð¸ÐµÐ½Ñа неÑедко пÑевÑÑÐ°ÐµÑ Ð·Ð°ÑÑаÑÑ Ð½Ð° его покÑпкÑ, поÑÑÐ¾Ð¼Ñ Ð² ÑÑой ÑÑеÑе Ñоже важно иÑполÑзоваÑÑ ÐÐ. TSMC Ñакже ÑобиÑаеÑÑÑ Ð²Ð½ÐµÐ´ÑиÑÑ ÑеловекоподобнÑÑ ÑобоÑов Agility Ñ ÑÐµÐ±Ñ Ð½Ð° пÑедпÑиÑÑиÑÑ Ð¿Ð¾ пÑоизводÑÑÐ²Ñ Ñипов, Ñ Ð¾ÑÑ ÑеÑÑ Ð½Ð°Ð²ÐµÑнÑка идÑÑ Ð½Ðµ о ÑамÑÑ Ð²ÑÑокоÑоÑнÑÑ Ð¸ оÑвеÑÑÑвеннÑÑ Ð¼Ð°Ð½Ð¸Ð¿ÑлÑÑиÑÑ . Agility Ñакже ÑазÑабаÑÑÐ²Ð°ÐµÑ Ñеловекоподобного ÑобоÑа нового поколениÑ, коÑоÑÑй бÑÐ´ÐµÑ Ð±Ð¾Ð»ÐµÐµ безопаÑнÑм пÑи иÑполÑзовании в окÑÑжении, наполненном лÑдÑми. СÑÑеÑÑвÑÑÑие гÑманоиднÑе ÑобоÑÑ, ÑпоÑобнÑе поднимаÑÑ ÑÑжÑлÑе гÑÑзÑ, Ñ ÑоÑки зÑÐµÐ½Ð¸Ñ ÑÐµÑ Ð½Ð¸ÐºÐ¸ безопаÑноÑÑи пÑи ÑоÑедÑÑве Ñ Ð»ÑдÑми не Ñак безÑпÑеÑнÑ. СÑеди авÑопÑоизводиÑелей много компаний, коÑоÑÑе Ñже ÑеÑÑиÑÑÑÑ ÑеловекоподобнÑÑ ÑобоÑов Ñ ÑÐµÐ±Ñ Ð½Ð° пÑедпÑиÑÑиÑÑ , оÑобенно ÑÑеди киÑайÑÐºÐ¸Ñ . © 3DNews
Images (1): 
|
|||||
| Meet Digit: Toyota’s newest worker doesn’t need coffee breaks | … | https://globalnews.ca/news/11677383/dig… | 1 | Mar 01, 2026 00:01 | active | |
Meet Digit: Toyota’s newest worker doesn’t need coffee breaks | Globalnews.caURL: https://globalnews.ca/news/11677383/digit-toyotas-humanoid-robot/ Description: Toyota Motor Manufacturing Canada will begin deploying three humanoid ‘Digit’ robots at its Woodstock plant under a new deal with Agility Robotics, following a successful pilot. Content:
Instructions: Want to discuss? Please read our Commenting Policy first. Comment Name Δ 1 comment A company that refrains from using robots and advertises it will lead sales. If you get Global News from Instagram or Facebook - that will be changing. Find out how you can still connect with us. It has arms, hands, eyes — of a sort — and can stand for hours doing the same task, over and over, without uttering a word of complaint. But Toyota Canada’s latest employee is unlike any other ever to grace the floor of the company’s Woodstock, Ont., assembly plant. You see, Digit is a humanoid robot. Following a successful pilot, the company has signed a commercial Robots-as-a-Service agreement with Oregon-based Agility Robotics to deploy its general-purpose robot at the facility. The robots will support manufacturing, supply chain and logistics operations. While seven robots are allocated under the agreement, deployment will begin with three units. “After evaluating a number of robots, we are excited to deploy Digit to improve the team member experience and further increase operational efficiency in our manufacturing facilities,” Tim Hollander, president of Toyota Motor Manufacturing Canada, said in a release. Digit is designed to take on repetitive and physically demanding tasks commonly found on automotive production lines. In the release, the companies said that automating “extremely repetitive and physically taxing tasks” could reduce strain and increase safety for employees, freeing them to focus on more value-added work. Agility Robotics CEO Peggy Johnson said partnering with Toyota, one of the world’s largest automakers, marks a significant step for humanoid robots in industrial settings. “Toyota is one of the premier companies in the world; one with a long history of innovation and success, so it’s a privilege to join forces to integrate humanoid robotic solutions like Digit into automotive production,” Johnson said. The companies say they will continue exploring additional use cases where robots and artificial intelligence could further augment automotive production. Toyota joins a growing number of Fortune 500 companies deploying Agility’s humanoid robots globally, including GXO, Schaeffler and Amazon. Toyota Motor Manufacturing Canada operates vehicle assembly plants in Cambridge and Woodstock and is Toyota’s largest manufacturing operation outside Japan. The email you need for the day’s top news stories from Canada and around the world. The email you need for the day’s top news stories from Canada and around the world.
Images (1): 
|
|||||
| Toyota наняла семь человекоподобных роботов Agility Digit для сборки RAV4 | https://3dnews.ru/1137151/sem-cheloveko… | 1 | Mar 01, 2026 00:01 | active | |
Toyota наняла семь человекоподобных роботов Agility Digit для сборки RAV4Description: Исторически на автосборочных предприятиях использовались главным образом манипуляторы и роботизированные тележки, но в наши дни там находят применение и человекоподобные роботы. На канадском предприятии Toyota Motor начали эксплуатироваться семь человекоподобных роботов Agility Robotics модели Digit.. Content:
Исторически на автосборочных предприятиях использовались главным образом манипуляторы и роботизированные тележки, но в наши дни там находят применение и человекоподобные роботы. На канадском предприятии Toyota Motor начали эксплуатироваться семь человекоподобных роботов Agility Robotics модели Digit. Источник изображения: Agility Robotics Как отмечает TechCrunch, перед этим Toyota около года тестировала данных роботов, но теперь они привлечены к процессу выпуска кроссоверов RAV4 на постоянной основе. Как и во многих случаях в наши дни, человекоподобные роботы Digit сосредоточатся на манипуляциях с грузами. Им будет поручено разгружать контейнеры с комплектующими с автоматических тележек, курсирующих по канадскому заводу Toyota. Компания Agility Robotics уже снабжает своими роботами несколько логистических компаний, включая гиганта интернет-торговли Amazon. Фирменный облачный сервис Arc позволяет им удалённо контролировать работу роботов. По словам представителей Agility, стоимость интеграции роботов в инфраструктуру клиента нередко превышает затраты на его покупку, поэтому в этой сфере тоже важно использовать ИИ. TSMC также собирается внедрить человекоподобных роботов Agility у себя на предприятиях по производству чипов, хотя речь наверняка идёт не о самых высокоточных и ответственных манипуляциях. Agility также разрабатывает человекоподобного робота нового поколения, который будет более безопасным при использовании в окружении, наполненном людьми. Существующие гуманоидные роботы, способные поднимать тяжёлые грузы, с точки зрения техники безопасности при соседстве с людьми не так безупречны. Среди автопроизводителей много компаний, которые уже тестируют человекоподобных роботов у себя на предприятиях, особенно среди китайских. Источник: Укажите имя пользователя: и пароль: Войти © 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224 выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является нарушениемроссийского и международного законодательства и возможно только с согласия редакции 3DNews. Во время посещения сайта вы соглашаетесь с использованием нами файлов cookie, метрических программ, Пользовательским соглашением и даёте согласие на обработку и трансграничную передачу персональных данных.
Images (1): 
|
|||||
| Musk vs Zuckerberg : la bataille des robots humanoïdes s’intensifie … | https://www.socialnetlink.org/2025/10/0… | 1 | Feb 28, 2026 16:00 | active | |
Musk vs Zuckerberg : la bataille des robots humanoïdes s’intensifie | SocialnetlinkDescription: Depuis plus de dix ans, Elon Musk et Mark Zuckerberg se livrent une rivalité technologique sans répit. D’un côté, le patron de Tesla et SpaceX a bâti son influence sur les voitures électriques, les fusées réutilisables et, plus récemment, l’intelligence artificielle générative. Content:
Depuis plus de dix ans, Elon Musk et Mark Zuckerberg se livrent une rivalité technologique sans répit. D’un côté, le patron de Tesla et SpaceX a bâti son influence sur les voitures électriques, les fusées réutilisables et, plus récemment, l’intelligence artificielle générative. De l’autre, le fondateur de Meta a imposé Facebook comme réseau social planétaire avant de miser sur la réalité virtuelle et augmentée. Aujourd’hui, leur affrontement prend une nouvelle dimension : les robots humanoïdes. La stratégie de Musk s’articule autour de la puissance mécanique. Avec son robot Optimus, il vise la production de masse et imagine déjà des millions d’unités d’ici 2030, destinées aussi bien aux usines qu’aux foyers. Mais l’ambition pose des défis titanesques : concevoir des humanoïdes fiables, accessibles et industrialisables à grande échelle nécessite de réinventer les chaînes d’assemblage et de surmonter des contraintes logistiques immenses. Zuckerberg, lui, emprunte une voie différente avec Metabot. Ici, l’enjeu n’est pas tant les muscles que le cerveau. Conçu par les équipes de Meta, ce robot mise sur une IA capable d’apprendre et de raisonner, avec des effecteurs mécaniques simples. L’idée est claire : comme le smartphone dont la valeur réside surtout dans ses applications, c’est le logiciel qui rend la machine polyvalente. Le coup de génie de Zuckerberg repose sur une plateforme ouverte aux développeurs et aux fabricants de matériel. Plutôt qu’une approche fermée à la Apple, Meta s’inspire du succès d’Android : proposer une couche logicielle universelle capable d’animer différents robots, sans construire chaque appareil. Pour concrétiser cette vision, Meta a recruté des experts du MIT et de la robotique industrielle, tout en investissant massivement via Reality Labs et Superintelligence Labs. Objectif : imposer un standard logiciel pour la robotique, comme Android l’a fait dans la téléphonie mobile. Au fond, cette confrontation illustre deux philosophies :Musk veut bâtir un corps mécanique perfectionné et Zuckerberg veut fournir un esprit numérique adaptable. Le succès dépendra de l’adoption par le marché. Si Optimus prouve son efficacité dans les usines, il pourrait transformer la productivité mondiale. Si Metabot et son logiciel s’imposent comme standard, Meta pourrait équiper bien plus de robots qu’elle n’en fabriquera. Retrouvez toute l'actu Tech et des Nouveaux Médias en Afrique sur Socialnetlink. Actualités technologiques et startups au Sénégal et en Afrique Numérique- Technologies- Innovation- Startup- Sénégal – Afrique-Bourses et Emplois Nous utilisons des cookies pour vous offrir la meilleure expérience sur notre site. Vous pouvez en savoir plus sur les cookies que nous utilisons ou les désactiver dans paramètres. Une plateforme qui traite de l’actualité des startups, innovations et de l’économie numérique. Nous produisons chaque année, des centaines d’articles, des études de cas, interviews afin de décrypter les écosystèmes innovants d’Afrique. Ce site utilise des cookies afin que nous puissions vous fournir la meilleure expérience utilisateur possible. Les informations sur les cookies sont stockées dans votre navigateur et remplissent des fonctions telles que vous reconnaître lorsque vous revenez sur notre site Web et aider notre équipe à comprendre les sections du site que vous trouvez les plus intéressantes et utiles. Cette option doit être activée à tout moment afin que nous puissions enregistrer vos préférences pour les réglages de cookie.
Images (1): 
|
|||||
| Eva.i-Not just a robot. A Bionic Embodied AI Companion+App by … | http://www.kicktraq.com/projects/878170… | 9 | Feb 27, 2026 08:00 | active | |
Eva.i-Not just a robot. A Bionic Embodied AI Companion+App by Robonova.World :: KicktraqURL: http://www.kicktraq.com/projects/878170019/evai-not-just-a-robot-a-bionic-embodied-ai-companion-app/ Description: Eva.i is a fusion of bionic embodied robotics and an intelligent companion App, designed for real-time interaction and deep engagement. Content: Images (9): 
|
|||||
| Spirit AI Raises $250M to Advance Embodied Intelligence - Ventureburn | https://ventureburn.com/spirit-ai-raise… | 1 | Feb 27, 2026 08:00 | active | |
Spirit AI Raises $250M to Advance Embodied Intelligence - VentureburnURL: https://ventureburn.com/spirit-ai-raises-250m-to-advance-embodied-intelligence/ Description: Spirit AI secures $250M in funding to scale embodied AI and robotics, boosting its valuation and industrial deployment plans in 2026. Content:
By Ekemini Key Takeaways Spirit AI has increased its market value to over 10 billion yuan ($1.4 billion) after dual financing rounds valued at roughly $250 million. This company focuses on developing general-purpose embodied AI models that help robots understand and interact with the physical world. This particular investment shows the growing interest of investors in embodied AI and robotics as the next frontiers of artificial intelligence development. Spirit AI raised about $250 million (¥2 billion) in two successive financing rounds, one of the largest deals in the novel embodied intelligence field, in early 2026. The new investment round pushes Spirit’s valuation over 10 billion yuan (or $1.4 billion) and reinforces the company’s competitive positioning in the AI and robotics world. This round was led by several of the most prominent investment firms, including Yunfeng Capital, Sequoia China, and HongShan Capital, with new investments from urban state-owned investment funds in Chongqing and Hangzhou. Previous investors such as Fortune Capital and Prosperity7 Ventures, together with several early-stage investors, also focused their bets once again, indicating their belief in the company and its technology. Established in 2024, Spirit AI specializes in developing general-purpose embodied intelligence systems for the first time in robots with the ability to perceive and act within the real world using vision, language, and actions. The company’s Spirit v1.5 model, which integrates all of the aforementioned and mechanical capabilities, was open-sourced in early 2026 and has been part of several essential industry benchmarks for task generalization and complexity. Unlike other AI systems that focus on cleanly organized training data, Spirit AI takes a different approach by focusing on what their team calls “dirty data”, which consists of unfiltered, real-life, unorganized, sensed data and data from real interactions that capture the complexity of the real world. Source: Spirit AI This approach, according to the founders, improves robotic generalization and flexibility by teaching models to handle the unexpected across the continuum of manufacturing, logistics, and everyday life. Spirit AI has more than 200,000 hours of interaction data, and more than a million hours are expected by the end of 2026. To achieve this, the company uses its own wearable and sensor systems to capture this data at a much lower cost than traditional robotic teleoperation. This focus on real-world data has practical industrial validation. Spirit AI has partnered with battery manufacturing giant Contemporary Amperex Technology Co., Ltd. (CATL), where its robotic agents have demonstrated the ability to handle complex production tasks, such as manipulating flexible wire harnesses, with industry-leading precision and success rates. More News: NationGraph Raises $18M to Expand AI Public Sector Platform In addition to CATL, Spirit AI has also established some partnerships across other technologies and manufacturing sectors in China, such as JD.com, Huawei, and Xiaomi, which provide access to various ecosystems and engagers for the interaction datasets needed to train sophisticated embodied AI. Spirit AI has also recruited some members from the leading research teams at UC Berkeley, Tsinghua University, and Peking University. The combination of the two has propelled the company to a stage where it can rival the very best in the world in robotics and embodied intelligence. The ability to perceive, understand language, and physically act has become one of the most funded areas of research and development in the world. Many researchers and financiers see embodied AI as an essential and critical point in the evolution of artificial intelligence. It is seen as an evolution that goes beyond mere software development and one that will afford robots the opportunity to perform meaningful work in the physical world. The strong belief of the financiers that an AI system is on the horizon that can understand, reason, manipulate, and directly interact with the physical world is what led to the significant increase in capital raised by Spirit AI. The investment will also help Spirit AI to improve its scalable system. Ekemini I'm a crypto writer with 4+ years of experience passionate about turning big, technical ideas into content anyone can understand. From blockchain to stablecoins to everything in between, I enjoy helping readers stay informed in a space that never stops moving. Disclaimer VentureBurn is a media platform covering the latest in cryptocurrency, artificial intelligence, venture capital, and the startup ecosystem. Opinions expressed on VentureBurn are for informational purposes only and do not constitute investment advice. Before making any high-risk investments in digital assets or emerging technologies, readers should conduct their own due diligence. All transactions and financial decisions are made at your own risk, and any losses incurred are solely your responsibility. VentureBurn does not endorse or recommend the buying or selling of any digital assets and is not a licensed investment advisor. Please note that VentureBurn may participate in affiliate marketing programs. Editor's Choice 10 Easiest Crypto to Mine: Best Profitable Coins In Feb 2026 10 Best Crypto Exchanges in India February 2026 xAI Raises $3 Billion As HUMAIN Expands Strategic Investment Ahead of SpaceX Merger Simile Raises $100M to Predict Human Behavior With AI Best No KYC Crypto Exchanges for Anonymous Trading in 2026 Table of Contents Related articles Allica Raises $155M at $1.2B Valuation to Fuel Growth Astelia Raises $35 Million To Strengthen AI-Powered Cybersecurity MatX Raises $500 Million To Develop AI Chips Competing With Nvidia Nimble Raises $47M To Expand Real-Time Web Search For AI Koah Raises $20.5M To Scale AI-Native Advertising Platform Latest crypto news NODA AI Raises $25M Series A to Advance Defense AI Platform UpGuard Raises $75M in Series C to Boost Cybersecurity Growth. ThreatAware Raises $25M to Scale Cybersecurity with AI NationGraph Raises $18M to Expand AI Public Sector Platform Optimizing Performance on the Melbet App for Seamless Gameplay Rowspace Raises $50M to Power AI for Finance Decisions Croissant Raises $28M to Power Fashion Fintech Ecosystem Profound Raises $96M at $1B Valuation, Redefines AI Marketing Wayve Secures $1.2B to Scale Robotaxi Technology Secfix Raises $12M to Slash SMB Compliance Work by 90% VentureBurn is a global news and insights platform covering the latest trends and developments across the technology landscape – including cryptocurrency, artificial intelligence, venture capital, and startups. Our mission is to empower entrepreneurs, investors, and tech enthusiasts with high-quality journalism, practical guides, and expert analysis to navigate and thrive in the rapidly evolving innovation economy. Category About Subcribe to our newletter Top tech news & guides in crypto, AI, VC, and startups — weekly in your inbox.
Images (1): 
|
|||||
| [Перевод] Tesla Optimus: реальность против обещаний | https://pro-blockchain.com/perevod-tesl… | 10 | Feb 26, 2026 08:00 | active | |
[Перевод] Tesla Optimus: реальность против обещанийURL: https://pro-blockchain.com/perevod-tesla-optimus-real-nost-protiv-obeshchaniy Description: Заявления Илона Маска о роботе Tesla Optimus поражают своей масштабностью. Он утверждал, что Optimus принесёт $10 триллионов долгосрочной прибыли для Tesla, что в конечном итоге... Content:
Заявления Илона Маска о роботе Tesla Optimus поражают своей масштабностью. Он утверждал, что Optimus принесёт $10 триллионов долгосрочной прибыли для Tesla, что в конечном итоге робот составит 80% стоимости Tesla, и что он увеличит оценку компании до впечатляющих $25 триллионов. Однако предыдущие обещания не всегда сбывались: Маск говорил, что Tesla запустит пилотную производственную линию готового Optimus и произведёт 5000 единиц к концу 2025 года, но этого не произошло. Фактически, Tesla недавно анонсировала новую «готовую к производству» третью версию Optimus (что подразумевает, что версия, запланированная к производству в 2025 году, так и не была готова), и что к концу 2027 года производство начнётся на заводе Tesla во Фримонте, где ранее производились Model S и X. Возможно, стоит воспринимать эти громкие заявления с определённой долей скептицизма? Во время недавних отчётных звонков Tesla Маск упомянул нечто, что не только демонстрирует разрыв между реальностью и обещаниями, но и ставит вопросы о понимании технологии. На протяжении месяцев Tesla утверждала, что два робота Optimus работают на их заводах. Это было единственным свидетельством того, что Optimus может быть способен выполнять даже самые базовые задачи автономно. Важно понимать — вся концепция Optimus строится на убеждении инвесторов в том, что это нечто большее, чем просто телеуправляемый робот-аниматроник. Однако, похоже, информация была представлена не полностью. Во время недавнего отчётного звонка выяснилось, что ни один робот Optimus в настоящее время не выполняет продуктивную работу ни на одном из заводов Tesla. Маск заявил, что присутствие Optimus на заводе было «скорее для того, чтобы робот мог учиться», и он никак не помогал в производстве. Иными словами: робот, производство которого планировалось начать в прошлом году, даже не способен помогать на собственных заводах Tesla. Даже в простейших задачах? Он не может, скажем, поднять коробку с болтами и переместить её? Что ещё важнее, почему роботы проходят «обучение» на заводе в первую очередь? Об этом чуть позже. Если вас удивило это открытие, стоило следить внимательнее. Tesla отчаянно пыталась создать иллюзию автономности Optimus, но неоднократно терпела неудачу. Вспомните инцидент на мероприятии в Майами, где Tesla пыталась намекнуть, что роботы Optimus, раздающие бутылки с водой, делают это автономно, пока один из роботов не снял несуществующую гарнитуру, разрушив иллюзию (посмотрите видео здесь). Это ясно показало, что робот управлялся дистанционно. Хотя Tesla прямо не признала это, компания подтвердила, что демонстрационное видео Optimus, складывающего одежду с VR-оператором в кадре, и роботы на мероприятии We Are Robot действительно управлялись дистанционно. До сих пор Optimus не оправдал ожиданий как технологическая демонстрация, поэтому неудивительно, что Tesla не может заставить его помогать на своих заводах. Но последствия этого открытия гораздо глубже, чем может показаться. Для Tesla неудобно, что гуманоидные роботы уже работают на заводах по производству электромобилей. Как я недавно писал (подробнее здесь), BYD в настоящее время тестирует Walker S1 от UBTech на своих заводах, где он выполняет такие задачи, как базовый контроль качества, транспортировка компонентов по заводу и даже установка деталей. Это не должно сильно удивлять, поскольку UBTech продемонстрировал, как Walker S1 выполняет удивительно сложные задачи, такие как игра в теннис и успешное взаимодействие с оборудованием производственной линии. Он явно способен на такие испытания. Хотя, справедливости ради, он выполняет эти задачи не идеально. Как сообщила Financial Times, главный директор по бренду UBTech Майкл Там заявил, что Walker S1 «на 30-50 процентов производительнее людей и только в определённых задачах, таких как укладка коробок и контроль качества». Таким образом, он, скорее всего, всё ещё находится на стадии «технологической демонстрации», и китайским рабочим на заводах пока не о чем беспокоиться. Walker S1 явно более способен, чем Optimus, но даже он пока не может обосновать бизнес-кейс, близкий к заявлениям Маска об Optimus. Это также показывает, что Tesla на самом деле не является лидером рынка и функционально не имеет преимущества перед конкурентами. Так что, даже если гуманоидные роботы представляют собой многотриллионную возможность, компании вроде UBTech, а не Tesla, получат прибыль. Но гуманоидные роботы, вероятно, даже не являются жизнеспособной технологией, не говоря уже о революционной бизнес-возможности. На самом деле, мы давно знаем, что гуманоидные роботы имеют смысл только в научной фантастике. В реальности существует крайне мало случаев, когда гуманоидный робот имеет больше смысла, чем специализированный. Возьмём Walker S1. Простые, недорогие, специализированные роботы могут — и уже делают это — устанавливать детали, транспортировать компоненты по заводам и выполнять базовые проверки качества гораздо быстрее, точнее и экономичнее, чем когда-либо сможет гуманоидный робот. Кроме того, они дешевле и быстрее интегрируются в производственную линию в подавляющем большинстве случаев. Действительно, робототехническая индустрия довольно давно знает, что гуманоидные роботы — не оптимальное направление. Возьмём Криса Уолти, который фактически возглавлял разработку Optimus в Tesla. Он публично заявил, что гуманоидный форм-фактор «не является полезным форм-фактором» и что «мы не созданы для выполнения повторяющихся задач снова и снова. Так зачем брать гиперсубоптимальную систему, которая на самом деле не предназначена для повторяющихся задач, и заставлять её делать повторяющиеся задачи?» Или Брэда Портера, бывшего вице-президента по робототехнике в Amazon, который сказал, что «гуманоиды — неправильное решение для большинства задач» и что гораздо более простые решения, такие как колёса вместо двуногих ног, почти всегда дешевле и надёжнее. Затем есть Gartner, которая указывает, что гуманоидные роботы непригодны из-за их высокой стоимости, проблем с интеграцией, ненадёжности и недостаточных возможностей. Учитывая доступность лучших вариантов, таких как специализированные роботы или человеческие работники, так будет ещё долго. Если подумать, эта настойчивость имитировать человека имеет мало смысла. Если бы люди эволюционировали тысячелетиями для работы на автомобильном заводе, они бы не выглядели как мы. Точно так же, зачем тратить средства и усилия на то, чтобы заставить гуманоидного робота пылесосить, когда можно просто поручить это Roomba, который справится гораздо лучше? Настаивать на том, чтобы роботы выглядели и функционировали как люди — всё равно что проектировать автомобиль, напоминающий лошадь и работающий как лошадь. Это обратная логика. Конечно, нам нравится идея гуманоидных роботов, потому что мы можем их антропоморфизировать, но фактически использовать их, даже если они способны выполнять задачу, не имеет смысла. Помните тот момент, о котором я просил помнить? Тот факт, что Optimus «обучается» на заводе? Это своего рода индикатор проблем Optimus. Tesla использует два основных метода для «обучения» ИИ Optimus: обучение подражанием на основе видео и обучение через телеоперирование. Это потому, что Optimus основан на тех же ИИ и компьютерах ИИ, что и FSD Tesla, именно так они обучают ИИ FSD. И мы все знаем, как это идёт, не так ли? Но, как указал блестящий австралийский специалист по робототехнике Родни Брукс, эти методы обучения имеют серьёзные и очевидные недостатки. Начнём с обучения подражанием на основе видео. Это процесс «обучения» ИИ выполнению задач, которые вы хотите, чтобы робот выполнял, путём показа ИИ видео людей, выполняющих такие задачи. Брукс называет этот подход «чистым фантазированием». Почему? Потому что мы, люди, используем гораздо больше, чем просто визуальные данные для выполнения этих задач. Наше чувство осязания невероятно мощное. Наши руки имеют 17 000 специализированных, высокочувствительных тактильных рецепторов, способных обнаруживать изменения размером до 40 мкм со скоростью примерно один миллиард бит в секунду. Другими словами, одна человеческая рука передаёт нашему мозгу более двух гигабайт невероятно детальных данных каждую секунду! Мы полагаемся на это значительно больше, чем на визуальные данные, для выполнения даже самых базовых задач. Подумайте так: вы можете сложить рубашку с завязанными глазами довольно легко, но вам будет очень трудно сложить её, используя щипцы вместо рук. Брукс указывает, что обучение подражанием на основе видео обучает ИИ на неполных данных, оставляя у него огромное слепое пятно, что означает, что он не может эффективно воспроизвести человека из обучающих данных. Решение Маска для этой проблемы выравнивания данных, похоже, заключается в обучении через телеоперирование. Это когда вы используете VR для управления роботом для выполнения задачи и используете это как обучающие данные для ИИ. Таким образом, собранные данные теоретически лучше соответствуют тому, к чему имеет доступ ИИ, обеспечивая лучшее обучение. Но Брукс указывает на серьёзные недостатки и этого подхода. ИИ может работать только так же хорошо, как эти телеоператоры (или, что более реалистично, не так хорошо, как телеоператоры), и эти телеоператоры действительно с трудом выполняют даже базовые задачи при управлении роботом. VR-костюмы, которые используют эти телеоператоры, имеют очень ограниченный контроль пальцев и ещё меньше силовой обратной связи, серьёзно ограничивая чувство осязания телеоператора. Размеры робота могут отличаться от размеров телеоператора, нарушая их погружение. Восприятие глубины телеоператора может быть неточным из-за того, что две камеры, используемые для восприятия мира с восприятием глубины и для предоставления VR-видеоизображения, имеют разное межзрачковое расстояние. Чувство равновесия телеоператора и проприоцепция (ощущение того, где находятся ваши конечности в пространстве) постоянно отличаются от робота. Всё это означает, что этим телеоператорам действительно сложно телеоперировать гуманоидными роботами, поскольку данные, которые им передаются, часто сбивают с толку, а их чувства серьёзно притуплены. Эта проблема очевидна из-за постоянных неудач Optimus при телеоперировании. И вот в чём дело: если эти телеоператоры с трудом выполняют даже базовые задачи через Optimus, то и ИИ тоже будет, так как он может только плохо копировать их. Тот факт, что подход, похоже, полностью игнорирует эти фундаментальные основы обучения ИИ и предполагает, что видеоподражания и обучения телеоператора будет достаточно для того, чтобы Optimus взял на себя миллионы рабочих мест, вызывает вопросы. Это отсутствие понимания основной технологии, стоящей за Optimus, также может объяснить, почему Tesla обучает несколько роботов Optimus на своём заводе, а не проводит испытания, как Walker S2. Tesla почти наверняка пытается провести обучение видеоподражанием и телеоперированием базовым задачам производственной линии непосредственно на производственной линии. Таким образом, они могут получить доступ к людям и задачам, на которых они хотят обучить ИИ, и при этом сказать: «На заводе есть Optimus». Но Tesla обучает роботов Optimus как минимум три, если не четыре года. Тот факт, что Tesla ещё не провела испытания интеграции Optimus в производственные линии Tesla даже для поразительно базовых задач после всего этого времени, показателен. Подобные испытания являются критической частью разработки и доказательством концепции для инвесторов. Тот факт, что Tesla ещё даже не достигла этого фундаментального шага, настоятельно предполагает, что её подход к обучению ИИ гуманоидных роботов имеет фундаментальные проблемы и серьёзно ограничивает развитие, как и предсказывал Брукс. Говоря о методах обучения ИИ и их ограничениях — вы можете сами увидеть, насколько сложны эти технологии. Понимание того, как работают современные ИИ-модели, их сильных и слабых сторон, требует практического опыта. Сервисы вроде BotHub дают возможность экспериментировать с различными моделями ИИ — от языковых моделей до систем компьютерного зрения — чтобы понять на практике те самые проблемы обучения и ограничений, о которых мы говорим. Вы можете протестировать, как разные модели справляются с визуальными задачами, обработкой текста и другими функциями, которые критичны для робототехники. Для доступа не требуется VPN, можно использовать российскую карту. По ссылке вы можете получить 300 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас! Optimus можно охарактеризовать как амбициозный, но проблемный проект. Заявления о бизнес-стороне гуманоидной робототехники не соответствуют реальности, а конкуренты значительно опережают Tesla. Кроме того, очевидны проблемы с пониманием ИИ и робототехники, поскольку разрыв между реальностью и ожиданиями значителен. Будет интересно наблюдать за развитием этой ситуации в ближайшие годы и увидеть, как технология будет развиваться дальше. Источник Теги Категория Дата 04.12.25 21:45 elizabethrush89 God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1 04.12.25 21:45 elizabethrush89 God bless Capital Crypto Recover Services for the marvelous work you did in my life, I have learned the hard way that even the most sensible investors can fall victim to scams. When my USD was stolen, for anyone who has fallen victim to one of the bitcoin binary investment scams that are currently ongoing, I felt betrayal and upset. But then I was reading a post on site when I saw a testimony of Wendy Taylor online who recommended that Capital Crypto Recovery has helped her recover scammed funds within 24 hours. after reaching out to this cyber security firm that was able to help me recover my stolen digital assets and bitcoin. I’m genuinely blown away by their amazing service and professionalism. I never imagined I’d be able to get my money back until I complained to Capital Crypto Recovery Services about my difficulties and gave all of the necessary paperwork. I was astounded that it took them 12 hours to reclaim my stolen money back. Without a doubt, my USDT assets were successfully recovered from the scam platform, Thank you so much Sir, I strongly recommend Capital Crypto Recover for any of your bitcoin recovery, digital funds recovery, hacking, and cybersecurity concerns. You reach them Call/Text Number +1 (336)390-6684 His Email: [email protected] Contact Telegram: @Capitalcryptorecover Via Contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1 05.12.25 08:35 into11 The digital world of cryptocurrency offers big chances, but it also hides tricky scams. Losing your crypto to fraud feels awful. It can leave you feeling lost and violated. This guide tells you what to do right away if a crypto scam has hit you. These steps can help you get funds back or stop more trouble. Knowing what to do fast can change everything,reach marie ([email protected] and whatsapp:+1 7127594675) 05.12.25 08:48 Tonerdomark SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected] 06.12.25 01:44 Tonerdomark SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected] 06.12.25 01:48 Tonerdomark SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected] 06.12.25 10:36 Thomas Muller YOU CAN REACH OUT TO GREAT WHIP RECOVERY CYBER SERVICES FOR HELP TO RECOVER YOUR STOLEN BTC OR ETH BACK WHATSAPP +1(208)713-0697 I once fell victim to online investment scheme that cost me a devastating €254,000. I’m Thomas Muller from Berlin, Germany. The person I trusted turned out to be a fraud, and the moment I realized I’d been deceived, my entire world stopped. I immediately began searching for legitimate ways to recover my funds and hold the scammer accountable. During my search, I came across several testimonies of how Great Whip Recovery Cyber Services helped some people recover money they lost to cyber fraud, I contacted Great Whip Recovery Cyber Service team and provided all the evidence I had. Within about 36 hours, the experts traced the digital trail left by the fraudster, the individual was eventually tracked down and I recovered all my money back. You can contact them with, website https://greatwhiprecoveryc.wixsite.com/greatwhip-site text +1(406)2729101 email [email protected] 06.12.25 10:36 Thomas Muller YOU CAN REACH OUT TO GREAT WHIP RECOVERY CYBER SERVICES FOR HELP TO RECOVER YOUR STOLEN BTC OR ETH BACK WHATSAPP +1(208)713-0697 I once fell victim to online investment scheme that cost me a devastating €254,000. I’m Thomas Muller from Berlin, Germany. The person I trusted turned out to be a fraud, and the moment I realized I’d been deceived, my entire world stopped. I immediately began searching for legitimate ways to recover my funds and hold the scammer accountable. During my search, I came across several testimonies of how Great Whip Recovery Cyber Services helped some people recover money they lost to cyber fraud, I contacted Great Whip Recovery Cyber Service team and provided all the evidence I had. Within about 36 hours, the experts traced the digital trail left by the fraudster, the individual was eventually tracked down and I recovered all my money back. You can contact them with, website https://greatwhiprecoveryc.wixsite.com/greatwhip-site text +1(406)2729101 email [email protected] 06.12.25 10:39 michaeldavenport238 I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1 06.12.25 10:42 michaeldavenport238 I was recently scammed out of $53,000 by a fraudulent Bitcoin investment scheme, which added significant stress to my already difficult health issues, as I was also facing cancer surgery expenses. Desperate to recover my funds, I spent hours researching and consulting other victims, which led me to discover the excellent reputation of Capital Crypto Recover, I came across a Google post It was only after spending many hours researching and asking other victims for advice that I discovered Capital Crypto Recovery’s stellar reputation. I decided to contact them because of their successful recovery record and encouraging client testimonials. I had no idea that this would be the pivotal moment in my fight against cryptocurrency theft. Thanks to their expert team, I was able to recover my lost cryptocurrency back. The process was intricate, but Capital Crypto Recovery's commitment to utilizing the latest technology ensured a successful outcome. I highly recommend their services to anyone who has fallen victim to cryptocurrency fraud. For assistance contact [email protected] and on Telegram OR Call Number +1 (336)390-6684 via email: [email protected] you can visit his website: https://recovercapital.wixsite.com/capital-crypto-rec-1 07.12.25 08:43 Tonerdomark SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected] 08.12.25 02:17 liam I recently fell a victim of cryptocurrency investment and mining scam, I lost almost all my life savings to BTC scammers. I almost gave up because the amount of crypto I lost was too much. So I spoke to a friend who told me about ANTHONYDAVIESTECH company. I Contacted them through their email and i provided them with the necessary information they requested from me and they told me to be patient and wait to see the outcome of their job. I was shocked after two days my Bitcoin was returned to my Wallet. All thanks to them for their genius work. I Contacted them via Email: anthonydaviestech @ gmail . com all thanks to my friend who saved my life 08.12.25 09:07 Tonerdomark SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = [email protected] 09.12.25 00:18 swanky For a long time, I had heard tales of individuals striking it rich through cryptocurrency investments, but I had little knowledge of how the system operated. The potential for financial gain piqued my interest, and I decided to dive in and invest. To help me navigate this complex landscape, I joined a group of online traders who promised to guide me through the investment process. Their confidence and expertise made me feel reassured about my decision.After spending some time learning from them and observing their trading strategies, I felt compelled to invest a substantial amount of money to which i lost, now in search of recovering my funds i got referred to anthonydavies on telegram a funds recovery specialist with his team help i was able to get back $300000 of my usdc back. you can reach him via anthonydaviestech AT gmail dot com 09.12.25 01:01 Tonerdomark SYLVESTER BRYANT WAS A PROFESSIONAL/ RELIABLE HACKER AND HIGHLY RECOMMENDED I’m very excited to speak about him as a Bitcoin Recovery agent, this cyber security company was able to assist me in recovering my stolen funds in cryptocurrency. I’m truly amazed by their excellent service and professional work. I never thought I could get back my funds until I approached them with my problems and provided all the necessary information. It took them time to recover my funds and I was amazed. Without any doubt, I highly recommend Sylvester for your BITCOIN, USDC, USDT, ETH Recovery, for all Cryptocurrency recovery, digital funds recovery, hacking Related issues, contact Sylvester Bryant professional services waapp only= +1 512 577 7957 or + 44 7428 662701 EMAIL = Yt7CRACKER@gmail. com 09.12.25 05:44 swanky For a long time, I had heard tales of individuals striking it rich through cryptocurrency investments, but I had little knowledge of how the system operated. The potential for financial gain piqued my interest, and I decided to dive in and invest. To help me navigate this complex landscape, I joined a group of online traders who promised to guide me through the investment process. Their confidence and expertise made me feel reassured about my decision.After spending some time learning from them and observing their trading strategies, I felt compelled to invest a substantial amount of money to which i lost, now in search of recovering my funds i got referred to anthonydavies on telegram a funds recovery specialist with his team help i was able to get back $300000 of my usdc back. you can reach him via anthonydaviestech AT gmail dot com 09.12.25 10:24 lane3215 It is distressing to lose USDT to a bitcoin wallet hack. Although challenging, recovering stolen USDT is feasible. Your chances increase if you move swiftly and strategically. Marie can help you with reporting the theft, recovering USDT, and taking immediate action. You can reach her via mail at [email protected], WhatsApp at +1 7127594675. 09.12.25 10:25 lane3215 It is distressing to lose USDT to a bitcoin wallet hack. Although challenging, recovering stolen USDT is feasible. Your chances increase if you move swiftly and strategically. Marie can help you with reporting the theft, recovering USDT, and taking immediate action. You can reach her via mail at [email protected], WhatsApp at +1 7127594675. 09.12.25 14:16 Matt Kegan Grateful i came across SolidBlock Forensics. After investing in crypto trade and couldn't make withdrawals, it dawned on me something was wrong. They kept on asking for taxes, fees for maintenance, and more money for admin reasons. But being represented by SolidBlock Forensics, i was able to file reports, and finally, received all my investments with returns. Its great to know we have professionals that handle such issues and get the job done. 12.12.25 22:38 swanky After reading some reviews on how [anthonydaviestech AT gmail dot (c om) helps people recover money and Cryptocurrencies lost to scammers, I decided to contact him to help me recover mine which I lost in february 2025. To my surprise he was able to trace the USDT from the first wallet to all the wallets it has been sent to. He moved them out of those wallets and returned them back to mine and even added extra to me, it felt like magic. 13.12.25 08:22 Natasha Williams I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101 13.12.25 08:23 Natasha Williams I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101 13.12.25 08:28 Natasha Williams I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101 13.12.25 15:29 Anthonymorphy30 ⬛️ ARE YOU SEEKING TO RECOVER YOUR LOST FUNDS FROM INVESTMENT/TRADING SCAM OR ROMANCE SCAM??? OR YOU NEED LEGIT HACKING SERVICES SUCH AS PHONE HACK, WEBSITE HACK AND MORE????? TAKE YOUR TIME TO READ ⬛️ ⬛️ We have received numerous complaints of fraud associated with Romance Scam, websites that offers opportunities for Capital Investments, bitcoin investments and Trading on an Internet-based trading platforms. Most Of theese complaints falls into these theee categories: 1. 🔘Refusal to credit customers accounts or reimburse funds to customers: These complaints typically involves customers who have deposited money into their trading or investment account and eventually got deprived from withdrawing their capital and profits by the trading platforms. 2. 🔘Manipulation of software to generate losing trades: These complaints alleged that the Internet-based Investment and trading platforms manipulate the trading software to distort the Trading prices and payouts in order to ensure that the trade results in a Loss. 3. 🔘 Romance Scam where a scammer pretends to have romantic interest in someone to gain their trust—and then uses that trust to steal money or personal information. ⬛️ Most people have lost their hard earned money through these types of Scams but don’t know how to get a Legitimate Funds Recovery Expert. Truth be told, the only Specialists that is capable of retrieving your lost funds to these scams are Team of professional hackers and cyber forensic experts and this is where FUNDS RETRIEVAL PANEL comes in. FUNDS RETRIEVAL PANEL is an amalgamation of top notch Hackers, Cyber forensic Experts, Software Engineers and Backend Gurus who are dedicated to helping victims retrieve their Lost funds from online scams and frauds. We are the Leading Funds Recovery Expert who know various Retrieval Techniques and Strategies that suits different scenarios of Scam. With years of experience in the financial and tech sectors, we are the trusted solution for individuals looking to recover lost money. CONTACT US NOW to schedule your free consultation and start the process of recovering your funds. 🌍 www.fundsretrievalpanel.com 🌍 📩 [email protected]✉️ ☑️ We Also have a segregated Department that focuses on other LEGIT HACKING SERVICES SUCH AS: ▪️ PHONE HACKING & CLONING : very useful for getting evidence from someone else’s phone by gaining full access to all they do on their phones. ▪️ WEBSITE AND DATABASE HACKING 💻 ▪️ SOCIAL MEDIA ACCOUNTS HACKING 📱 ▪️LOCATION TRACKING 📌 CONTACT: 📩 [email protected] 13.12.25 18:52 James Robert I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101 13.12.25 18:54 James Robert I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101 18.12.25 12:12 Anthony Irvin I forgot my password 🔑 -- But they helped me recover my entire wallet. Successful Brute-Force Hack... On January 16, 2023, INTELLIGENCE CYBER WIZARD successfully hacked my Langerhans.DAT Android DOGECOIN wallet to recover the lost/forgotten spending PIN, necessary for spending funds. It took them only three (3) days to complete the task. It turned out that the spending PIN was only ten (10) digits long, which I had mistakenly believed to be twelve. Once Intelligence Cyber Wizard discovered and recited the full ten-digit PIN to me, based on "clues" I had given them and that only I knew, it reminded me a bit of when I set up the PIN back in 2015. In my case, I made the mistake of not writing it down. The wallet file in this case contained a little over 10.5 million DOGECOINs installed on it, spread across a total of 15 DOGE public wallet addresses and their corresponding private keys. When I acquired the 10.5 million coins in 2015, the total cost to me was only around $1,500, based on the current face value of DOGE at the time, which was approximately $0.0001 per coin. The wallet file had been inaccessible to me since December 27, 2015, after I realized I had forgotten my spending PIN. Before finding Intelligence Cyber Wizard, I had had several other encounters with people who were unsuccessful in recovering the wallet's spending PIN. So, as it turned out, I actually ended up much better off financially because I had forgotten my spending PIN. Had I not forgotten, I would have traded or sold the 10.5 million coins in question during the 2017 cryptocurrency bull run, along with another 40 million DOGECOIN that I sold that year. Even after accounting for a portion of the recovered coins that was awarded to Intelligence Cyber Wizard for their efforts, I still gained a significant financial advantage. Therefore, I am deeply grateful to Intelligence Cyber Wizard, for the swift and successful recovery of my wallet. Their efforts have undoubtedly had a truly transformative impact on my life in the long run. I highly recommend Intelligence Cyber Wizard services if you or someone you know has a wallet that needs hacking and whose password or spending PIN has been lost or forgotten. Contact Intelligence Cyber Wizard via WhatsApp or email. WhatsApp +1 (219) 424-7566 Email: intelligencecyberwizard @ gmail.com Email: intelligencecyberwizard @ cyber-wizard.com Website: https: //intelligence-cyber-wizard.web node.page 18.12.25 13:24 Regency Victorian I was scammed and left penniless, until a cryptocurrency recovery expert helped me. INTELLIGENCE CYBER WIZARD - Cryptocurrency Recovery. I was scammed out of a huge amount of money and, devastated, I started looking for help. Someone recommended an expert and private investigator, Intelligence Cyber Wizard. I emailed him, and as soon as I explained what had happened, he immediately told me it had all been a setup. He put my case together, and within a few days, we got a result: I recovered all my money! Intelligence Cyber Wizard was amazing, professional, and efficient; he guided me through the entire process. I can't thank him and his forensic team enough. I can live again! His contact information is below. WhatsApp +1 (219) 424-7566 Email: [email protected] Email: [email protected] Website: https://intelligence-cyber-wizard.webnode.page 18.12.25 20:54 James Robert I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101 18.12.25 20:55 James Robert I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101 18.12.25 21:02 James Robert This company call GREAT WHIP RECOVERY CYBER SERVICES was honest from the beginning. No false promises – just results. Call:+1(406)2729101 18.12.25 21:02 James Robert I am James Robert from Chicago. Few months ago, I fell victim to an online Bitcoin investment scheme that promised high returns within a short period. At first, everything seemed legitimate, their website looked professional, and the people behind it were very convincing. I invested a significant amount of money about $440,000 with the way they talk to me into investing on their bitcoin platform. Two months later I realized that it was a scam when I could no longer have access to my account and couldn’t withdraw my money. At first, I lost hope that I wouldn't be able to get my money back, I cried and was angry at how I even fell victim to a scam. For days after doing some research and seeking professional help online, I came across GREAT WHIP RECOVERY CYBER SERVICES and saw how they have helped people recover their money back from scammers. I reported the case immediately to them and gather every transaction detail, documentation and sent it to them. Today, I’m very happy because the GREAT WHIP RECOVERY CYBER SERVICES help me recover all my money I was scammed. You can contact GREAT WHIP RECOVERY CYBER SERVICES if you have ever fallen victim to scam. Email: [email protected] or Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site or Call +1(406)2729101 20.12.25 16:03 VERONICAFREDDIE809 Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035. 06.01.26 00:54 justineluscacio I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900) 06.01.26 15:05 justineluscacio I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900) 06.01.26 16:06 justineluscacio Successful Bitcoin Recovery Testimonials in Europe, USA, UK, Asia, Canada, South Africa. 06.01.26 16:07 justineluscacio Successful Bitcoin Recovery Testimonials in Europe, USA, UK, Asia, Canada, South Africa. BITCOIN RECOVERY EXPERT USDT RECOVERY EXPERT ETH RECOVERY EXPERT How do I hire a hacker to help me recover my lost funds? How to Recover Money Lost to an Online Scam How to recover lost or stolen cryptocurrency Best recovery experts for cryptocurrency DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900) 06.01.26 16:14 justineluscacio I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900) 06.01.26 17:03 Matt Kegan Reach out to SolidBlock Forensics if you want to get back your coins from fake crypto investment or your wallet was compromised and all your coins gone. SolidBlock Forensics provide deep ethical analysis and investigation that enables them to trace these schemes, and recover all your funds. Their services are professional and reliable. http://www.solidblockforensics.com 09.01.26 17:11 VERONICAFREDDIE809 Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035. 10.01.26 14:28 justineluscacio I hope this review gets to as many as possible because I am sure it will save many. On March 15, I received a message on Telegram inviting me to join a Cryptocurrency investment group. At first, I thought it was a harmless invitation. I joined and began to see how a specific crypto and forex trader was helping many people and even gifting out Bitcoin to his loyal followers. I was thrilled; many people in the group were reporting their daily successes and how they were earning a substantial amount. I was jealous; I saw people making a lot of money, but not me. I became furious and decided to contact the group's admin, not realizing I had fallen for their trap. That Telegram channel was a hoax, controlled by an organized team of scammers. Within 3 months of being on that platform, I had given out a whopping 11 Bitcoin in total. I was lost when I was logged out of the investment website and blocked from accessing their Telegram channel. I tried all the means I could think of at that moment, all to no avail. It went from days to weeks, and I still couldn't get back my lost Bitcoin. I was on Medium when I came across a review about digital assets recovery companies. There were quite a few of them, but DuneNectarOnlineExpert caught my attention. I copied their email ( Support @ Dunenectaronlineexpert . Com ), filed a report, and my task was attended to with utmost urgency. After back and forth with this team of cybersecurity experts, DuneNectarOnlineExpert successfully traced the Bitcoin to the scammers' wallet, and it was successfully reclaimed. The team of DuneNectarOnlineExpert was incredibly helpful in recovering my lost Bitcoin. Telegram: T.me/Dunenectarwebexpert WhatApp: +(1252-271-8900) 11.01.26 03:16 austinjarvis I lost £75,000 in a Bitcoin scam. Scammers used deepfake videos to make it seem like Elon Musk himself pitched the deal. These deepfakes swap faces onto real people with AI. They look so real you can't spot the trick at first. They drew me in with talk of fast cash. Double your money in weeks, they said. Videos showed Musk explaining simple steps to join. I bit. Sent my Bitcoin bit by bit. First small amounts worked. Then I dumped my full savings. Boom. Funds vanished. No more contact. My bank account empty. Bills piled up. Loans to cover rent and food. Sleep gone. Stress hit hard. Felt like my whole life crashed. A mate saw my pain. He shared his own story from last year. Same scam type. He pointed me to Sylvester, a recovery agent. Reach him at Yt7cracker@gmail . com. Or WhatsApp + 1 512 577 7957. Or + 44 7428 662701. Sylvester got to work fast. Tracked the blockchain trails. Dealt with exchanges. Fought the scammers' tricks. Weeks later, my Bitcoin came back. Even the profits they promised. Debt lifted. Life back on track. If you're hit, contact him now. 12.01.26 16:24 VERONICAFREDDIE809 Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035. 19.01.26 13:04 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 19.01.26 13:05 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 19.01.26 15:53 VERONICAFREDDIE809 Earlier this year, I made a mistake that changed everything. I downloaded what I thought was a legitimate trading app I’d found through a Telegram channel. At first, everything looked real until I tried to withdraw. My entire investment vanished into a bot account, and that’s when the truth hit me: I had been scammed. I can’t describe the feeling. It was as if the ground dropped out from under me. I blamed myself. I felt stupid, ashamed, helpless every painful emotion at once. For a while, I couldn’t even talk about it. I thought no one would understand. But then I found someone Agent Jasmine Lopez ([email protected]) ,She didn’t brush me off or judge me. She took my fear seriously. She followed leads I didn’t even know existed, and identified multiple off-chain indicators and wallet clusters linked to the scammer network, she helped me understand what had truly happened behind the scenes. For the first time since everything fell apart, I felt hope. Hearing that other people students, parents, hardworking people had been targeted the same way made me realize I wasn’t alone. What happened to us wasn’t stupidity. It was a coordinated attack. We were prey in a system built to deceive. And somehow, through all the chaos, Agent Jasmine stepped in and shined a light into the darkest moment of my life. I’m still healing from the experience. It changed me. But it also reminded me that even when you think you’re at the end, sometimes a lifeline appears where you least expect it. Contact her at [email protected] WhatsApp at +44 736-644-5035. 22.01.26 07:48 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 22.01.26 07:50 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 22.01.26 10:42 Tonerdomark I got my money back from the Elon Musk scam. It cost me over 1 BTC and $55,000 in Dogecoin. Scammers vowed to double investments. Their sites seemed real. Fraud was tough to catch early. They hooked me with fast doubles in weeks or months. Videos showed Musk promising giveaways and gains. I bought in. I sent Bitcoin and Dogecoin in bits at first. Small sends worked. Then I wired my full savings. It vanished quick. No answers came. Bank account empty. Bills piled up. Loans covered rent and food. Sleep fled. Stress hit hard. Life crumbled. A friend spotted my trouble. He told of his scam loss last year. Same old plays. He pointed me to Sylvester Bryant, a recovery expert. Email Yt7cracker@gmail. com. WhatsApp +1 512 577 7957 or +44 7428 662701. Sylvester acted fast. He tracked blockchain trails. Dealt with exchanges. Outsmarted the scammers. In weeks, my Bitcoin came back. Even their phony profits too. Debts gone. Life back on track. Got hit? Contact him now. 22.01.26 19:25 Angela_Moore Help to recover money from elon musk giveaway scam I got my money back from the Elon Musk scam. It cost me over 1 BTC and $55,000 in Dogecoin. Scammers vowed to double investments. Their sites seemed real. Fraud was tough to catch early. They hooked me with fast doubles in weeks or months. Videos showed Musk promising giveaways and gains. I bought in. I sent Bitcoin and Dogecoin in bits at first. Small sends worked. Then I wired my full savings. It vanished quick. No answers came. Bank account empty. Bills piled up. Loans covered rent and food. Sleep fled. Stress hit hard. Life crumbled. A friend spotted my trouble. He told of his scam loss last year. Same old plays. He pointed me to Sylvester Bryant, a recovery expert. Email Yt7cracker@gmail. com. WhatsApp +1 512 577 7957 or +44 7428 662701. Sylvester acted fast. He tracked blockchain trails. Dealt with exchanges. Outsmarted the scammers. In weeks, my Bitcoin came back. Even their phony profits too. Debts gone. Life back on track. Got hit? Contact him now. 23.01.26 07:35 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 23.01.26 07:35 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 26.01.26 10:36 alksnismareks It all started when I decided to explore online trading as a way to grow my savings. Like many, I trusted what appeared to be a legitimate platform, only to find myself trapped in a nightmare. After making consistent trades and finally deciding to withdraw my profits, I was met with silence. My account was suddenly restricted—no warning, no explanation. Every attempt to contact the broker went unanswered or was met with vague, dismissive replies. For three long, agonizing months, I lived in uncertainty. I couldn’t sleep at night. I replayed every email, every transaction, wondering if I’d made a mistake. But deep down, I knew the truth: I hadn’t done anything wrong. The broker had simply decided to lock me out and keep my money. During that time, I felt completely powerless—like I was shouting into a void. The stress affected my health, my relationships, and my ability to focus on anything else. There were days I truly believed that $167,000 was gone forever, lost to the shadows of the unregulated online trading world. I even began to accept it as a painful lesson—one that would cost me dearly but might teach me to be more cautious in the future. But something inside me refused to surrender completely. That’s when I discovered TechY Force Cyber Retrieval. At first, I was cautious—after being scammed once, I didn’t want to fall victim again. But everything about TechY Force felt different. They were transparent from the start. No grand promises, no pressure tactics. Just clear, professional communication and a deep understanding of how these fraudulent brokers operate. Most importantly, they are a licensed specialist in binary options and forex fund recovery, which gave me the confidence to move forward. From our very first consultation, their team treated my case with urgency and empathy. They walked me through the entire process, explained the legal and technical avenues available, and assured me they would handle every detail. They collected documentation, analyzed transaction trails, and engaged directly with the payment processors and the broker using precise, strategic methods I never could have navigated on my own. What happened next was nothing short of miraculous. Within weeks, the broker—who had ignored me for months—began responding. And then, without any further drama or delays, my full $167,000 USD was returned to me. No deductions. No hidden fees. Just clean, complete recovery. The relief I felt was indescribable. It wasn’t just about the money—it was about reclaiming control, restoring trust, and proving that even in the face of deception, there are still good people who fight for what’s right. If you’ve been locked out of your trading account, scammed by a fake investment platform, or had your funds unjustly withheld, please know this: you are not alone, and your money may not be lost forever. Thanks to TechY Force Cyber Retrieval, I got my life back. Their expertise, integrity, and unwavering commitment turned my despair into deliverance. I cannot recommend them highly enough. To anyone reading this in distress: don’t give up. Reach out. Take that step. Because if someone like me—broken, doubtful, and nearly hopeless—can recover every dollar… so can you. WhatsApp them + 156 172 63 697 With heartfelt thanks and renewed hope, — A Recovered and Grateful Client 26.01.26 23:21 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 26.01.26 23:21 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 26.01.26 23:21 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 27.01.26 01:18 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 27.01.26 01:19 Kelvin Alfons Hello everyone. I’d like to share my personal experience from one of the most challenging times in my life. I’m based in Sydney, Australia, and on November 13, 2025, I fell victim to a fraudulent cryptocurrency investment platform that promised substantial financial growth. Believing their claims, I invested a total of $220,000 with the expectation of earning solid returns. However, when I attempted to withdraw my funds, all communication abruptly stopped. My calls were ignored, my emails went unanswered, and I was left feeling completely powerless. Like many others, I had heard that Bitcoin transactions are impossible to trace, so I assumed my money was lost forever. After some time, I discovered information about GREAT WHIP RECOVERY CYBER SERVICES, a reputable digital asset recovery firm. I decided to reach out to them, and to my astonishment, they were able to help me recover the full amount I had lost. I’m sharing my story in the hope that it may help someone else who is going through a similar situation and looking for support. Their contact is, Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site Email:[email protected] Call: +1(406)2729101 27.01.26 09:29 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 27.01.26 09:29 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 27.01.26 09:32 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 29.01.26 05:03 joyo The digital world of cryptocurrency offers big chances, but it also hides tricky scams. Losing your crypto to fraud feels awful. It can leave you feeling lost and violated. This guide tells you what to do right away if a crypto scam has hit you. These steps can help you get funds back or stop more trouble. Knowing what to do fast can change everything,reach marie ([email protected] and whatsapp:+1 7127594675) 30.01.26 08:23 joseph67t It's a joy to write this review. Since I began working with Marie at the beginning of 2018, the service has been outstanding. Hackers stole my monies, and I was frightened about how I would get them back. I didn't know where to begin, consequently it was a nightmare for me. But once my friend told me about ([email protected] and whatsap:+1 7127594675), things became simple for me. I'm glad she was able to get my bitcoin back so I could start trading on Binance again! 31.01.26 00:55 harristhomas7376 "In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 31.01.26 00:55 harristhomas7376 "In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 02.02.26 18:52 Christopherbelle Sylvester Bryant is a top crypto recovery agent! Then I contacted them with my story that i have been scammed. It took time, yet my stolen crypto was recovered . Need help? Reach out to Sylvester on WhatsApp at +1 512 577 7957 or +44 7428 662701. Or email yt7cracker@gmail . com. 03.02.26 08:05 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 03.02.26 08:05 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 04.02.26 16:23 borutaralf GREAT WHIP RECOVERY CYBER SERVICES TRUSTED EXPERTS IN ONLINE RECOVERY SOLUTIONS PHONE CALL:+1(406)2729101 I was unfortunately deceived and scammed out of $88,000 by someone I trusted to manage my funds during a transaction we carried out together. The experience left me deeply disappointed and hurt, realizing that someone could betray that level of trust without any remorse. Determined to seek justice and recover what was stolen, I began searching for legal assistance and came across numerous testimonials about GREAT WHIP RECOVERY CYBER SERVICES, a group known for helping victims recover lost funds. From what I learned, they have successfully assisted many people facing similar situations, returning stolen funds to their rightful owners in a remarkably short time. In my case, the GREAT WHIP RECOVERY CYBER SERVICES were able to recover my funds within just 48 hours, which was truly unbelievable. Even more reassuring was the fact that the scammer was identified, located, and eventually arrested by local authorities in his region. That outcome brought a great sense of relief and closure. I hope this information helps others who have lost their hard-earned money due to misplaced trust. If you’re in a similar situation, you can contact them through their info below to seek help in recovering your stolen funds. Email: [email protected] Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site Phone Call:+1(406)2729101 04.02.26 16:24 borutaralf GREAT WHIP RECOVERY CYBER SERVICES TRUSTED EXPERTS IN ONLINE RECOVERY SOLUTIONS PHONE CALL:+1(406)2729101 I was unfortunately deceived and scammed out of $88,000 by someone I trusted to manage my funds during a transaction we carried out together. The experience left me deeply disappointed and hurt, realizing that someone could betray that level of trust without any remorse. Determined to seek justice and recover what was stolen, I began searching for legal assistance and came across numerous testimonials about GREAT WHIP RECOVERY CYBER SERVICES, a group known for helping victims recover lost funds. From what I learned, they have successfully assisted many people facing similar situations, returning stolen funds to their rightful owners in a remarkably short time. In my case, the GREAT WHIP RECOVERY CYBER SERVICES were able to recover my funds within just 48 hours, which was truly unbelievable. Even more reassuring was the fact that the scammer was identified, located, and eventually arrested by local authorities in his region. That outcome brought a great sense of relief and closure. I hope this information helps others who have lost their hard-earned money due to misplaced trust. If you’re in a similar situation, you can contact them through their info below to seek help in recovering your stolen funds. Email: [email protected] Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site Phone Call:+1(406)2729101 04.02.26 17:11 wendytaylor015 My name is Wendy Taylor, I'm from Los Angeles, i want to announce to you Viewer how Capital Crypto Recover help me to restore my Lost Bitcoin, I invested with a Crypto broker without proper research to know what I was hoarding my hard-earned money into scammers, i lost access to my crypto wallet or had your funds stolen? Don’t worry Capital Crypto Recover is here to help you recover your cryptocurrency with cutting-edge technical expertise, With years of experience in the crypto world, Capital Crypto Recover employs the best latest tools and ethical hacking techniques to help you recover lost assets, unlock hacked accounts, Whether it’s a forgotten password, Capital Crypto Recover has the expertise to help you get your crypto back. a security company service that has a 100% success rate in the recovery of crypto assets, i lost wallet and hacked accounts. I provided them the information they requested and they began their investigation. To my surprise, Capital Crypto Recover was able to trace and recover my crypto assets successfully within 24hours. Thank you for your service in helping me recover my $647,734 worth of crypto funds and I highly recommend their recovery services, they are reliable and a trusted company to any individuals looking to recover lost money. Contact email [email protected] OR Telegram @Capitalcryptorecover Call/Text Number +1 (336)390-6684 his contact: [email protected] His website: https://recovercapital.wixsite.com/capital-crypto-rec-1 05.02.26 12:07 Thomas Muller YOU CAN REACH OUT TO GREAT WHIP RECOVERY CYBER SERVICES FOR HELP TO RECOVER YOUR STOLEN BTC OR ETH BACK CALL:+1(406)2729101 I once fell victim to online investment scheme that cost me a devastating €254,000. I’m Thomas Muller from Berlin, Germany. The person I trusted turned out to be a fraud, and the moment I realized I’d been deceived, my entire world stopped. I immediately began searching for legitimate ways to recover my funds and hold the scammer accountable. During my search, I came across several testimonies of how Great Whip Recovery Cyber Services helped some people recover money they lost to cyber fraud, I contacted Great Whip Recovery Cyber Service team and provided all the evidence I had. Within about 36 hours, the experts traced the digital trail left by the fraudster, the individual was eventually tracked down and I recovered all my money back. You can contact them with, website https://greatwhiprecoveryc.wixsite.com/greatwhip-site text +1(406)2729101 email [email protected] 05.02.26 15:46 feliciabotezatu Losing access to your cryptocurrency can be devastating—whether you’ve been scammed, hacked, or locked out due to a forgotten password. Many assume their digital assets are gone forever. But with the right expertise, recovery is not only possible—it’s our daily reality. At TECHY FORCE CYBER RETRIEVAL (TFCR), we’re a globally recognized, fully legitimate crypto recovery service dedicated to helping victims reclaim lost or stolen digital assets—safely, ethically, and effectively. Who We Are Backed by a team of certified blockchain forensic analysts, cybersecurity specialists, and ethical hackers, TFCR has recovered millions of dollars in Bitcoin, Ethereum, USDT, and other major cryptocurrencies for clients worldwide. We specialize in cases involving: - Investment scams and fake platforms - Wallet hacks and unauthorized transactions - Forgotten passwords, seed phrases, or corrupted backups - Inaccessible hardware or software wallets Our mission is clear: Help you recover what’s rightfully yours—with honesty, transparency, and proven results. How We Work 1. Confidential Case Review Share your situation with us—no cost, no obligation. We assess whether your case is recoverable based on transaction data, wallet details, and loss type. 2. Advanced Blockchain Forensics Using industry-leading tools, we trace your funds across blockchains, identify destination addresses, and determine if assets are held on exchanges or recoverable platforms—even after complex laundering attempts. 3. Custom Recovery Execution Depending on your case, we: - Reconstruct access to locked wallets using secure decryption methods - Engage with exchanges or payment processors to freeze or retrieve funds - Provide forensic reports to support legal or compliance actions - Negotiate with third parties when appropriate and safe 4. Secure Return & Prevention Advice Recovered assets go directly to a wallet you control. We also offer practical guidance to help you avoid future losses—because security starts after recovery. Why Choose TFCR? No Recovery, No Fee – You only pay upon successful retrieval Legitimate & Transparent – No upfront payments, no hidden costs Global Expertise – Proven success across 50+ countries Ethical Standards – All actions comply with cybersecurity and privacy best practices While crypto threats grow daily, so does our resolve. At TECHY FORCE CYBER RETRIEVAL, we don’t just track transactions—we restore trust, hope, and financial peace of mind. Don’t give up on your crypto. Act now—before critical evidence disappears. 📧 Email: [email protected] 🌐 Visit: Official https://techyforcecyberretrieval.com Website] 🕒 Available 24/7 for urgent cases Your crypto may be missing—but with TFCR, it’s never truly lost. ©️ 2026 TECHY FORCE CYBER RETRIEVAL — Trusted. Professional. Results-Driven. 05.02.26 15:52 harryjones5 How Can I Contact a Cryptocurrency Recovery Company? Visit iFORCE HACKER RECOVERY I realize how volatile and thrilling cryptocurrency can be. After joining a Telegram-based service, I made consistent profits for six months before unexpected faults deprived me of approximately $343,000. Withdrawal blunders, little help, and rising dread kept me stuck. I then discovered iForce Hacker Recovery from positive reviews. They replied swiftly, handled my issue professionally, and walked me through every step. My valuables were returned within a week, giving me back my confidence. I heartily recommend their dependable, professional aid services. Contact Info: Website address: htt p:// iforcehackers. co m. Email: iforcehk @ consultant .co m WhatsApp: +1 240 803-3706 06.02.26 14:44 feliciabotezatu Losing access to your cryptocurrency can be devastating—whether you’ve been scammed, hacked, or locked out due to a forgotten password. Many assume their digital assets are gone forever. But with the right expertise, recovery is not only possible—it’s our daily reality. At TECHY FORCE CYBER RETRIEVAL (TFCR), we’re a globally recognized, fully legitimate crypto recovery service dedicated to helping victims reclaim lost or stolen digital assets—safely, ethically, and effectively. Who We Are Backed by a team of certified blockchain forensic analysts, cybersecurity specialists, and ethical hackers, TFCR has recovered millions of dollars in Bitcoin, Ethereum, USDT, and other major cryptocurrencies for clients worldwide. We specialize in cases involving: - Investment scams and fake platforms - Wallet hacks and unauthorized transactions - Forgotten passwords, seed phrases, or corrupted backups - Inaccessible hardware or software wallets Our mission is clear: Help you recover what’s rightfully yours—with honesty, transparency, and proven results. How We Work 1. Confidential Case Review Share your situation with us—no cost, no obligation. We assess whether your case is recoverable based on transaction data, wallet details, and loss type. 2. Advanced Blockchain Forensics Using industry-leading tools, we trace your funds across blockchains, identify destination addresses, and determine if assets are held on exchanges or recoverable platforms—even after complex laundering attempts. 3. Custom Recovery Execution Depending on your case, we: - Reconstruct access to locked wallets using secure decryption methods - Engage with exchanges or payment processors to freeze or retrieve funds - Provide forensic reports to support legal or compliance actions - Negotiate with third parties when appropriate and safe 4. Secure Return & Prevention Advice Recovered assets go directly to a wallet you control. We also offer practical guidance to help you avoid future losses—because security starts after recovery. Why Choose TFCR? No Recovery, No Fee – You only pay upon successful retrieval Legitimate & Transparent – No upfront payments, no hidden costs Global Expertise – Proven success across 50+ countries Ethical Standards – All actions comply with cybersecurity and privacy best practices While crypto threats grow daily, so does our resolve. At TECHY FORCE CYBER RETRIEVAL, we don’t just track transactions—we restore trust, hope, and financial peace of mind. Don’t give up on your crypto. Act now—before critical evidence disappears. Email: [email protected] Visit: Official https://techyforcecyberretrieval.com Website] Available 24/7 for urgent cases Your crypto may be missing—but with TFCR, it’s never truly lost. ©️ 2026 TECHY FORCE CYBER RETRIEVAL — Trusted. Professional. Results-Driven. 07.02.26 00:44 marcushenderson624 Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 07.02.26 00:44 marcushenderson624 Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 07.02.26 04:43 Matt Kegan Reach out to SolidBlock Forensics if you want to get back your coins from fake crypto investment or your wallet was compromised and all your coins gone. SolidBlock Forensics provide deep ethical analysis and investigation that enables them to trace these schemes, and recover all your funds. Their services are professional and reliable. http://www.solidblockforensics.com 07.02.26 17:31 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 10.02.26 23:52 frankqq It is a pleasure to write this review. Since I began working with Marie in early 2018, the service has been outstanding. My coins were stolen by hackers, and I was afraid I wouldn't be able to recover them. It was a nightmare for me because I didn't know where to start. But after my friend told me about [email protected] and whatsapp:+1 7127594675, things became simple for me. I'm glad she was able to get my bitcoin back so I could start trading again. 11.02.26 05:50 patricialovick86 How To Recover Your Bitcoin Without Falling Victim To Scams: A Testimony Experience With Capital Crypto Recover Services, Contact Telegram: @Capitalcryptorecover Dear Everyone, I would like to take a moment to share my positive experience with Capital Crypto Recover Services. Initially, I was unsure if it would be possible to recover my stolen bitcoins. However, with their expertise and professionalism, I was able to fully recover my funds. Unfortunately, many individuals fall victim to scams in the cryptocurrency space, especially those involving fraudulent investment platforms. However, I advise caution, as not all recovery services are legitimate. I personally lost $273,000 worth of Bitcoin from my Binance account due to a deceptive platform. If you have suffered a similar loss, you may be considering crypto recovery, The Capital Crypto Recover is the most knowledgeable and effective Capital Crypto Recovery Services assisted me in recovering my stolen funds within 24 hours, after getting access to my wallet. Their service was not only prompt but also highly professional and effective, and many recovery services may not be trustworthy. Therefore, I highly recommend Capital Crypto Recover to you. i do always research and see reviews about their service, For assistance finding your misplaced cryptocurrency, get in touch with them, They do their jobs quickly and excellently, Stay safe and vigilant in the crypto world. Contact: [email protected] You can reach them via email at [email protected] OR Call/Text Number +1 (336)390-6684 his contact website: https://recovercapital.wixsite.com/capital-crypto-rec-1 11.02.26 05:50 patricialovick86 How To Recover Your Bitcoin Without Falling Victim To Scams: A Testimony Experience With Capital Crypto Recover Services, Contact Telegram: @Capitalcryptorecover Dear Everyone, I would like to take a moment to share my positive experience with Capital Crypto Recover Services. Initially, I was unsure if it would be possible to recover my stolen bitcoins. However, with their expertise and professionalism, I was able to fully recover my funds. Unfortunately, many individuals fall victim to scams in the cryptocurrency space, especially those involving fraudulent investment platforms. However, I advise caution, as not all recovery services are legitimate. I personally lost $273,000 worth of Bitcoin from my Binance account due to a deceptive platform. If you have suffered a similar loss, you may be considering crypto recovery, The Capital Crypto Recover is the most knowledgeable and effective Capital Crypto Recovery Services assisted me in recovering my stolen funds within 24 hours, after getting access to my wallet. Their service was not only prompt but also highly professional and effective, and many recovery services may not be trustworthy. Therefore, I highly recommend Capital Crypto Recover to you. i do always research and see reviews about their service, For assistance finding your misplaced cryptocurrency, get in touch with them, They do their jobs quickly and excellently, Stay safe and vigilant in the crypto world. Contact: [email protected] You can reach them via email at [email protected] OR Call/Text Number +1 (336)390-6684 his contact website: https://recovercapital.wixsite.com/capital-crypto-rec-1 12.02.26 23:55 brouwerspatrick8 I’ve always believed that sustainability begins at home—not just in how we recycle or conserve energy, but in the very structures we live in. For years, I dreamed of building a zero-waste neighborhood where every house functions like a living ecosystem: solar-powered, water-wise, and crowned with rooftop greenhouses that feed families and filter air. It wasn’t just architecture—it was my vision for a quieter, cleaner future. To make it real, I turned to Bitcoin. Not as a speculative bet, but as a long-term store of value aligned with my values—decentralized, transparent, and independent of broken systems. Over seven years, I poured savings, side income, and relentless discipline into building a $680,000 crypto portfolio. Every coin had a purpose: permits, materials, and community partnerships. My dream had a balance sheet. Then, in one exhausted, distracted moment, it all collapsed. It was November 2025. I was juggling contractor delays, city inspections, and endless design revisions. My nerves were frayed, my coffee pot never empty. When a “Ledger Live Update” notification popped up, I didn’t think twice. The interface looked identical—same logo, same layout. I entered my credentials… and within seconds, the app disappeared. My wallet balance dropped to zero. I sat frozen. My stomach dropped. All that work—years of sacrifice—gone in a blink. The days that followed were dark. I scoured forums, filed reports, and replayed my mistake on loop. Guilt ate at me. How could I have been so careless? My greenhouse renderings sat untouched. My dream felt like a cruel joke. Just when I was ready to walk away, I stumbled upon a newsletter about green innovation. Tucked between articles on carbon-neutral cities and next-gen solar panels was a short feature on *Digital Light Solution*—a specialized team that helps victims of crypto theft recover stolen assets. Skeptical but desperate, I reached out. What followed wasn’t magic—but it was close to it. Their team treated my case with urgency and compassion. They traced the transaction trail, identified the laundering path, and worked with exchanges to freeze what they could. Within weeks, they’d recovered a significant portion of my funds—enough to restart. Today, I’m not just rebuilding my portfolio—I’m breaking ground on my prototype greenhouse. And every beam, every pane of glass, carries the lesson I learned: that even in our most vulnerable moments, there’s still light to be found. [email protected] Telegram ——digitallightsolution website https://digitallightsolution.com/ WHAT'S APP https://wa.link/989vlf 12.02.26 23:56 brouwerspatrick8 I’ve always believed that sustainability begins at home—not just in how we recycle or conserve energy, but in the very structures we live in. For years, I dreamed of building a zero-waste neighborhood where every house functions like a living ecosystem: solar-powered, water-wise, and crowned with rooftop greenhouses that feed families and filter air. It wasn’t just architecture—it was my vision for a quieter, cleaner future. To make it real, I turned to Bitcoin. Not as a speculative bet, but as a long-term store of value aligned with my values—decentralized, transparent, and independent of broken systems. Over seven years, I poured savings, side income, and relentless discipline into building a $680,000 crypto portfolio. Every coin had a purpose: permits, materials, and community partnerships. My dream had a balance sheet. Then, in one exhausted, distracted moment, it all collapsed. It was November 2025. I was juggling contractor delays, city inspections, and endless design revisions. My nerves were frayed, my coffee pot never empty. When a “Ledger Live Update” notification popped up, I didn’t think twice. The interface looked identical—same logo, same layout. I entered my credentials… and within seconds, the app disappeared. My wallet balance dropped to zero. I sat frozen. My stomach dropped. All that work—years of sacrifice—gone in a blink. The days that followed were dark. I scoured forums, filed reports, and replayed my mistake on loop. Guilt ate at me. How could I have been so careless? My greenhouse renderings sat untouched. My dream felt like a cruel joke. Just when I was ready to walk away, I stumbled upon a newsletter about green innovation. Tucked between articles on carbon-neutral cities and next-gen solar panels was a short feature on *Digital Light Solution*—a specialized team that helps victims of crypto theft recover stolen assets. Skeptical but desperate, I reached out. What followed wasn’t magic—but it was close to it. Their team treated my case with urgency and compassion. They traced the transaction trail, identified the laundering path, and worked with exchanges to freeze what they could. Within weeks, they’d recovered a significant portion of my funds—enough to restart. Today, I’m not just rebuilding my portfolio—I’m breaking ground on my prototype greenhouse. And every beam, every pane of glass, carries the lesson I learned: that even in our most vulnerable moments, there’s still light to be found. [email protected] Telegram ——digitallightsolution website https://digitallightsolution.com/ WHAT'S APP https://wa.link/989vlf 13.02.26 00:17 marcushenderson624 Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 13.02.26 00:17 marcushenderson624 Bitcoin Recovery Testimonial After falling victim to a cryptocurrency scam group, I lost $354,000 worth of USDT. I thought all hope was lost from the experience of losing my hard-earned money to scammers. I was devastated and believed there was no way to recover my funds. Fortunately, I started searching for help to recover my stolen funds and I came across a lot of testimonials online about Capital Crypto Recovery, an agent who helps in recovery of lost bitcoin funds, I contacted Capital Crypto Recover Service, and with their expertise, they successfully traced and recovered my stolen assets. Their team was professional, kept me updated throughout the process, and demonstrated a deep understanding of blockchain transactions and recovery protocols. They are trusted and very reliable with a 100% successful rate record Recovery bitcoin, I’m grateful for their help and highly recommend their services to anyone seeking assistance with lost crypto. Contact: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Email: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 13.02.26 02:16 Ralf Boruta GREAT WHIP RECOVERY CYBER SERVICES TRUSTED EXPERTS IN ONLINE RECOVERY SOLUTIONS PHONE CALL:+1(406)2729101 I was unfortunately deceived and scammed out of $88,000 by someone I trusted to manage my funds during a transaction we carried out together. The experience left me deeply disappointed and hurt, realizing that someone could betray that level of trust without any remorse. Determined to seek justice and recover what was stolen, I began searching for legal assistance and came across numerous testimonials about GREAT WHIP RECOVERY CYBER SERVICES, a group known for helping victims recover lost funds. From what I learned, they have successfully assisted many people facing similar situations, returning stolen funds to their rightful owners in a remarkably short time. In my case, the GREAT WHIP RECOVERY CYBER SERVICES were able to recover my funds within just 48 hours, which was truly unbelievable. Even more reassuring was the fact that the scammer was identified, located, and eventually arrested by local authorities in his region. That outcome brought a great sense of relief and closure. I hope this information helps others who have lost their hard-earned money due to misplaced trust. If you’re in a similar situation, you can contact them through their info below to seek help in recovering your stolen funds. Email: [email protected] Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site Phone Call:+1(406)2729101 13.02.26 02:16 Ralf Boruta GREAT WHIP RECOVERY CYBER SERVICES TRUSTED EXPERTS IN ONLINE RECOVERY SOLUTIONS PHONE CALL:+1(406)2729101 I was unfortunately deceived and scammed out of $88,000 by someone I trusted to manage my funds during a transaction we carried out together. The experience left me deeply disappointed and hurt, realizing that someone could betray that level of trust without any remorse. Determined to seek justice and recover what was stolen, I began searching for legal assistance and came across numerous testimonials about GREAT WHIP RECOVERY CYBER SERVICES, a group known for helping victims recover lost funds. From what I learned, they have successfully assisted many people facing similar situations, returning stolen funds to their rightful owners in a remarkably short time. In my case, the GREAT WHIP RECOVERY CYBER SERVICES were able to recover my funds within just 48 hours, which was truly unbelievable. Even more reassuring was the fact that the scammer was identified, located, and eventually arrested by local authorities in his region. That outcome brought a great sense of relief and closure. I hope this information helps others who have lost their hard-earned money due to misplaced trust. If you’re in a similar situation, you can contact them through their info below to seek help in recovering your stolen funds. Email: [email protected] Website https://greatwhiprecoveryc.wixsite.com/greatwhip-site Phone Call:+1(406)2729101 13.02.26 18:29 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 13.02.26 18:29 robertalfred175 CRYPTO SCAM RECOVERY SUCCESSFUL – A TESTIMONIAL OF LOST PASSWORD TO YOUR DIGITAL WALLET BACK. My name is Robert Alfred, Am from Australia. I’m sharing my experience in the hope that it helps others who have been victims of crypto scams. A few months ago, I fell victim to a fraudulent crypto investment scheme linked to a broker company. I had invested heavily during a time when Bitcoin prices were rising, thinking it was a good opportunity. Unfortunately, I was scammed out of $120,000 AUD and the broker denied me access to my digital wallet and assets. It was a devastating experience that caused many sleepless nights. Crypto scams are increasingly common and often involve fake trading platforms, phishing attacks, and misleading investment opportunities. In my desperation, a friend from the crypto community recommended Capital Crypto Recovery Service, known for helping victims recover lost or stolen funds. After doing some research and reading multiple positive reviews, I reached out to Capital Crypto Recovery. I provided all the necessary information—wallet addresses, transaction history, and communication logs. Their expert team responded immediately and began investigating. Using advanced blockchain tracking techniques, they were able to trace the stolen Dogecoin, identify the scammer’s wallet, and coordinate with relevant authorities to freeze the funds before they could be moved. Incredibly, within 24 hours, Capital Crypto Recovery successfully recovered the majority of my stolen crypto assets. I was beyond relieved and truly grateful. Their professionalism, transparency, and constant communication throughout the process gave me hope during a very difficult time. If you’ve been a victim of a crypto scam, I highly recommend them with full confidence contacting: 📧 Email: [email protected] 📱 Telegram: @Capitalcryptorecover Contact: [email protected] 📞 Call/Text: +1 (336) 390-6684 🌐 Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 17.02.26 23:59 Lilyfox These group of CYBER GURUS below helped my family in recovering stolen bitcoin by scammers and they also helped me in securing a university title in one of the best university in the world I'm saying a very big thank you to them contact them now ; [email protected] or WhatsApp +447476606228 -Recovery of funds from fake platform/BINARY TRADING - Retrieval of fraudulent funds - Bank Transfer service - BITCOIN TOP UP - Money, recovery from any country in the world - Change of university degrees - Spying of all social media account within - Sales of Blank ATM and Credit Cards - Sales of university Titles originals. - Clearing of bank debts - University title offer and so many others ... Despite all odds these internet gurus have proven themselves worthy to be called a professional Cyber genius ... once again i beat up my chest to confess that these group of cyber gurus are reliable and satisfactory with 100% reliability..... 18.02.26 00:01 Lilyfox GENERAL HACKING AND CRYPTO RECOVERY SERVICES These group of CYBER GURUS below helped my family in recovering stolen bitcoin worth of $168,000 USD by scammers and they also helped me in securing a university title in one of the best university in the world I'm saying a very big thank you to them contact them now ; [email protected] or WhatsApp +447476606228 -Recovery of funds from fake platform/BINARY TRADING - Retrieval of fraudulent funds - Bank Transfer service - BITCOIN TOP UP - Money, recovery from any country in the world - Change of university degrees - Spying of all social media account within - Sales of Blank ATM and Credit Cards - Sales of university Titles originals. - Clearing of bank debts - University title offer and so many others ... Despite all odds these internet gurus have proven themselves worthy to be called a professional Cyber genius ... once again i beat up my chest to confess that these group of cyber gurus are reliable and satisfactory with 100% reliability..... 18.02.26 03:23 walterlindahi9 This past January, my world came crashing down. I lost nearly $42,000 of my hard-earned savings to a sophisticated Solana-based crypto scam. At first, it all seemed legitimate: sleek website, professional whitepaper, even glowing testimonials from “investors.” I’d done my homework, or so I thought. The promise of high returns in a volatile market felt like my ticket to financial freedom. For the first few months, everything appeared to be working. My portfolio showed steady gains. I remember checking my wallet balance daily, feeling a mix of pride and relief. I’ve cracked the code to building real wealth. Then, without warning, the platform vanished. Wallet addresses went dead. Support channels disappeared, and my funds were gone in an instant. The emotional fallout was worse than the financial loss. Sleepless nights became the norm. Anxiety gnawed at me constantly. I replayed every decision in my head, blaming myself for being naive. I vowed never to trust anyone again, not influencers, not experts, not even my own judgment. But giving up wasn’t an option. I owed it to myself and to my future to fight back. So I began digging. I scoured Reddit threads, filed reports with blockchain analytics firms, and even contacted local authorities (though they offered little help). The more I searched, the more overwhelmed I became, lost in a labyrinth of technical jargon, dead ends, and predatory recovery services asking for upfront fees. Then, through a survivor’s forum, I stumbled upon TechY Force Cyber Retrieval. Skeptical but desperate, I reached out. What set them apart wasn’t just their expertise; it was their empathy. They didn’t make wild promises. Instead, they walked me through how crypto tracing works, what success looks like, and what realistic timelines are. No pressure. No false hope. Within weeks, their forensic team identified transaction trails linked to the scam wallet. Using on-chain analysis and coordination with exchanges, they flagged suspicious activity and initiated recovery protocols. It wasn’t magic, but it was methodical, transparent, and grounded in real blockchain intelligence. Today, I’m cautiously optimistic. While not all funds have been recovered yet, TechY Force has already secured a significant portion and, more importantly, restored my sense of agency. I’m sleeping again. I’m healing. If you’ve been scammed, know this: you’re not alone, and you’re not foolish. Crypto fraud preys on hope, but that same hope can fuel your comeback. Don’t suffer in silence. Reach out. Ask questions. And never let a scammer steal your future along with your funds. WhatsApp +1(561) 726 3697 Mail. Techyforcecyberretrieval(@)consultant(.)com Telegram (@)TechCyberforc 22.02.26 03:48 harristhomas7376 "In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 22.02.26 03:49 harristhomas7376 "In the crypto world, this is great news I want to share. Last year, I fell victim to a scam disguised as a safe investment option. I have invested in crypto trading platforms for about 10yrs thinking I was ensuring myself a retirement income, only to find that all my assets were either frozen, I believed my assets were secure — until I discovered that my BTC funds had been frozen and withdrawals were impossible. It was a devastating moment when I realized I had been scammed, and I thought my Bitcoin was gone forever, Everything changed when a close friend recommended the Capital Crypto Recover Service. Their professionalism, expertise, and dedication enabled me to recover my lost Bitcoin funds back — more than €560.000 DEM to my BTC wallet. What once felt impossible became a reality thanks to their support. If you have lost Bitcoin through scams, hacking, failed withdrawals, or similar challenges, don’t lose hope. I strongly recommend Capital Crypto Recover Service to anyone seeking a reliable and effective solution for recovering any wallet assets. They have a proven track record of successful reputation in recovering lost password assets for their clients and can help you navigate the process of recovering your funds. Don’t let scammers get away with your hard-earned money – contact Email: [email protected] Phone CALL/Text Number: +1 (336) 390-6684 Contact: [email protected] Website: https://recovercapital.wixsite.com/capital-crypto-rec-1 22.02.26 18:58 Natasha Williams I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101 22.02.26 19:00 Natasha Williams I am Natasha Williams from Dallas. I want to share my testimony to encourage anyone who has ever fallen victim to a scam or fraud. Some time ago, I was defrauded by some fraudulent cryptocurrency investment organization online, I was a victim and I lost a huge amount of money, $382,000. I felt angry, disappointed and helpless but I refused to give up and stay calm. I came across this agency, GREAT WHIP RECOVERY CYBER SERVICES.. who helped people recover their money from scammers and the testimonies I saw were quite amazing. And I decided to contact them. I gathered every piece of evidence, chats, receipts, account details, and messages and reported the case to the agency, GREAT WHIP RECOVERY CYBER SERVICES. After 73hours of follow up and not losing faith, the fraudster was traced and held accountable and I recovered all my money back. I highly recommend, GREAT WHIP RECOVERY CYBER SERVICES agency if you have ever fallen victim to scammers, you can contact them. Website: https://greatwhiprecoveryc.wixsite.com/greatwhip-site email: [email protected] Call Line: +1(406)2729101 23.02.26 23:26 chongfook As cryptocurrencies continue to reshape global finance in 2026, the risks have never been higher. From sophisticated phishing campaigns to fake wallet apps and investment scams, millions of investors face the devastating reality of lost or stolen digital assets. When your crypto vanishes, panic sets in—and that's when fraudsters strike again, posing as "recovery experts" to exploit your vulnerability. CONTACTS US Techyforcecyberretrieval(@)consultant(.)com https(://)techyforcecyberretrieval(.)com But there's a legitimate path forward. TECHY FORCE CYBER RETRIEVAL stands as the industry's most trusted crypto recovery company, combining advanced blockchain forensics, global partnerships, and a client-centric approach to help victims reclaim what was stolen. --- Why Recovery Is Possible—With the Right Team Cryptocurrency's decentralized, pseudonymous nature makes asset recovery complex—but not impossible. The blockchain is transparent. Every transaction leaves a trail. The challenge isn't finding the funds—it's having the expertise to follow that trail through mixers, bridges, and exchange deposits before they disappear forever. That's where TECHY FORCE CYBER RETRIEVAL excels. --- Our Proven Recovery Framework We don't believe in shortcuts, false promises, or upfront fees. Our process is built on transparency, forensic precision, and real results. Here's how we work: 1. Case Intake & Initial Assessment You begin by submitting a detailed report: compromised wallet addresses, transaction IDs, timestamps, and any communication with scammers. Our intake team reviews your case within hours to determine immediate next steps. 2. Blockchain Forensic Analysis Our specialists deploy proprietary tracking tools to map the movement of your stolen assets across multiple blockchains. We identify laundering patterns, exchange deposit addresses, and potential freezing points—building a clear investigative roadmap. 3. Global Partner Coordination Through established relationships with regulated exchanges, DeFi protocols, and compliance teams worldwide, we initiate direct communication to flag suspicious transactions and request asset freezes where legally permissible. 4. Legal & Regulatory Engagement When necessary, we collaborate with legal partners and law enforcement agencies to strengthen recovery efforts—especially in cases involving large-scale hacks or organized fraud rings. 5. Recovery Execution & Fund Return Once assets are secured, they're transferred directly to a new, secure wallet of your choice. We never hold your funds. And critically, we operate on a success-only model. You pay nothing unless we recover your assets. 6. Post-Recovery Security Guidance Recovery is only half the battle. We provide personalized recommendations to secure your remaining holdings—from hardware wallet setup to phishing awareness training—so you can move forward with confidence. --- What Sets TECHY FORCE CYBER RETRIEVAL Apart While countless "recovery services" flood the internet, few deliver legitimate results. Here's why we're consistently rated the best crypto recovery company in 2026: - Zero Upfront Fees – We only succeed when you do. No hidden charges. No bait-and-switch tactics. - Advanced Blockchain Intelligence – Our forensic tools track assets across Bitcoin, Ethereum, Solana, and 50+ other networks. - Global Reach – Partnerships with exchanges and regulatory bodies in North America, Europe, and Asia maximize recovery odds. - Client-First Communication – Weekly updates. Clear timelines. No ghosting. - Proven Track Record – Hundreds of successful recoveries in 2025–2026, with millions returned to rightful owners. --- Emerging Trends in 2026: What Victims Need to Know The threat landscape evolves constantly. This year's biggest risks include: - AI-Powered Phishing: Scammers now use deepfake voice and video to impersonate support staff. - Cross-Chain Bridge Exploits: Funds moved between networks are increasingly targeted. - Fake Recovery Services: Fraudsters pose as legitimate firms—always verify credentials before sharing information. TECHY FORCE CYBER RETRIEVAL stays ahead of these threats, continuously updating our tools and strategies to protect and serve our clients. CONTACTS US Techyforcecyberretrieval(@)consultant(.)com https(://)techyforcecyberretrieval(.)com --- Your Next Step If you've lost crypto to a scam, hack, or forgotten credentials, don't let despair—or another fraudster—steal your second chance. TECHY FORCE CYBER RETRIEVAL is accessible, transparent, and ready to help. Reach out today. Let our experts assess your case—and show you that even in 2026, stolen crypto doesn't have to stay lost forever. — TECHY FORCE CYBER RETRIEVAL Advanced Forensics. Global Reach. Your Recovery. 24.02.26 15:31 [email protected]` Like many others, I was drawn in by the allure of cryptocurrency and the promise of financial freedom. When I encountered a self-proclaimed "crypto guru" online, his confidence and flashy lifestyle convinced me that he held the key to success. Eager to learn, I parted with $15,000 for his exclusive course, believing it would grant me access to an elite trading group and lucrative market insights. Initially, my excitement was palpable; I truly thought I was on the verge of a breakthrough. However, that enthusiasm quickly curdled into dread. Once inside the group, the dynamic shifted from education to aggressive exploitation. Instead of genuine mentorship, members were relentlessly upsold on fake trading signals that yielded nothing but losses. The pressure escalated when we were encouraged to invest in a supposed "private pool," which required an additional, staggering access fee of $60,000. It was only as I began to notice glaring inconsistencies and a complete lack of real results among the members that the fog lifted. I realized I hadn't joined a community of traders; I had walked into a sophisticated trap designed specifically to prey on newcomers like myself. The realization that the promises of wealth and insider knowledge were nothing more than a façade left me feeling vulnerable, deceived, and financially devastated. The dream of easy returns had turned into a heavy burden of regret. Desperate for a solution and refusing to let the fraudsters win, I began searching for help. That is when I discovered DIGITAL LIGHT SOLUTION, a firm specializing in online fraud investigations. Reaching out to them was the turning point. Their team approached my case with professionalism and empathy, immediately understanding the complexity of the scam. They guided me through the investigation process, uncovering the layers of deception used by the "guru" and his network. Thanks to their expertise and relentless pursuit of justice, I was able to navigate the aftermath of this ordeal with clarity rather than confusion. While the experience was a harsh lesson, connecting with DIGITAL LIGHT SOLUTION restored my hope and proved that there are still allies ready to fight against online exploitation. If you find yourself in a similar situation, do not lose hope—seek professional help immediately. Contact them directly Website https://digitallightsolution.com/ Email — Digitallightsolution(At)qualityservice(DOT)com What's App — https://wa.link/989vlf 24.02.26 15:32 [email protected]` Like many others, I was drawn in by the allure of cryptocurrency and the promise of financial freedom. When I encountered a self-proclaimed "crypto guru" online, his confidence and flashy lifestyle convinced me that he held the key to success. Eager to learn, I parted with $15,000 for his exclusive course, believing it would grant me access to an elite trading group and lucrative market insights. Initially, my excitement was palpable; I truly thought I was on the verge of a breakthrough. However, that enthusiasm quickly curdled into dread. Once inside the group, the dynamic shifted from education to aggressive exploitation. Instead of genuine mentorship, members were relentlessly upsold on fake trading signals that yielded nothing but losses. The pressure escalated when we were encouraged to invest in a supposed "private pool," which required an additional, staggering access fee of $60,000. It was only as I began to notice glaring inconsistencies and a complete lack of real results among the members that the fog lifted. I realized I hadn't joined a community of traders; I had walked into a sophisticated trap designed specifically to prey on newcomers like myself. The realization that the promises of wealth and insider knowledge were nothing more than a façade left me feeling vulnerable, deceived, and financially devastated. The dream of easy returns had turned into a heavy burden of regret. Desperate for a solution and refusing to let the fraudsters win, I began searching for help. That is when I discovered DIGITAL LIGHT SOLUTION, a firm specializing in online fraud investigations. Reaching out to them was the turning point. Their team approached my case with professionalism and empathy, immediately understanding the complexity of the scam. They guided me through the investigation process, uncovering the layers of deception used by the "guru" and his network. Thanks to their expertise and relentless pursuit of justice, I was able to navigate the aftermath of this ordeal with clarity rather than confusion. While the experience was a harsh lesson, connecting with DIGITAL LIGHT SOLUTION restored my hope and proved that there are still allies ready to fight against online exploitation. If you find yourself in a similar situation, do not lose hope—seek professional help immediately. Contact them directly Website https://digitallightsolution.com/ Email — Digitallightsolution(At)qualityservice(DOT)com What's App — https://wa.link/989vlf 232000Подписчиков 2005Видео 192860Members 21362Твита 3765Posts 9103Followers Копирование и распространение материалов с сайта pro-blockchain.com разрешено только с указанием активной ссылки на pro-blockchain.com Bitcoin - 18SAjcMDc5qAeQJBRv1dUAUKK3x6apcxej Ethereum - 0xF0dA58B9504A542220f085D438e3D827e5039c23 Copyright © 2026 pro-blockchain.com . All rights reserved. fy2nm3YtN
Images (10): 

|
|||||
| Tesla Optimus: реальность против обещаний / Хабр | https://habr.com/ru/companies/bothub/ar… | 1 | Feb 26, 2026 08:00 | active | |
Tesla Optimus: реальность против обещаний / ХабрURL: https://habr.com/ru/companies/bothub/articles/995618/ Description: Заявления Илона Маска о роботе Tesla Optimus поражают своей масштабностью. Он утверждал, что Optimus принесёт $10 триллионов долгосрочной прибыли для Tesla , что в конечном итоге робот составит 80%... Content:
Заявления Илона Маска о роботе Tesla Optimus поражают своей масштабностью. Он утверждал, что Optimus принесёт $10 триллионов долгосрочной прибыли для Tesla, что в конечном итоге робот составит 80% стоимости Tesla, и что он увеличит оценку компании до впечатляющих $25 триллионов. Однако предыдущие обещания не всегда сбывались: Маск говорил, что Tesla запустит пилотную производственную линию готового Optimus и произведёт 5000 единиц к концу 2025 года, но этого не произошло. Фактически, Tesla недавно анонсировала новую «готовую к производству» третью версию Optimus (что подразумевает, что версия, запланированная к производству в 2025 году, так и не была готова), и что к концу 2027 года производство начнётся на заводе Tesla во Фримонте, где ранее производились Model S и X. Возможно, стоит воспринимать эти громкие заявления с определённой долей скептицизма? Во время недавних отчётных звонков Tesla Маск упомянул нечто, что не только демонстрирует разрыв между реальностью и обещаниями, но и ставит вопросы о понимании технологии. На протяжении месяцев Tesla утверждала, что два робота Optimus работают на их заводах. Это было единственным свидетельством того, что Optimus может быть способен выполнять даже самые базовые задачи автономно. Важно понимать — вся концепция Optimus строится на убеждении инвесторов в том, что это нечто большее, чем просто телеуправляемый робот-аниматроник. Однако, похоже, информация была представлена не полностью. Во время недавнего отчётного звонка выяснилось, что ни один робот Optimus в настоящее время не выполняет продуктивную работу ни на одном из заводов Tesla. Маск заявил, что присутствие Optimus на заводе было «скорее для того, чтобы робот мог учиться», и он никак не помогал в производстве. Иными словами: робот, производство которого планировалось начать в прошлом году, даже не способен помогать на собственных заводах Tesla. Даже в простейших задачах? Он не может, скажем, поднять коробку с болтами и переместить её? Что ещё важнее, почему роботы проходят «обучение» на заводе в первую очередь? Об этом чуть позже. Если вас удивило это открытие, стоило следить внимательнее. Tesla отчаянно пыталась создать иллюзию автономности Optimus, но неоднократно терпела неудачу. Вспомните инцидент на мероприятии в Майами, где Tesla пыталась намекнуть, что роботы Optimus, раздающие бутылки с водой, делают это автономно, пока один из роботов не снял несуществующую гарнитуру, разрушив иллюзию (посмотрите видео здесь). Это ясно показало, что робот управлялся дистанционно. Хотя Tesla прямо не признала это, компания подтвердила, что демонстрационное видео Optimus, складывающего одежду с VR-оператором в кадре, и роботы на мероприятии We Are Robot действительно управлялись дистанционно. До сих пор Optimus не оправдал ожиданий как технологическая демонстрация, поэтому неудивительно, что Tesla не может заставить его помогать на своих заводах. Но последствия этого открытия гораздо глубже, чем может показаться. Для Tesla неудобно, что гуманоидные роботы уже работают на заводах по производству электромобилей. Как я недавно писал (подробнее здесь), BYD в настоящее время тестирует Walker S1 от UBTech на своих заводах, где он выполняет такие задачи, как базовый контроль качества, транспортировка компонентов по заводу и даже установка деталей. Это не должно сильно удивлять, поскольку UBTech продемонстрировал, как Walker S1 выполняет удивительно сложные задачи, такие как игра в теннис и успешное взаимодействие с оборудованием производственной линии. Он явно способен на такие испытания. Хотя, справедливости ради, он выполняет эти задачи не идеально. Как сообщила Financial Times, главный директор по бренду UBTech Майкл Там заявил, что Walker S1 «на 30-50 процентов производительнее людей и только в определённых задачах, таких как укладка коробок и контроль качества». Таким образом, он, скорее всего, всё ещё находится на стадии «технологической демонстрации», и китайским рабочим на заводах пока не о чем беспокоиться. Walker S1 явно более способен, чем Optimus, но даже он пока не может обосновать бизнес-кейс, близкий к заявлениям Маска об Optimus. Это также показывает, что Tesla на самом деле не является лидером рынка и функционально не имеет преимущества перед конкурентами. Так что, даже если гуманоидные роботы представляют собой многотриллионную возможность, компании вроде UBTech, а не Tesla, получат прибыль. Но гуманоидные роботы, вероятно, даже не являются жизнеспособной технологией, не говоря уже о революционной бизнес-возможности. На самом деле, мы давно знаем, что гуманоидные роботы имеют смысл только в научной фантастике. В реальности существует крайне мало случаев, когда гуманоидный робот имеет больше смысла, чем специализированный. Возьмём Walker S1. Простые, недорогие, специализированные роботы могут — и уже делают это — устанавливать детали, транспортировать компоненты по заводам и выполнять базовые проверки качества гораздо быстрее, точнее и экономичнее, чем когда-либо сможет гуманоидный робот. Кроме того, они дешевле и быстрее интегрируются в производственную линию в подавляющем большинстве случаев. Действительно, робототехническая индустрия довольно давно знает, что гуманоидные роботы — не оптимальное направление. Возьмём Криса Уолти, который фактически возглавлял разработку Optimus в Tesla. Он публично заявил, что гуманоидный форм-фактор «не является полезным форм-фактором» и что «мы не созданы для выполнения повторяющихся задач снова и снова. Так зачем брать гиперсубоптимальную систему, которая на самом деле не предназначена для повторяющихся задач, и заставлять её делать повторяющиеся задачи?» Или Брэда Портера, бывшего вице-президента по робототехнике в Amazon, который сказал, что «гуманоиды — неправильное решение для большинства задач» и что гораздо более простые решения, такие как колёса вместо двуногих ног, почти всегда дешевле и надёжнее. Затем есть Gartner, которая указывает, что гуманоидные роботы непригодны из-за их высокой стоимости, проблем с интеграцией, ненадёжности и недостаточных возможностей. Учитывая доступность лучших вариантов, таких как специализированные роботы или человеческие работники, так будет ещё долго. Если подумать, эта настойчивость имитировать человека имеет мало смысла. Если бы люди эволюционировали тысячелетиями для работы на автомобильном заводе, они бы не выглядели как мы. Точно так же, зачем тратить средства и усилия на то, чтобы заставить гуманоидного робота пылесосить, когда можно просто поручить это Roomba, который справится гораздо лучше? Настаивать на том, чтобы роботы выглядели и функционировали как люди — всё равно что проектировать автомобиль, напоминающий лошадь и работающий как лошадь. Это обратная логика. Конечно, нам нравится идея гуманоидных роботов, потому что мы можем их антропоморфизировать, но фактически использовать их, даже если они способны выполнять задачу, не имеет смысла. Помните тот момент, о котором я просил помнить? Тот факт, что Optimus «обучается» на заводе? Это своего рода индикатор проблем Optimus. Tesla использует два основных метода для «обучения» ИИ Optimus: обучение подражанием на основе видео и обучение через телеоперирование. Это потому, что Optimus основан на тех же ИИ и компьютерах ИИ, что и FSD Tesla, именно так они обучают ИИ FSD. И мы все знаем, как это идёт, не так ли? Но, как указал блестящий австралийский специалист по робототехнике Родни Брукс, эти методы обучения имеют серьёзные и очевидные недостатки. Начнём с обучения подражанием на основе видео. Это процесс «обучения» ИИ выполнению задач, которые вы хотите, чтобы робот выполнял, путём показа ИИ видео людей, выполняющих такие задачи. Брукс называет этот подход «чистым фантазированием». Почему? Потому что мы, люди, используем гораздо больше, чем просто визуальные данные для выполнения этих задач. Наше чувство осязания невероятно мощное. Наши руки имеют 17 000 специализированных, высокочувствительных тактильных рецепторов, способных обнаруживать изменения размером до 40 мкм со скоростью примерно один миллиард бит в секунду. Другими словами, одна человеческая рука передаёт нашему мозгу более двух гигабайт невероятно детальных данных каждую секунду! Мы полагаемся на это значительно больше, чем на визуальные данные, для выполнения даже самых базовых задач. Подумайте так: вы можете сложить рубашку с завязанными глазами довольно легко, но вам будет очень трудно сложить её, используя щипцы вместо рук. Брукс указывает, что обучение подражанием на основе видео обучает ИИ на неполных данных, оставляя у него огромное слепое пятно, что означает, что он не может эффективно воспроизвести человека из обучающих данных. Решение Маска для этой проблемы выравнивания данных, похоже, заключается в обучении через телеоперирование. Это когда вы используете VR для управления роботом для выполнения задачи и используете это как обучающие данные для ИИ. Таким образом, собранные данные теоретически лучше соответствуют тому, к чему имеет доступ ИИ, обеспечивая лучшее обучение. Но Брукс указывает на серьёзные недостатки и этого подхода. ИИ может работать только так же хорошо, как эти телеоператоры (или, что более реалистично, не так хорошо, как телеоператоры), и эти телеоператоры действительно с трудом выполняют даже базовые задачи при управлении роботом. VR-костюмы, которые используют эти телеоператоры, имеют очень ограниченный контроль пальцев и ещё меньше силовой обратной связи, серьёзно ограничивая чувство осязания телеоператора. Размеры робота могут отличаться от размеров телеоператора, нарушая их погружение. Восприятие глубины телеоператора может быть неточным из-за того, что две камеры, используемые для восприятия мира с восприятием глубины и для предоставления VR-видеоизображения, имеют разное межзрачковое расстояние. Чувство равновесия телеоператора и проприоцепция (ощущение того, где находятся ваши конечности в пространстве) постоянно отличаются от робота. Всё это означает, что этим телеоператорам действительно сложно телеоперировать гуманоидными роботами, поскольку данные, которые им передаются, часто сбивают с толку, а их чувства серьёзно притуплены. Эта проблема очевидна из-за постоянных неудач Optimus при телеоперировании. И вот в чём дело: если эти телеоператоры с трудом выполняют даже базовые задачи через Optimus, то и ИИ тоже будет, так как он может только плохо копировать их. Тот факт, что подход, похоже, полностью игнорирует эти фундаментальные основы обучения ИИ и предполагает, что видеоподражания и обучения телеоператора будет достаточно для того, чтобы Optimus взял на себя миллионы рабочих мест, вызывает вопросы. Это отсутствие понимания основной технологии, стоящей за Optimus, также может объяснить, почему Tesla обучает несколько роботов Optimus на своём заводе, а не проводит испытания, как Walker S2. Tesla почти наверняка пытается провести обучение видеоподражанием и телеоперированием базовым задачам производственной линии непосредственно на производственной линии. Таким образом, они могут получить доступ к людям и задачам, на которых они хотят обучить ИИ, и при этом сказать: «На заводе есть Optimus». Но Tesla обучает роботов Optimus как минимум три, если не четыре года. Тот факт, что Tesla ещё не провела испытания интеграции Optimus в производственные линии Tesla даже для поразительно базовых задач после всего этого времени, показателен. Подобные испытания являются критической частью разработки и доказательством концепции для инвесторов. Тот факт, что Tesla ещё даже не достигла этого фундаментального шага, настоятельно предполагает, что её подход к обучению ИИ гуманоидных роботов имеет фундаментальные проблемы и серьёзно ограничивает развитие, как и предсказывал Брукс. Говоря о методах обучения ИИ и их ограничениях — вы можете сами увидеть, насколько сложны эти технологии. Понимание того, как работают современные ИИ-модели, их сильных и слабых сторон, требует практического опыта. Сервисы вроде BotHub дают возможность экспериментировать с различными моделями ИИ — от языковых моделей до систем компьютерного зрения — чтобы понять на практике те самые проблемы обучения и ограничений, о которых мы говорим. Вы можете протестировать, как разные модели справляются с визуальными задачами, обработкой текста и другими функциями, которые критичны для робототехники. Для доступа не требуется VPN, можно использовать российскую карту. По ссылке вы можете получить 300 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас! Optimus можно охарактеризовать как амбициозный, но проблемный проект. Заявления о бизнес-стороне гуманоидной робототехники не соответствуют реальности, а конкуренты значительно опережают Tesla. Кроме того, очевидны проблемы с пониманием ИИ и робототехники, поскольку разрыв между реальностью и ожиданиями значителен. Будет интересно наблюдать за развитием этой ситуации в ближайшие годы и увидеть, как технология будет развиваться дальше. Творец контента в BotHub Ваш аккаунт Разделы Информация Услуги
Images (1): 
|
|||||
| Unitree Robots Perform Kung Fu Display | https://www.i-programmer.info/news/169-… | 1 | Feb 25, 2026 08:00 | active | |
Unitree Robots Perform Kung Fu DisplayURL: https://www.i-programmer.info/news/169-robotics/18679-unitree-robots-perform-kung-fu-display.html Description: Programming book reviews, programming tutorials,programming news, C#, Ruby, Python,C, C++, PHP, Visual Basic, Computer book reviews, computer history, programming history, joomla, theory, spreadsheets and more. Content:
Robots from Unitree have performed at China's Spring Festival Gala. The humanoid G1 robots performed a fast-paced robot cluster Kung Fu performance. Unitree's H2 humanoid robots were also on show, at both the Beijing main venue and the Yiwu sub-venue, clad in the Monkey King's heavy armor and riding a "somersault cloud" played by B2W quadruped robot dogs. The display was broadcast on state television during China's Spring Festival Gala. This is the country's biggest TV event of the year and is broadcast on the eve of the Lunar New Year. As part of the show, twenty-four Unitree G1 humanoid robots performed martial arts, parkour and breakdancing that was fast and impressive. The robots carried out synchronized punching, kicking and back-flipping. They also vaulted over obstacles and ran at up to nine miles an hour. The G1 robots also performed what the company describes as a "Cluster Cooperative Rapid Scheduling System" to form the Chinese characters for Happy New Year and the digits 2026. The Unitree G1 is described as an advanced, affordable humanoid robot designed for research, education, and AI development. Prices for it start at $13,500. It is around 127 cm tall and weighs around 35 kg. It has between 23 and 43 joints, 3D LiDAR, depth cameras, and 2 hours of battery life. The Unitree H2 stands 180 cm high and weights 70 kg. It was launched in October 2025 and is designed for advanced research, industrial applications, and human-robot interaction. It features 31 degrees of freedom for enhanced mobility, including arms that offer seven degrees of freedom and legs that have six degrees of freedom. According to Unitree, its motion control algorithms provide 31 degrees of freedom, 360N.m joint torque, and precise dynamic movement replication. It is powered by a 2070 TOPS chip, and "supports diverse intelligent models, enabling multiple work scenarios". The H2 is positioned as a high-end platform for AI development, capable of operating in warehouses, service roles, or research labs. It supports Python and C++, and has an SDK and supports the ROS2 framework. The H2 costs $29,900.00 USD, and there's a more expensive version that supports secondary development. Unitree Website Meet Figure 03: Dishwasher-Loading Robot Humanoid Alpha Learns To Wrap Xmas Presents A World First For Humanoid Robots To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. A Virtual Visit To Computer History Museum06/02/2026The Computer History Museum has officially launched OpenCHM, a new digital portal designed to expand access to its its . It's well worth a visit for anyone with an interest in computer hardware a [ ... ] + Full Story What Happened At The OpenSSL Conference 202530/01/2026The OpenSSL Conference is the premier event for cryptography and secure communications professionals. In 2025, it ran between October 7-9 in Prague. We check the highlights. + Full StoryMore NewsVSCode CMake Tools Extension UpdatedGoogle Adds Vibe Querying To BigQueryThe GNU C Compiler Breaks SecurityMongoDB Releases Mongot Source CodeSETI @home No MoreWhat Happened At The PostgreSQL Conference Europe 2025Anders Hejlsberg On C# And TypeScriptShaw Foundation Announces Prize For Computer ScienceDeno Introduces Sandbox And Deploy ToolGitHub Adds Claude And Codex To Agent HQYouTube At 21 - The Technical HistoryGo 1.26 Refines Language Syntax The Computer History Museum has officially launched OpenCHM, a new digital portal designed to expand access to its its . It's well worth a visit for anyone with an interest in computer hardware a [ ... ] The Computer History Museum has officially launched OpenCHM, a new digital portal designed to expand access to its its . It's well worth a visit for anyone with an interest in computer hardware a [ ... ] The OpenSSL Conference is the premier event for cryptography and secure communications professionals. In 2025, it ran between October 7-9 in Prague. We check the highlights. The OpenSSL Conference is the premier event for cryptography and secure communications professionals. In 2025, it ran between October 7-9 in Prague. We check the highlights. Comments Make a Comment or View Existing Comments Using Disqus or email your comment to: comments@i-programmer.info Make a Comment or View Existing Comments Using Disqus or email your comment to: comments@i-programmer.info
Images (1): 
|
|||||
| From Sound to Action : Deep Learning for Audio-Based Localization … | https://theses.hal.science/tel-05507206… | 1 | Feb 25, 2026 00:02 | active | |
From Sound to Action : Deep Learning for Audio-Based Localization and Navigation in Robotics - TEL - Thèses en ligneURL: https://theses.hal.science/tel-05507206v1 Description: Social robotics is a diverse, multidisciplinary research field aiming to design capable robotic agents.In particular, it addresses the challenges of human-robot interaction, in which robots operate not in isolated, controlled environments but alongside humans in performing dynamic andcomplex tasks.This domain poses numerous challenges, including multi-modal perception and action planning.This thesis explores a selection of essential tasks involved in building effective social robots, with a particular focus on their acoustic dimension.Specifically, we investigate Sound Source Localization (SSL) in both static and active contexts, as well as perceptually motivated robot navigation.To support this investigation, we first introduce a flexible and powerful acoustic simulation environment.It enables the virtual recording of signals in reverberant rooms, with the ability to model various microphone arrays, room geometries, and sound source configurations.Built upon state-of-the-art sound rendering libraries, this environment serves as a feature-rich sandbox for training and evaluating novel auditory algorithms.Since deep learning has enabled major advances in robotics but requires large volumes of data, often costly or impractical to collect with physical systems, simulation plays a key role in enabling scalable data generation.Within this simulated framework, we focus on auditory perception as a foundational capability.Among its various facets, SSL is especially critical for social robots.SSL involves identifying the location of one or more active speakers and is grounded in a long-standing body of research.We examine this problem from multiple perspectives and introduce a series of deep-learning-based methods to address its main challenges.After presenting a solution for the single-source case, we propose a more advanced multi-source localizer.Both models are thoroughly evaluated through extensive experiments conducted under varied conditions.However, in real-world social settings, robots rarely remain stationary.Their movement introduces new dimensions to the localization problem.To address this, we extend our SSL approach to dynamic scenarios, where motion is explicitly considered.We propose a novel method for aggregating predictions from our static multi-source localizer over time.This framework leverages the robot’s motion to refine its estimates of speaker positions.To support this, we extend our simulator to synthesize complete trajectories in virtual environments, enabling effective training and evaluation of this dynamic localization model.Having addressed perception, we then turn to action, the second pillar of robotic capability.We explore how modern Deep Reinforcement Learning (DRL) techniques can be applied to robot navigation, specifically to enhance auditory perception through movement.Recent Automatic Speech Recognition (ASR) models enable robots to transcribe human speech with high accuracy, but their performance can degrade significantly in reverberant environments.To mitigate this, we introduce a perceptually motivated navigation task in which a robot learns to position itself to minimize speech recognition errors.The agent’s decisions are based solely on audio captured by its microphone array.This final contribution builds directly upon our previous work in acoustic simulation and SSL, integrating perception and action to advance embodied auditory intelligence. Content:
Social robotics is a diverse, multidisciplinary research field aiming to design capable robotic agents.In particular, it addresses the challenges of human-robot interaction, in which robots operate not in isolated, controlled environments but alongside humans in performing dynamic andcomplex tasks.This domain poses numerous challenges, including multi-modal perception and action planning.This thesis explores a selection of essential tasks involved in building effective social robots, with a particular focus on their acoustic dimension.Specifically, we investigate Sound Source Localization (SSL) in both static and active contexts, as well as perceptually motivated robot navigation.To support this investigation, we first introduce a flexible and powerful acoustic simulation environment.It enables the virtual recording of signals in reverberant rooms, with the ability to model various microphone arrays, room geometries, and sound source configurations.Built upon state-of-the-art sound rendering libraries, this environment serves as a feature-rich sandbox for training and evaluating novel auditory algorithms.Since deep learning has enabled major advances in robotics but requires large volumes of data, often costly or impractical to collect with physical systems, simulation plays a key role in enabling scalable data generation.Within this simulated framework, we focus on auditory perception as a foundational capability.Among its various facets, SSL is especially critical for social robots.SSL involves identifying the location of one or more active speakers and is grounded in a long-standing body of research.We examine this problem from multiple perspectives and introduce a series of deep-learning-based methods to address its main challenges.After presenting a solution for the single-source case, we propose a more advanced multi-source localizer.Both models are thoroughly evaluated through extensive experiments conducted under varied conditions.However, in real-world social settings, robots rarely remain stationary.Their movement introduces new dimensions to the localization problem.To address this, we extend our SSL approach to dynamic scenarios, where motion is explicitly considered.We propose a novel method for aggregating predictions from our static multi-source localizer over time.This framework leverages the robot’s motion to refine its estimates of speaker positions.To support this, we extend our simulator to synthesize complete trajectories in virtual environments, enabling effective training and evaluation of this dynamic localization model.Having addressed perception, we then turn to action, the second pillar of robotic capability.We explore how modern Deep Reinforcement Learning (DRL) techniques can be applied to robot navigation, specifically to enhance auditory perception through movement.Recent Automatic Speech Recognition (ASR) models enable robots to transcribe human speech with high accuracy, but their performance can degrade significantly in reverberant environments.To mitigate this, we introduce a perceptually motivated navigation task in which a robot learns to position itself to minimize speech recognition errors.The agent’s decisions are based solely on audio captured by its microphone array.This final contribution builds directly upon our previous work in acoustic simulation and SSL, integrating perception and action to advance embodied auditory intelligence. La robotique sociale est un domaine de recherche vaste et multidisciplinaire, visant à concevoir des agents robotiques capables d’interagir efficacement.Elle traite notamment des défis posés par les interactions homme-robot, où les robots ne sont plus confinés à des environnements isolés, mais évoluent aux côtés des humains dans des contextes dynamiques et complexes.Ce domaine soulève de nombreux enjeux, notamment en perception multimodale et planification d’actions.Cette thèse explore un ensemble de tâches essentielles à la conception de robots sociaux efficaces, avec un accent particulier sur leur dimension acoustique.Plus précisément, nous étudions la localisation de sources sonores dans des contextes statiques et dynamiques, ainsi qu’une tâche de navigation robotique guidée par la perception auditive.Pour cela, nous introduisons un environnement de simulation acoustique flexible et performant.Il permet d'enregistrer virtuellement des signaux dans des pièces réverbérantes, en modélisant différentes configurations de microphones, de géométries de pièces et de sources sonores.Basé sur des bibliothèques de synthèse sonore de pointe, cet environnement constitue un espace d’expérimentation riche pour l’apprentissage et l’évaluation de nouveaux algorithmes auditifs.L’apprentissage profond a permis des avancées majeures en robotique, mais ces méthodes nécessitent de grandes quantités de données, souvent coûteuses ou difficiles à collecter dans des environnements physiques.La simulation joue ainsi un rôle clé dans la génération de données à grande échelle.Dans ce cadre virtuel, nous nous concentrons sur la perception auditive, considérée comme une capacité fondamentale.Parmi ses composantes, la localisation de sources sonores est essentielle pour les robots sociaux.Elle consiste à estimer la position d’un ou plusieurs locuteurs actifs, et repose sur une littérature scientifique riche et mature.Nous abordons ce problème sous plusieurs angles et proposons une série de méthodes fondées sur l’apprentissage profond pour en relever les principaux défis.Après une solution pour le cas à source unique, nous proposons un localisateur multi-sources plus avancé.Les deux modèles sont rigoureusement évalués au moyen d’expériences approfondies dans des conditions variées.Dans des contextes sociaux réels, les robots sont rarement immobiles.Leur mouvement introduit de nouvelles particularités dans le problème de localisation.Pour y répondre, nous étendons notre approche à des scénarios dynamiques, en tenant explicitement compte du déplacement du robot.Nous proposons une méthode d’agrégation temporelle des prédictions issues du localisateur multi-sources.Ce cadre exploite les déplacements du robot pour affiner les estimations de position des locuteurs.Le simulateur a été étendu pour générer des trajectoires complètes dans des environnements virtuels, facilitant un apprentissage et une évaluation efficaces de nos algorithmes dans ce contexte dynamique.Enfin, nous abordons l’action, second pilier des capacités robotiques.Nous appliquons des techniques d’apprentissage par renforcement profond à la navigation, afin d’améliorer la perception auditive par le mouvement.Les modèles récents de reconnaissance automatique de la parole permettent aux robots de transcrire la parole humaine avec précision, mais leurs performances peuvent se dégrader en présence de réverbération.Pour y remédier, nous introduisons une tâche de navigation guidée par la perception auditive, dans laquelle le robot apprend à se positionner pour minimiser les erreurs de reconnaissance.Les décisions de l’agent reposent uniquement sur les signaux audio captés par sa matrice de microphones.Cette dernière contribution s’appuie sur nos travaux précédents en simulation acoustique et en localisation, intégrant perception et action pour faire progresser l’intelligence auditive embarquée. Contact https://theses.hal.science/tel-05507206 Soumis le : jeudi 12 février 2026-14:20:01 Dernière modification le : mardi 24 février 2026-11:56:06 Contact Ressources Informations Questions juridiques Portails CCSD
Images (1): 
|
|||||
| Remote-Controlled Robots With Deadly Explosives Approved By SF Board Of … | https://www.dailywire.com/news/remote-c… | 1 | Feb 23, 2026 16:00 | active | |
Remote-Controlled Robots With Deadly Explosives Approved By SF Board Of SupervisorsDescription: The San Francisco Board of Supervisors, in an unprecedented move, has approved using remote-controlled robots armed with deadly explosives.The San Francisco Police Department claimed they would use such robots to breach buildings or “contact, incapacitate, or disorient violent, armed, or dangerous” suspects when lives are at stake, according to a spokesman for the department. The Board of Supervisors’ approval must now be passed in a second vote by the board and then get approved by San Francisco Mayor London Breed before the robots can be used.“Some of the supervisors said they are concerned police will disproportionately use lethal robots on Black and other people of color,” The Week reported.Supervisor Connie Chan stated, “According to state law, we are required to approve the use of these equipments. So here we are, and it’s definitely not a[n] easy discussion.”But Democrat Shamann Wilson, president of the Board of Supervisors, contended, “Most law enforcement weapons are used against people of color. I’m really just stunned that we’re here talking about this.”Only three senior police leaders have the power to authorize such actions, and they can only do so after other tactics have been attempted or the suspect cannot be subdued any other way.Former Los Angeles Police Department Lieutenant Adam Bercovici told The Washington Post, “If I was in charge, and I had that capability, it wouldn’t be the first on my menu. But it would be an option if things were really bad.”The Oakland Police Department had considered using similar robots but backtracked after the idea elicited harsh reaction. “The only known use of lethal robots by a U.S. police department was in Dallas in 2016, when police used a robot armed with explosives to kill a sniper who had ambushed and killed five officers,” The Week noted.That sniper was caught in a parking garage and killed by police with a robot-operated pound of C-4 explosive, which was guided by an extending arm toward the suspect. Dallas Police Chief David Brown stated, “You have to trust your people to make the calls. We believe that we saved lives by making this decision,” adding, “I appreciate critics, but they’re not on the ground, their lives are not being put at risk by debating what tactics to take.” Content:
The San Francisco Board of Supervisors, in an unprecedented move, has approved using remote-controlled robots armed with deadly explosives. The San Francisco Police Department claimed they would use such robots to breach buildings or “contact, incapacitate, or disorient violent, armed, or dangerous” suspects when lives are at stake, according to a spokesman for the department. The Board of Supervisors’ approval must now be passed in a second vote by the board and then get approved by San Francisco Mayor London Breed before the robots can be used. “Some of the supervisors said they are concerned police will disproportionately use lethal robots on Black and other people of color,” The Week reported. Supervisor Connie Chan stated, “According to state law, we are required to approve the use of these equipments. So here we are, and it’s definitely not a[n] easy discussion.” But Democrat Shamann Wilson, president of the Board of Supervisors, contended, “Most law enforcement weapons are used against people of color. I’m really just stunned that we’re here talking about this.” Only three senior police leaders have the power to authorize such actions, and they can only do so after other tactics have been attempted or the suspect cannot be subdued any other way. Former Los Angeles Police Department Lieutenant Adam Bercovici told The Washington Post, “If I was in charge, and I had that capability, it wouldn’t be the first on my menu. But it would be an option if things were really bad.” The Oakland Police Department had considered using similar robots but backtracked after the idea elicited harsh reaction. “The only known use of lethal robots by a U.S. police department was in Dallas in 2016, when police used a robot armed with explosives to kill a sniper who had ambushed and killed five officers,” The Week noted. That sniper was caught in a parking garage and killed by police with a robot-operated pound of C-4 explosive, which was guided by an extending arm toward the suspect. Dallas Police Chief David Brown stated, “You have to trust your people to make the calls. We believe that we saved lives by making this decision,” adding, “I appreciate critics, but they’re not on the ground, their lives are not being put at risk by debating what tactics to take.” Already have an account? Your information could be the missing piece to an important story. Submit your tip today and make a difference.
Images (1): 
|
|||||
| At China’s Shaolin Temple, humanoid robots become Kung Fu trainees … | https://www.indiatoday.in/trending-news… | 1 | Feb 23, 2026 16:00 | active | |
At China’s Shaolin Temple, humanoid robots become Kung Fu trainees - India TodayDescription: Robots have joined Shaolin monks in performing traditional Kung Fu routines at the renowned Shaolin Temple in Henan Province, China. Content:
An unexpected sight at China’s iconic Shaolin Temple has taken the internet by surprise. Humanoid robots were filmed practicing Shaolin Kung Fu alongside monks at the centuries-old temple in Henan province. According to CGTN, the robots are part of a technology demonstration, not formal religious training. In the viral video, the humanoid machines are seen mirroring monks’ movements, striking kung fu stances, repeating drills, and performing choreographed routines within the temple complex. The robots follow the monks closely, imitating posture, balance, and timing much like human trainees learning under a master. Watch the video here: Shaolin Temple has started practicing kung fu with robots. pic.twitter.com/ypWxxJqk7o— Sharing Travel (@TripInChina) February 4, 2026 The clips have sparked intense reactions online. While many viewers expressed amazement at the precision and fluidity of the robots’ movements, others questioned the implications of machines entering a space deeply tied to spirituality and discipline. Shaolin Kung Fu is not merely a physical practice; it is rooted in Buddhist philosophy, meditation, and mental control, traditions passed down over centuries. CGTN noted that the demonstration showcases advances in robotics, artificial intelligence, and motion-learning technology, using martial arts as a complex test of coordination and control. The involvement of Shaolin monks, the report clarified, was part of a cultural and technological exchange rather than an attempt to replace or modernise traditional training methods. As the videos continue to circulate, the sight of robots training at Shaolin has become a global talking point. To some, it symbolises innovation learning from heritage; to others, it raises uncomfortable questions about how far technology should enter sacred spaces.- EndsPublished By: Srimoyee ChowdhuryPublished On: Feb 9, 2026
Images (1): 
|
|||||
| AuraML launches India’s first multimodal world simulation model for robotics, … | https://www.thehindubusinessline.com/co… | 1 | Feb 23, 2026 00:01 | active | |
AuraML launches India’s first multimodal world simulation model for robotics, backed by NVIDIA - The HinduBusinessLineDescription: AuraML launches India’s first multimodal simulation model for robotics, enhancing development with NVIDIA’s advanced technology at the India-AI Summit. Content:
-1,236.11 -365.00 + 106.00 + 307.00 -263.00 -1,236.11 -365.00 -365.00 + 106.00 + 106.00 + 307.00 The platform supports simultaneous simulation of humanoid robots, autonomous mobile robots (AMRs), and stationary robotic arms operating within a shared virtual environment | Photo Credit: istock.com Indian AI start-up AuraML unveiled AuraSim, billed as India’s first multimodal world simulation model for robotics, built on NVIDIA’s Omniverse and Cosmos infrastructure. The announcement was made in New Delhi, coinciding with the India–AI Impact Summit 2026 under the Government of India’s India AI Mission. AuraSim allows developers to generate physics-ready, three-dimensional simulation environments from multiple input types, including text descriptions, 2D floorplans, video walkthroughs, depth maps, and point clouds. The platform is designed to reduce the time and cost of training autonomous robotic systems by creating high-fidelity digital twins before any hardware is deployed. The platform supports simultaneous simulation of humanoid robots, autonomous mobile robots (AMRs), and stationary robotic arms operating within a shared virtual environment. AuraML said its agentic automation pipeline can run thousands of scenario variations without human intervention, enabling rapid stress-testing of edge cases through simple text prompt modifications. Alongside AuraSim, AuraML is launching the Global Physical AI & Robotics Cohort in collaboration with NVIDIA Inception, an eight-week mentorship-driven training program for robotics engineers, AI researchers, and developers, offered with limited seats. “By launching the first multimodal world simulation model from India, powered by NVIDIA’s world-class simulation technology, we are providing a global toolset to accelerate the development of advanced robotics foundation models everywhere,” said Ayush Sharma, co-founder of AuraML. Tobias Halloran, Director of EMEAI start-ups and Venture Capital at NVIDIA, noted that India’s AI start-up ecosystem is is seeing strong momentum, with NVIDIA providing founders access to accelerated computing and scalable AI infrastructure through programs like NVIDIA Inception. AuraML describes itself as focused on building foundational world models for next-generation robotics using generative AI and physics-based simulation. Published on February 19, 2026 Copyright© 2026, THG PUBLISHING PVT LTD. or its affiliated companies. All rights reserved. BACK TO TOP Comments have to be in English, and in full sentences. They cannot be abusive or personal. Please abide by our community guidelines for posting your comments. We have migrated to a new commenting platform. If you are already a registered user of TheHindu Businessline and logged in, you may continue to engage with our articles. If you do not have an account please register and login to post comments. Users can access their older comments by logging into their accounts on Vuukle. Terms & conditions | Institutional Subscriber
Images (1): 
|
|||||
| Robot Talk Episode 143 – Robots for children, with Elmira … | https://robohub.org/robot-talk-episode-… | 0 | Feb 23, 2026 00:01 | active | |
Robot Talk Episode 143 – Robots for children, with Elmira YadollahiURL: https://robohub.org/robot-talk-episode-143-robots-for-children-with-elmira-yadollahi/ Content: |
|||||
| US AI firm accelerates international rollout of Chinese humanoid robots | https://interestingengineering.com/ai-r… | 1 | Feb 23, 2026 00:01 | active | |
US AI firm accelerates international rollout of Chinese humanoid robotsURL: https://interestingengineering.com/ai-robotics/chinese-humanoid-robots-global-push-challenge Description: A US-based company is positioning itself as a conduit for the global expansion of Chinese humanoid robotics firms. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation. Engineering-inspired textiles, mugs, hats, and thoughtful gifts We connect top engineering talent with the world's most innovative companies. We empower professionals with advanced engineering and tech education to grow careers. We recognize outstanding achievements in engineering, innovation, and technology. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation. Engineering-inspired textiles, mugs, hats, and thoughtful gifts We connect top engineering talent with the world's most innovative companies We empower professionals with advanced engineering and tech education to grow careers. We recognize outstanding achievements in engineering, innovation, and technology. All Rights Reserved, IE Media, Inc. OpenMind is already collaborating with several Chinese firms – including Unitree Robotics, UBTech Robotics, AgiBot, and LimX Dynamics. As Chinese humanoid robot manufacturers ramp up international ambitions, OpenMind is positioning itself as a gateway to global markets. The US-based company develops OM1, an open-source, AI-native operating system designed specifically for robots, and sees an opportunity to provide the software layer and ecosystem support needed to scale abroad. China is unquestionably ahead of the US in robotics hardware, OpenMind CEO Jan Liphardt said, pointing to the country’s vertically integrated supply chains and fierce domestic competition that accelerates iteration cycles. He added that OpenMind is already collaborating with several Chinese firms – including Unitree Robotics, UBTech Robotics, AgiBot, LimX Dynamics, Booster Robotics and Engine AI – as they expand their focus beyond the Chinese market. Chinese robotics companies have established a significant footprint in Silicon Valley, reflecting their growing engagement with the US technology ecosystem, Liphardt added. In addition to leading OpenMind, Liphardt serves as a professor of bioengineering at Stanford University. He noted that closer coordination between OpenMind and Chinese robot manufacturers could help streamline regulatory, commercial and technical hurdles, making it easier for those firms to introduce and scale their products in the US market, the South China Morning Post reported. Liphardt emphasized that running software developed and hosted in the US, with local data storage and cloud infrastructure, can help Chinese robotics firms deal with complex regulatory environments. He framed the philosophy behind OpenMind’s work in simple terms: if humans are going to coexist with machines, understanding how they think is essential. OM1, the company’s AI-native operating system, is designed to be hardware-agnostic, enabling seamless deployment across a wide range of platforms, from quadrupeds and humanoids to wheeled robots and drones, giving developers flexibility to innovate without being tied to a specific robot chassis. OpenMind’s operating system integrates multimodal inputs – including vision, audio and spatial data – to create a unified model that determines a robot’s actions and converts them into precise hardware commands, Liphardt explained. The company prioritizes applications where robots interact directly with humans, such as in retail environments, hospitals, and schools. Liphardt was clear that OpenMind has no plans to enter the industrial robotics market, noting that companies like Amazon have already established widespread adoption of factory and warehouse robots, making that space highly mature. Moreover, OpenMind’s work with Chinese robotics companies goes beyond technology, extending into marketing support, said Gavin Wong, the company’s head of marketing based in San Francisco. Although several Chinese robotics firms are entering Western markets, many struggle to build brand recognition or cultivate a dedicated following outside Asia, Wong noted. He explained that the type of content these firms produce often differs significantly from what resonates with Western audiences. By collaborating with OpenMind, he said, they can leverage localized marketing strategies and campaigns to better engage global customers and amplify their presence on the international stage. Bojan Stojkovski is a freelance journalist based in Skopje, North Macedonia, covering foreign policy and technology for more than a decade. His work has appeared in Foreign Policy, ZDNet, and Nature. Exclusive content, expert insights and a deeper dive into engineering and tech. No ads, no limits. Exclusive content, expert insights and a deeper dive into engineering and tech. No ads, no limits. Premium Follow
Images (1): 
|
|||||
| Boston Dynamics начинает выпуск чудо-робота Atlas | https://charter97.org/ru/news/2026/1/10… | 0 | Feb 22, 2026 00:02 | active | |
Boston Dynamics начинает выпуск чудо-робота AtlasURL: https://charter97.org/ru/news/2026/1/10/669463/ Description: Машина двигается как человек и готова к работе на промпредприятиях. Content: |
|||||
| Посмотрите, как робот Boston Dynamics научился новым трюкам | https://hightech.fm/2026/02/09/boston-d… | 1 | Feb 22, 2026 00:02 | active | |
Посмотрите, как робот Boston Dynamics научился новым трюкамURL: https://hightech.fm/2026/02/09/boston-d-salto Description: Boston Dynamics показала, на что способен человекоподобный робот Atlas перед выходом в промышленность. В новом видео он с разбега делает колесо и сразу после этого выполняет сальто назад, уверенно приземляясь на ноги. Content:
Boston Dynamics показала, на что способен человекоподобный робот Atlas перед выходом в промышленность. В новом видео он с разбега делает колесо и сразу после этого выполняет сальто назад, уверенно приземляясь на ноги. Компания Boston Dynamics опубликовала ролик, в котором робот Atlas выполняет рондат и сальто назад. Видео быстро разошлось по соцсетям, после чего разработчики выложили расширенную версию — с неудачными попытками, падениями и ошибками перед удачным дублем. В длинном ролике Atlas теряет равновесие, падает и даже приземляется на голову. В описании к видео компания заявила, что это «последний забег» исследовательской версии робота. Впереди — переход к коммерческой платформе Atlas. Этот этап Boston Dynamics провела вместе с Институтом робототехники и искусственного интеллекта RAI, который ранее носил имя института ИИ Boston Dynamics. Его возглавляет основатель компании Марк Райберт. Задача команды — проверить пределы подвижности конструкции и алгоритмов управления. Разработчики отмечают, что акробатические трюки и плавная походка, которую Atlas показывал на CES 2026, выросли из одного и того же подхода к обучению. Робота тренировали с помощью системы, рассчитанной на так называемый «нулевой перенос» — когда модель поведения из симуляции сразу работает на физическом роботе без ручной донастройки. В Boston Dynamics считают, что этот результат приближает гуманоидных роботов к стабильному и универсальному поведению в реальной среде. Пока исследовательская версия Atlas снимается в эффектных видео, производственный вариант готовят к работе на заводах. Коммерческая версия получит 56 степеней свободы и четырёхпальцевые захваты с тактильными датчиками. Hyundai Motor Group уже подтвердила, что внедрит роботов Atlas на своём заводе в Джорджии к 2028 году. На первом этапе им поручат сортировку деталей. К 2030 году роботов планируют допустить к сборке узлов. Читать далее: Вселенная внутри черной дыры: наблюдения «Уэбба» подтверждают странную гипотезу Испытания ракеты Starship Илона Маска вновь закончились взрывом в небе Сразу четыре похожих на Землю планеты нашли у ближайшей одиночной звезды Обложка: YouTube | Boston Dynamics Пройдите, пожалуйста, мини-опрос, который поможет нам стать еще интереснее и полезнее для вас!
Images (1): 
|
|||||
| Hyundai Revealed Boston Dynamics' Next-Gen Humanoid Robots | https://www.bgr.com/2071680/hyundai-rev… | 1 | Feb 22, 2026 00:02 | active | |
Hyundai Revealed Boston Dynamics' Next-Gen Humanoid RobotsURL: https://www.bgr.com/2071680/hyundai-reveal-next-gen-robot-boston-dynamics-robot-atlas/ Description: At the 2026 CES show, Hyundai and Boston Dynamics took the wraps off its next-gen humanoid robot, Atlas, that is nearly ready for commercial use. Content:
Artificial intelligence is one of the most important tech innovations of the decade, with most consumer electronics companies working on new AI features for their products, from chatbots to devices with built-in AI capabilities. These developments will lead to smarter AI models that power more advanced gadgets, including smart humanoid robots, many of which already exist as concepts or development prototypes. Several humanoid robots were shown at CES 2026, including Hyundai's Boston Dynamics Atlas robot. Unlike less mature products that aren't ready for a public roll-out, Atlas is already in production ahead of its planned deployment in Hyundai factories. Boston Dynamics explained on stage at CES 2026 that the entire 2026 Atlas production capacity will serve Hyundai. A strategic partnership with Google DeepMind was also announced, to "accelerate technological development for next-generation humanoid robots", per a Hyundai press release. Google's DeepMind has been doing its own robotics AI research in recent years, including the mind-blowing Gemini Robotics models that should allow robots to more naturally interact with the world around them. Boston Dynamics says its own Orbit platform will allow the Atlas to share learned skills with other Atlas robots. Production of the Atlas robots is set to start at Boston Dynamics' headquarters with plans in the works for Hyundai and Boston Dynamics to build a factory capable of turning out 30,000 humanoids annually. The commercial version of Atlas, which was shown on stage at CES, will be used for parts sequencing at the Hyundai Motor Group Metaplant America factory in Savannah, Georgia, beginning in 2028. Hyundai's subsidiary, Boston Dynamics, brought an Atlas prototype robot (white model) to the 2026 CES show to demo its features, as the commercial version (blue model) wasn't functional during the announcement. However, the two humanoid robots look almost identical and can perform similar actions. Boston Dynamics explained the Atlas's head features cameras on all sides for 360-degree vision. Atlas's body is also a technological breakthrough. It looks like a human, with a torso, hands, and feet, but has 56 degrees of freedom. This allows the robot to completely rotate its head, torso, hands, and fingers, which means it can interact with nearby objects more efficiently than a person. Atlas can also rise from a folded position, so it will take up less space when not working or performing an action. Speaking of work, Atlas has a battery life of about four hours, thanks to dual battery packs stored in the torso. When the batteries run low, the robot will swap them autonomously. Also, Atlas is water resistant and can work in a variety of weather conditions. Boston Dynamics said the robot can operate between -4° and 104°Fahrenheit. By 2030, "Atlas will also take on tasks involving repetitive motions, heavy loads, and other complex operations," according to Hyundai. Atlas stands 6.2 feet tall and weighs 198 pounds. It has a reach of 7.5 feet, hands that feature tactile sensing in the fingers and palms for dexterity, and can lift objects weighing up to 110 pounds. That's the instant lift capability, however, with sustained weight capacity listed at 66 pounds. And when Atlas is used for heavy lifting, the battery life will be cut in half, according to Boston Dynamics. Atlas can replace those batteries in three minutes, and the used packs can be recharged in an hour and a half. Put differently, Boston Dynamics' Atlas is much closer to commercial deployment than alternatives, including Tesla's Optimus, the general-purpose humanoid robot that Elon Musk showed off in 2024. That said, Atlas will not be available for general sale anytime soon. The robot will be used in manufacturing environments first, starting with Hyundai factories. Boston Dynamics has not yet announced a price for the robot, so don't get your hopes up if you're in the contingent who would happily buy a humanoid AI robot to do chores and help out with tedious or physically demanding tasks.
Images (1): 
|
|||||
| Boston Dynamics Debuts Atlas at CES | https://www.under30ceo.com/boston-dynam… | 1 | Feb 22, 2026 00:02 | active | |
Boston Dynamics Debuts Atlas at CESURL: https://www.under30ceo.com/boston-dynamics-debuts-atlas-at-ces/ Description: Hyundai-owned Boston Dynamics brought its humanoid robot, Atlas, onto a public stage at the CES tech showcase, marking a first for the company and the machine. The on-floor appearance signals a new push to move humanoids from lab videos to live demonstrations before customers, partners, and regulators. It also positions Hyundai’s robotics bet squarely in front of a global audience focused on automation, supply chains, and labor shortages. “Hyundai-owned Boston Dynamics has publicly demonstrated its humanoid robot Atlas for the first time at the CES tech showcase.” Boston Dynamics did not rely on a prerecorded reel alone. The company showed Atlas working through controlled motions in real time. The demo sought to answer a key question that has followed the field for years: can humanoids operate safely and predictably near people, outside research settings? From Research Star to Public Stage Boston Dynamics has spent more than a decade refining Atlas as a high-mobility humanoid. Earlier versions appeared in tightly scripted videos that highlighted jumps, parkour, and precise manipulation tasks. Those clips drew broad interest, but they left open questions about reliability and practical use. Hyundai acquired a controlling stake in the company in 2021, shifting focus from pure research to […] Content:
Hyundai-owned Boston Dynamics brought its humanoid robot, Atlas, onto a public stage at the CES tech showcase, marking a first for the company and the machine. The on-floor appearance signals a new push to move humanoids from lab videos to live demonstrations before customers, partners, and regulators. It also positions Hyundai’s robotics bet squarely in front of a global audience focused on automation, supply chains, and labor shortages. “Hyundai-owned Boston Dynamics has publicly demonstrated its humanoid robot Atlas for the first time at the CES tech showcase.” Boston Dynamics did not rely on a prerecorded reel alone. The company showed Atlas working through controlled motions in real time. The demo sought to answer a key question that has followed the field for years: can humanoids operate safely and predictably near people, outside research settings? Boston Dynamics has spent more than a decade refining Atlas as a high-mobility humanoid. Earlier versions appeared in tightly scripted videos that highlighted jumps, parkour, and precise manipulation tasks. Those clips drew broad interest, but they left open questions about reliability and practical use. Hyundai acquired a controlling stake in the company in 2021, shifting focus from pure research to applications in manufacturing and logistics. In 2024, Boston Dynamics introduced a new electric Atlas, moving away from hydraulics to pursue quieter operation and easier maintenance. The CES appearance adds a new chapter by placing the machine in a live setting with industry guests. A live demo, even a brief one, hints at progress in balance, control, and safety systems. It suggests more confidence in repeatability under bright lights and variable conditions. It also reflects an industry trend to show working prototypes near potential buyers rather than behind closed doors. The company appears to be signaling readiness for pilot programs where humans and robots share space. That includes tasks like moving totes, staging parts, or tending machines that need frequent, small adjustments. Atlas enters a busier field than in years past. Agility Robotics has tested Digit in warehouses. Tesla has shown progress on Optimus. Other startups are building general-purpose machines for repetitive work. Each group is chasing similar goals: safer motions, longer runtime, and useful grasping in tight spaces. Boston Dynamics brings a long track record in legged robots like Spot and Stretch. That history may help with traction, fall recovery, and reliability. But humanoids face limits that wheels and tracks avoid, including balance on uneven floors and energy demands from legged motion. For Hyundai, live demos support a strategy that blends vehicles, factories, and robotics. Automakers seek flexible automation that can shift jobs as product lines change. A humanoid that can handle varied tasks without major retooling is attractive, even if early units remain costly. Analysts expect testing to start with low-risk activities, such as moving empty containers or scanning inventory. If results are steady, tasks could expand to light assembly, machine tending, or end-of-line inspection. Insurance and safety audits will shape the pace of adoption. Public demonstrations carry new obligations. Companies must show fail-safes, clear emergency stops, and predictable behavior near people. Workers and unions also want transparency about job impacts and training. Policymakers are watching for standards on testing, reporting, and incident response. Experts often urge a phased approach. Small pilots with clear metrics can prove value and build trust. Regular updates on uptime, failure modes, and injury rates can help turn curiosity into acceptance. Key signals will come from pilot announcements, factory trials, and third-party testing. Battery life, service intervals, and parts availability will matter as much as agility. Pricing and support plans will determine whether companies test one unit or dozens. The CES appearance suggests Boston Dynamics is ready to move past viral clips and into customer-facing trials. If Atlas can work safely around people and handle routine tasks, demand could build in logistics and manufacturing. If not, wheeled and fixed automation will continue to dominate near-term spending. For now, the public debut sets a clearer bar for performance under pressure. The next step is proving that same performance, day after day, on factory floors and warehouse aisles. Editor in Chief of Under30CEO. I have a passion for helping educate the next generation of leaders. MBA from Graduate School of Business. Former tech startup founder. Regular speaker at entrepreneurship conferences and events. Under30CEO is a publication dedicated to young people dreaming big. Since its founding in 2008, the site has been committed to inspiring, educating, and featuring the doers of the world. Led by editor-in-chief, Kimberly Zhang, our editorial staff works hard to make each piece of content is to the highest standards. Our rigorous editorial process includes editing for accuracy, recency, and clarity. (C) COPYRIGHT | Privacy Site by Under 30 CEO Signup for our newsletter to get access to our proven pitch deck template.
Images (1): 
|
|||||
| Новый трюк от робота Boston Dynamics | https://fishki.net/video/4997443-novyj-… | 1 | Feb 22, 2026 00:02 | active | |
Новый трюк от робота Boston DynamicsURL: https://fishki.net/video/4997443-novyj-trjuk-ot-robota-boston-dynamics.html Description: Человекоподобный робот 'Atlas' от компании 'Boston Dynamics' теперь может выполнить рондад и полное сальто назад – Самые лучшие и интересные видео по теме: Android, Boston Dynamics, Видео на развлекательном портале Fishki.net Content:
Человекоподобный робот "Atlas" от компании "Boston Dynamics" теперь может выполнить рондад и полное сальто назад. Boston Dynamics выложила ролик, где робот Atlas с разбега делает рондат, сразу переходит в сальто назад и чётко приземляется на ноги. Помимо удачного дубля там показали и нарезку неудачных попыток — робот теряет равновесие, заваливается набок, приземляется на голову. За акробатикой стоит серьёзная работа. Трюки — финальный тест исследовательской версии Atlas перед тем, как коммерческая платформа займёт её место. Проводили его совместно с Институтом робототехники и искусственного интеллекта (RAI) под руководством основателя Boston Dynamics Марка Райберта. Задача — проверить абсолютные пределы мобильности конструкции и алгоритмов. Человекоподобный робот "Atlas" от компании "Boston Dynamics" теперь может выполнить рондад и полное сальто назад. Ключевая технология здесь — так называемый «нулевой перенос». Модель поведения сначала тренируют в симуляции, а затем переносят на физического робота без промежуточной настройки. Именно благодаря этому подходу Atlas и делает сальто, и демонстрирует плавную естественную походку. А производственный Atlas тем временем готовится к работе. У него 56 степеней свободы и четырёхпальцевые захваты с тактильными датчиками. Hyundai подтвердила, что к 2028 году роботы выйдут на завод в Джорджии — сначала на сортировку деталей, а к 2030-му планируют доверить им сборку узлов. Источник: !!! Оскорбления в комментариях автора поста или собеседника. Комментарий скрывается из ленты, автору выписывается бан на неделю. Допускаются более свободные споры в ленте с политикой, но в доступных, не нарушающих УК РФ, пределах. ! Мат на картинке/в комментарии. Ваш комментарий будет скрыт. При злоупотреблении возможен бан. ! Флуд - дублирующиеся комментарии от одного и того же пользователя в разных постах, систематические ложные вызовы модераторов с помощью функции @moderator, необоснованные обращения в техническую поддержку сайта, комментарии не несущие смысловой нагрузки и состоящие из хаотичного набора букв. Санкции - предупреждение с дальнейшим баном при рецидиве. ! Публикация рекламных постов. Несогласованное размещение рекламного материала, влечет незамедлительную приостановку действий учетной записи пользователя. ! Публикация материала, запрещенного на территории РФ и преследуемого УК РФ. Незамедлительная приостановка действия учетной записи пользователя. ! Мультиаккаунты. Использование нескольких активных аккаунтов, принадлежащих одному пользователю (исключение - дополнительный аккаунт для обращения в тех. поддержку при блокировке основного аккаунта) запрещено. За нарушение предусмотрено отключение основного аккаунта с возможной дальнейшей блокировкой любого аккаунта от данного пользователя. !!! Оскорбления в комментариях автора поста или собеседника. Комментарий скрывается из ленты, автору выписывается бан на неделю. Допускаются более свободные споры в ленте с политикой, но в доступных, не нарушающих УК РФ, пределах. ! Мат на картинке/в комментарии. Ваш комментарий будет скрыт. При злоупотреблении возможен бан. ! Флуд - дублирующиеся комментарии от одного и того же пользователя в разных постах, систематические ложные вызовы модераторов с помощью функции @moderator, необоснованные обращения в техническую поддержку сайта, комментарии не несущие смысловой нагрузки и состоящие из хаотичного набора букв. Санкции - предупреждение с дальнейшим баном при рецидиве. ! Публикация рекламных постов. Несогласованное размещение рекламного материала, влечет незамедлительную приостановку действий учетной записи пользователя. ! Публикация материала, запрещенного на территории РФ и преследуемого УК РФ. Незамедлительная приостановка действия учетной записи пользователя. ! Мультиаккаунты. Использование нескольких активных аккаунтов, принадлежащих одному пользователю (исключение - дополнительный аккаунт для обращения в тех. поддержку при блокировке основного аккаунта) запрещено. За нарушение предусмотрено отключение основного аккаунта с возможной дальнейшей блокировкой любого аккаунта от данного пользователя. На что жалуетесь?
Images (1): 
|
|||||
| Уходит в отставку гендиректор Boston Dynamics, сделавший компанию великой - … | https://www.cnews.ru/news/top/2026-02-1… | 1 | Feb 22, 2026 00:02 | active | |
Уходит в отставку гендиректор Boston Dynamics, сделавший компанию великой - CNewsURL: https://www.cnews.ru/news/top/2026-02-11_gendirektor_boston_dynamics_uhodit Description: Генеральный директор Boston Dynamics после 30 лет работы в компании на различных должностях уходит в отставку. Он превратил компанию из исследовательской лаборатории в успешный бизнес, известный... Content:
Разделы Генеральный директор Boston Dynamics после 30 лет работы в компании на различных должностях уходит в отставку. Он превратил компанию из исследовательской лаборатории в успешный бизнес, известный разработками Spot, Stretch и Atlas. Он покинет пост в конце февраля 2026 г. Генеральный директор Boston Dynamics Роберт Плейтер (Robert Plater) объявил об отставке, пишет The Verge. Он покидает пост в феврале 2026 г. Руководитель Boston Dynamics Роберт Плейтер официально объявил о своем уходе в отставку. Он покинет пост в конце февраля 2026 г., завершив свою шестилетнюю каденцию на посту руководителя. Господин Плейтер посвятил компании более трех десятилетий, пройдя путь от разработок в лаборатории до создания глобального бизнеса, который сейчас принадлежит южнокорейской группе Hyundai Motor Group. Роберт Плейтер является настоящим ветераном Boston Dynamics, ведь он начал работать в ней еще в те времена, когда она была лишь небольшой лабораторией в Массачусетском технологическом институте (MIT). Роберт Плейтер вспоминает, что нынешние достижения компании значительно превзошли его ожидания с периода работы в подвальной лаборатории MIT Media Lab. Именно при его руководстве Boston Dynamics трансформировалась из исследовательского центра в успешное коммерческое предприятие, сменив владельца с SoftBank на Hyundai Motor Group в 2021 г. «Роберт Плейтер является иконой мировой индустрии робототехники, и вся команда Boston Dynamics желает выразить ему искреннюю благодарность за его лидерство. От самых первых дней прыгающих роботов, до первых в мире четвероногих, до ведущей роли во всей отрасли гуманоидной робототехники, он оставил свой след как пионер инноваций. Он превратил Boston Dynamics из небольшой научно-исследовательской лаборатории в успешный бизнес, который сейчас с гордостью называет себя мировым лидером в области мобильной робототехники. Мы будем очень скучать по нему, но надеемся, что он наслаждается заслуженным отдыхом. Спасибо, Роб!», — комментарий для Automate от Boston Dynamics. По словам вице-президента по маркетингу Николаса Ноэля (Nicholas Noel), Роберт Плейтер превратил Boston Dynamics в мирового лидера мобильной робототехники. Сам бывший руководитель считает наиболее значимыми достижениями разработку роботов Spot, Stretch и Atlas. История Boston Dynamics началась в 1992 г., когда компания отделилась от MIT. Свои первые шаги будущий лидер робототехники делал в подвальной лаборатории MIT Media Lab. На начальных этапах разработки финансировались Управлением перспективных исследовательских проектов Министерства обороны США, что позволило создать таких роботов, как BigDog. Однако настоящее мировое признание пришло к компании благодаря виральным видео в интернете, главными звездами которых стали человекоподобный робот Atlas, способный делать сальто назад, и четвероногий робот-пес Spot. Долгое время разработки оставались чисто исследовательскими, но в июне 2020 г. Boston Dynamics начала продавать модель Spot по цене $74,5 тыс. Spot предлагали бизнесу для патрулирования и инспекции складов, а также тестировали в различных сферах: от выпаса овец до помощи медикам во время пандемии. Несмотря на медийную популярность, компания в течение многих лет оставалась убыточной, теряя миллионы долларов ежегодно. В 2021 г. Hyundai Motor Group приобрела контрольный пакет акций Boston Dynamics в размере 80% у SoftBank за $880 млн. Hyundai Motor Group уже использует роботов Spot компании Boston Dynamics на своих предприятиях для проведения работ по производственному контролю и профилактическому обслуживанию, о чем информировал CNews. Вице-председатель Hyundai Motor Group Джэхун Чан (Jaehoon Chang) заявил тогда о том, что Boston Dynamics и робототехнический искусственный интеллект (ИИ) будут играть решающую роль в выполнении задач компании, позволив вывести бизнес на новый уровень. Роберт Плейтер добавил, что сотрудничество с Hyundai Motor Group позволит ей лучше понять производственные потребности автопроизводителя и то, как роботы смогут помочь ему повысить производительность и эффективность. После того как Роберт Плейтер покинет свой пост в конце февраля 2026 г., временно исполнять обязанности генерального директора Boston Dynamics будет Аманда Макмастер (Amanda McMaster), которая сейчас является финансовым директором компании. Антон Денисенко ВЭБ.РФ создал защищенный мобильный контур для удаленной экспертизы многомиллиардных проектов Глобализация пошла не по плану. Украинца бросили в тюрьму на долгие годы за помощь КНДР в краже данных у США CNewsMarket опубликовал новый рейтинг российских виртуальных АТС ИИ в облаке Amazon удалил почти весь код, чтобы переписать его с нуля Александр Светкин, Microsoft: Роль ИИ смещается от обнаружения аномалий к помощи в устранении инцидентов ИТ-гигант заставляет руководителей использовать ИИ, угрожая оставить без продвижения Рассчитать стоимость кластеров Kubernetes От 0.52 руб./месяц Подобрать тариф на IP-телефонию и виртуальную АТС От 1 046 руб./месяц Подобрать систему управления бизнес-процессами BPM От 1 250 руб./месяц Выбрать тариф для резервного копирования данных От 0.03 руб./месяц Обзор: ИТ-тренды в России 2026 erid: Рекламодатель: ИНН/ОГРН: Сайт: https://www.cnews.ru/reviews/it-trendy_v_rossii_2026 Обзор: Российские ВКС-платформы erid: Рекламодатель: ИНН/ОГРН: Сайт: Андрей Нестеров ИТ-директор аэропорта Пулково erid: Рекламодатель: ИНН/ОГРН: Сайт: Обзор: Российские ВКС-платформы erid: Рекламодатель: ИНН/ОГРН: Сайт: Обзор: ИТ-тренды в России 2026 erid: Рекламодатель: ИНН/ОГРН: Сайт: Андрей Омельчук замглавы Минобрнауки erid: Рекламодатель: ИНН/ОГРН: Сайт: Материалы, помеченные знаком ■, являются рекламой Все права защищены © 1995 – 2026 Сетевое издание «CNews» («СиНьюс») зарегистрировано Федеральной службой по надзору в сфере связи, информационных технологий и массовых коммуникаций 09.11.2018 за номером Эл № ФС77 – 74283 Нажимая кнопку «Подписаться», вы даете свое согласие на обработку и хранение персональных данных. Токен: 1 Рекламодатель: 1 ИНН/ОГРН: 1 Сайт: 1 Подписаться на
Images (1): 
|
|||||
| Сделавший Boston Dynamics великой гендиректор уходит с поста | https://russianelectronics.ru/2026-02-1… | 1 | Feb 22, 2026 00:02 | active | |
Сделавший Boston Dynamics великой гендиректор уходит с постаURL: https://russianelectronics.ru/2026-02-12-boston-dynamics/ Description: Генеральный директор Boston Dynamics после 30 лет работы в компании на различных должностях уходит в отставку. Content:
Генеральный директор Boston Dynamics после 30 лет работы в компании на различных должностях уходит в отставку. Он превратил компанию из исследовательской лаборатории в успешный бизнес, известный разработками Spot, Stretch и Atlas. Он покинет пост в конце февраля 2026 г. Генеральный директор Boston Dynamics Роберт Плейтер (Robert Plater) объявил об отставке, пишет The Verge. Он покидает пост в феврале 2026 г. Руководитель Boston Dynamics Роберт Плейтер официально объявил о своем уходе в отставку. Он покинет пост в конце февраля 2026 г., завершив свою шестилетнюю каденцию на посту руководителя. Господин Плейтер посвятил компании более трех десятилетий, пройдя путь от разработок в лаборатории до создания глобального бизнеса, который сейчас принадлежит южнокорейской группе Hyundai Motor Group. Роберт Плейтер является настоящим ветераном Boston Dynamics, ведь он начал работать в ней еще в те времена, когда она была лишь небольшой лабораторией в Массачусетском технологическом институте (MIT). Роберт Плейтер вспоминает, что нынешние достижения компании значительно превзошли его ожидания с периода работы в подвальной лаборатории MIT Media Lab. Именно при его руководстве Boston Dynamics трансформировалась из исследовательского центра в успешное коммерческое предприятие, сменив владельца с SoftBank на Hyundai Motor Group в 2021 г. «Роберт Плейтер является иконой мировой индустрии робототехники, и вся команда Boston Dynamics желает выразить ему искреннюю благодарность за его лидерство. От самых первых дней прыгающих роботов, до первых в мире четвероногих, до ведущей роли во всей отрасли гуманоидной робототехники, он оставил свой след как пионер инноваций. Он превратил Boston Dynamics из небольшой научно-исследовательской лаборатории в успешный бизнес, который сейчас с гордостью называет себя мировым лидером в области мобильной робототехники. Мы будем очень скучать по нему, но надеемся, что он наслаждается заслуженным отдыхом. Спасибо, Роб!», — комментарий для Automate от Boston Dynamics. По словам вице-президента по маркетингу Николаса Ноэля (Nicholas Noel), Роберт Плейтер превратил Boston Dynamics в мирового лидера мобильной робототехники. Сам бывший руководитель считает наиболее значимыми достижениями разработку роботов Spot, Stretch и Atlas. История Boston Dynamics началась в 1992 г., когда компания отделилась от MIT. Свои первые шаги будущий лидер робототехники делал в подвальной лаборатории MIT Media Lab. На начальных этапах разработки финансировались Управлением перспективных исследовательских проектов Министерства обороны США, что позволило создать таких роботов, как BigDog. Однако настоящее мировое признание пришло к компании благодаря виральным видео в интернете, главными звездами которых стали человекоподобный робот Atlas, способный делать сальто назад, и четвероногий робот-пес Spot. Долгое время разработки оставались чисто исследовательскими, но в июне 2020 г. Boston Dynamics начала продавать модель Spot по цене $74,5 тыс. Spot предлагали бизнесу для патрулирования и инспекции складов, а также тестировали в различных сферах: от выпаса овец до помощи медикам во время пандемии. Несмотря на медийную популярность, компания в течение многих лет оставалась убыточной, теряя миллионы долларов ежегодно. В 2021 г. Hyundai Motor Group приобрела контрольный пакет акций Boston Dynamics в размере 80% у SoftBank за $880 млн. Hyundai Motor Group уже использует роботов Spot компании Boston Dynamics на своих предприятиях для проведения работ по производственному контролю и профилактическому обслуживанию, о чем информировал CNews. Вице-председатель Hyundai Motor Group Джэхун Чан (Jaehoon Chang) заявил тогда о том, что Boston Dynamics и робототехнический искусственный интеллект (ИИ) будут играть решающую роль в выполнении задач компании, позволив вывести бизнес на новый уровень. Роберт Плейтер добавил, что сотрудничество с Hyundai Motor Group позволит ей лучше понять производственные потребности автопроизводителя и то, как роботы смогут помочь ему повысить производительность и эффективность. После того как Роберт Плейтер покинет свой пост в конце февраля 2026 г., временно исполнять обязанности генерального директора Boston Dynamics будет Аманда Макмастер (Amanda McMaster), которая сейчас является финансовым директором компании. Ваш емейл адрес не будет опубликован. Обязательные поля отмечены * Сохранить моё имя, email и адрес сайта в этом браузере для последующих моих комментариев. Электронные компоненты Современная светотехника Политика в отношении обработки персональных данных Контакты
Images (1): 
|
|||||
| Boston Dynamics Atlas Fabrika Testlerine Başladı - ShiftDelete.Net | https://shiftdelete.net/boston-dynamics… | 1 | Feb 22, 2026 00:02 | active | |
Boston Dynamics Atlas Fabrika Testlerine Başladı - ShiftDelete.NetURL: https://shiftdelete.net/boston-dynamics-atlas-fabrika-testlerine-basladi Description: Boston Dynamics’in insansı robotu Atlas, Hyundai fabrikasında gerçek testlere başladı. Yapay zeka destekli üretimin geleceği şekilleniyor. Content:
Robotik dünyasının öncü ismi Boston Dynamics, efsanevi insansı robotu Atlas’ın yeteneklerini laboratuvar ortamından gerçek üretim sahalarına taşıdı. CBS News kanalında yayınlanan görüntülerde, tamamen elektrikli yeni nesil Atlas’ın Hyundai’nin Georgia eyaletindeki fabrikasında gerçek dünya görevlerini başarıyla yerine getirdiği görülüyor. Bu gelişme, yapay zeka destekli robotların endüstriyel üretime entegrasyonu açısından kritik bir dönüm noktası olarak kabul ediliyor. “İnsansılar Geliyor” başlıklı medya sunumunda tanıtılan Atlas, yapay zeka yardımıyla fabrika işlerini yapmayı öğreniyor. 360 derece dönebilen eklemleri ve gelişmiş makine öğrenimi yetenekleri sayesinde robot; otomobil parçalarını kaldırma, parçaları ayırma ve araç kapılarının montajı gibi zorlu fiziksel görevleri otonom olarak gerçekleştiriyor. Görüntü sensörleri sayesinde çevresindeki değişikliklere anında uyum sağlayabilen robot, insan müdahalesi olmadan karmaşık işlemleri tamamlayabiliyor. Hyundai’nin 2021 yılında SoftBank’tan satın aldığı Boston Dynamics, Atlas’ı ticari bir ürün haline getirmeyi hedefliyor. “Yazılım Tanımlı Fabrika” stratejisi çerçevesinde Hyundai, üretim tesislerine on binlerce robot yerleştirmeyi planlıyor. Georgia’daki tesiste montaj işlemlerinin yaklaşık yüzde 40’ının robotlar tarafından yapılması hedeflenirken, bu teknolojinin insanların yerine geçmekten ziyade tehlikeli ve ergonomik açıdan zorlayıcı görevleri üstlenerek iş güvenliğini artıracağı belirtiliyor. Yeni nesil Atlas, 5 Ocak tarihinde Las Vegas’ta düzenlenecek olan CES 2026 fuarında ilk kez halka açık bir şekilde sahneye çıkacak. Boston Dynamics yöneticileri, önümüzdeki birkaç yıl içinde Atlas’ın tamamen ticari kullanıma sunulacağını ifade ediyor. Bu hamleyle beraber robotik pazarında Tesla’nın Optimus ve Figure AI’nın Figure 02 gibi modelleri arasındaki rekabetin daha da artması bekleniyor. Fabrikalarda çalışmaya başlayan insansı robotlar hakkında siz neler düşünüyorsunuz? Sizce robotik iş gücü otomotiv sektörünü nasıl değiştirecek? İsmimi bu tarayıcıya kaydet Δ
Images (1): 
|
|||||
| World’s first full-stack humanoid robot open-sourced for developers | https://interestingengineering.com/ai-r… | 1 | Feb 21, 2026 00:03 | active | |
World’s first full-stack humanoid robot open-sourced for developersURL: https://interestingengineering.com/ai-robotics/worlds-first-full-stack-humanoid-robot-open-sourced Description: Beijing startup RoboParty open-sources Roboto Origin, a full-stack humanoid prototype, attracting 1,000+ GitHub Stars globally. Content:
From daily news and career tips to monthly insights on AI, sustainability, software, and more—pick what matters and get it in your inbox. Access expert insights, exclusive content, and a deeper dive into engineering and innovation. Engineering-inspired textiles, mugs, hats, and thoughtful gifts We connect top engineering talent with the world's most innovative companies. We empower professionals with advanced engineering and tech education to grow careers. We recognize outstanding achievements in engineering, innovation, and technology. All Rights Reserved, IE Media, Inc. Follow Us On Access expert insights, exclusive content, and a deeper dive into engineering and innovation. Engineering-inspired textiles, mugs, hats, and thoughtful gifts We connect top engineering talent with the world's most innovative companies We empower professionals with advanced engineering and tech education to grow careers. We recognize outstanding achievements in engineering, innovation, and technology. All Rights Reserved, IE Media, Inc. Roboto Origin achieves speeds of 3 m/s, using RoboParty’s AMP gait algorithm for smooth, stable, and natural humanoid movement. Beijing-based startup RoboParty has open-sourced its flagship bipedal humanoid, Roboto Origin, just months after completing R&D in 120 days. As the world’s first full-stack open-source bipedal humanoid prototype, it has quickly earned 1,000+ GitHub Stars and nearly 100 kit pre-orders. The firm, backed by $10M from MPCi, Xiaomi, and Galbot, RoboParty aims to advance embodied AI, with its next model featuring a Behavior Foundation Model (BMF). In April 2025, the Beijing-based startup, founded by 21-year-old Huang Yi, launched to build open-source bipedal humanoids, securing a seven-figure seed round from top investors. RoboParty’s journey began with founder Yi Huang at Harbin Institute of Technology, where he won a national tech competition in 2023 with an amphibious drone and built AlexBot, a $2,300 open-source bipedal robot in his dorm. This early work drew sponsorship from Fourier Intelligence and attention from Boston Dynamics founder Marc Raibert. Frustrated by the industry’s inefficiencies, Huang graduated early and launched RoboParty in 2025. The team developed Robot Origin in just 120 days (April–August 2025), a 1.25m, 75-pound (34 kilograms) prototype designed to validate end-to-end humanoid robotics workflows—not commercialization. Using decoupled parallel development, they iterated quickly, aligning hardware and software, testing Sim2Real feasibility, and demonstrating small-team agility. Rejecting short-term orders, RoboParty fully open-sourced Roboto Origin in January 2026, sharing hardware designs, software, and engineering insights to democratize humanoid robotics. The launch included a global developer co-creation program, creating a reproducible, extensible, and verifiable system. Roboto Origin runs at 3 m/s, powered by RoboParty’s self-developed AMP anthropomorphic gait algorithm for stable, natural motion. Its open-source scope spans the entire industrial chain: hardware (structural drawings, EBOM, SOP, supplier lists), software (low-level control code, SMPL-X human model adaptation), and engineering (Sim2Real gap solutions, debugging experience). According to RoboParty, with 1,000+ GitHub Stars and a growing developer community, Roboto Origin exemplifies collaborative progress in Embodied Infrastructure, setting a new standard for open, full-stack humanoid robotics. RoboParty’s open-source approach tackles the robotics industry’s three main challenges—high costs, fragmented designs, and disunified architectures—by creating a shared Embodied Infrastructure foundation. This model is expected to reduce development costs for humanoid robotics by up to 80 percent. According to the company, Roboto Origin has attracted top global talent, from university researchers to Fortune 500 engineers and startup technical teams, forming a collaborative network that accelerates innovation beyond individual organizations. A statement details that RoboParty maintains a global “Hands-On Humanoid Robot Problem List,” converting individual trial-and-error into collective knowledge. By open-sourcing full-link verification capabilities, the company empowers small teams and independent developers with equal access to high-performance foundational resources, democratizing embodied intelligence development. RoboParty’s roadmap: 2026—expand developer community, refine Roboto Origin, enable small-scale education and research use. 2027–2028—launch BMF robot, monetize components, support 500+ applications. Post-2029—build a universal humanoid platform for large-scale embodied AI deployment. “The ultimate endgame of humanoid robots lies in open collaborative Embodied Infrastructure. Our goal is to let the best robot solutions be born from this ecosystem, serving the whole world,” said Yi Huang, founder of RoboParty, in a statement. Jijo is an automotive and business journalist based in India. Armed with a BA in History (Honors) from St. Stephen's College, Delhi University, and a PG diploma in Journalism from the Indian Institute of Mass Communication, Delhi, he has worked for news agencies, national newspapers, and automotive magazines. In his spare time, he likes to go off-roading, engage in political discourse, travel, and teach languages. Exclusive content, expert insights and a deeper dive into engineering and tech. No ads, no limits. Exclusive content, expert insights and a deeper dive into engineering and tech. No ads, no limits. Premium Follow
Images (1): 
|
|||||
| Humanoid robotics company AGIBOT launches in Malaysia | https://www.manilatimes.net/2026/01/25/… | 0 | Feb 20, 2026 16:01 | active | |
Humanoid robotics company AGIBOT launches in MalaysiaDescription: EARLIER this month, Agibot, a robotics company specializing in embodied intelligence, officially launched in Malaysia, marking the first in a series of strategi... Content: |
|||||
| Unitree trionfa alla primissima edizione dei World Humanoid Robot Games | https://www.tecnoandroid.it/2025/08/26/… | 1 | Feb 20, 2026 00:03 | active | |
Unitree trionfa alla primissima edizione dei World Humanoid Robot GamesDescription: Unitree mette il turbo e vince ben quattro ori nella prima edizione dei giochi per robot umanoidi di Pechino Content:
Quest’anno a Pechino si è tenuta la primissima edizione dei Word Humanoid Robot Games che ha regalato davvero un sacco di emozioni. Questa competizione è considerato come il primo evento competitivo destinato esclusivamente ai robot umanoidi. Si tratta infatti di un’idea geniale nata proprio per mostrare al pubblico tutti i progressi e le applicazioni che la robotica può avere nei campi dello sport e del movimento in generale. A questa prima edizione i partecipanti sono stati numerosi, le squadre a partecipare sono state 280 provenienti da 16 paesi diversi, e nei prossimi anni ci si aspetta una partecipazione ancora più numerosa. Per quanto riguarda le discipline presenti, invece, ci si è sfidati in ben 26 eventi, comprendenti atletica, con le gare di staffette, corsa ostacoli, e varie gare di velocità, e sport come il calcio, il ballo e la boxe. Le gare messe in atto hanno sicuramente offerto uno spettacolo unico, mettendo in scena robot umanoidi che si sfidano in discipline fino a questo momento appannaggio degli esseri umani. Come detto in precedenza, la partecipazione è stata senz’altro notevole, ma c’è stato un vincitore assoluto della competizione. Infatti, Unitree Robotics, azienda cinese, ha sbaragliato la concorrenza grazie ai suoi modelli H1. I suoi robot umanoidi sono riusciti a conquistare ben 11 medaglie in totale, di cui quattro d’oro. Le discipline in cui sono state conquistate le quattro medaglie d’oro sono i 100 m ostacoli, i 400 m piani, i 1500 m e la staffetta 4X100. Il successo evidente dei giochi di Pechino ha permesso agli organizzatori di confermare già la prossima edizione, che si terrà nell’agosto del 2026 e si svolgerà sempre a Pechino. Il segnale che si intende mandare è che la robotica umanoide, vista finora probabilmente soltanto confinata nei laboratori, in futuro potrà sicuramente avere un ruolo molto importante nella vita quotidiana degli esseri umani. Studentessa di Medicina con la passione per la scienza, i libri e le serie tv 2012 – 2023 Tecnoandroid.it – Gestito dalla STARGATE SRLS – P.Iva: 15525681001 Testata telematica quotidiana registrata al Tribunale di Roma CON DECRETO N° 225/2015, editore STARGATE SRLS. Tutti i marchi riportati appartengono ai legittimi proprietari. Questo articolo potrebbe includere collegamenti affiliati: eventuali acquisti o ordini realizzati attraverso questi link contribuiranno a fornire una commissione al nostro sito. Inserisci qualcosa di speciale: Tienimi connesso fino a quando non esco Password dimenticata? Ti sarà inviata una nuova password via email. Hai ricevuto una nuova password? Accedi qui.
Images (1): 
|
|||||
| Unitree's humanoid robot clinches first gold at 2025 World Humanoid … | http://www.ecns.cn/news/cns-wire/2025-0… | 1 | Feb 20, 2026 00:03 | active | |
Unitree's humanoid robot clinches first gold at 2025 World Humanoid Robot GamesURL: http://www.ecns.cn/news/cns-wire/2025-08-15/detail-iheuffaz6231532.shtml Content:
(ECNS) -- A humanoid robot from Unitree Robotics clinched the gold medal in the 1500-meter race on Friday with 6 minutes and 34.40 seconds at the ongoing 2025 World Humanoid Robot Games in Beijing, the Chinese robotics firm announced on Friday. This marked the first gold medal awarded at the games. The award-winning Unitree H1 robot is the same model that performed during the 2025 Chinese Spring Festival Gala. The 2025 World Humanoid Robot Games kicked off on Thursday in Beijing, capital of China, showcasing the cutting-edge achievements of humanoid robots in intelligent decision-making and collaborative movement. (By Zhang Dongfang)
Images (1): 
|
|||||
| Unitree launches its first wheeled humanoid robot that can see, … | https://www.gizmochina.com/2025/11/13/u… | 1 | Feb 20, 2026 00:03 | active | |
Unitree launches its first wheeled humanoid robot that can see, grip, and learn - GizmochinaURL: https://www.gizmochina.com/2025/11/13/unitree-g1-d-wheeled-humanoid-robot-launched-specs/ Description: Unitree G1-D is a wheeled humanoid robot with hand and head cameras, up to 19 DOF, optional mobile base, and support for dexterous robotic hands. Content:
Unitree Robotics has officially introduced the G1-D, its first wheeled humanoid robot designed for advanced data collection and model training. The robot serves as the centerpiece of a full-stack solution that combines high-performance humanoid hardware with a scalable software platform for data acquisition, AI training, and real-world deployment. The G1-D is available in two versions: Standard and Flagship. Both models stand between 1260 mm and 1680 mm tall and weigh up to 80 kg. The Standard version is stationary, while the Flagship version features a mobile base that supports differential drive and can move at speeds of up to 1.5 meters per second. The mobile base includes sensors such as LiDAR, depth cameras, and collision detection units. Unitree has equipped the G1-D with 17 degrees of freedom on the Standard model and 19 on the Flagship model, excluding the end effectors. Each arm has seven degrees of freedom and supports a payload of up to 3 kg. The robot’s waist joint allows motion along the Z-axis up to ±155 degrees and along the Y-axis between -2.5 and +135 degrees. The platform supports a vertical working range of 0 to 2 meters. The robot features a high-definition binocular camera on its head and an additional HD camera on each wrist. It supports various end effectors, including a two-finger gripper, three-finger dexterous hands with or without tactile sensors, and a five-finger dexterous hand. Unitree has powered the G1-D with an Nvidia Jetson Orin NX module that delivers up to 100 TOPS of AI performance. The Flagship version offers a battery life of up to six hours. The G1-D is designed for a wide range of real-world applications. It can perform repetitive manual tasks in industrial and service environments, assist in warehouse automation, collect and annotate data for AI training, and even interact with retail or consumer settings using its onboard vision and mobility. The robotâs dexterous hands and mobile base allow it to manipulate objects, conduct inspections, or serve as a data-gathering agent in complex environments. Alongside the hardware, Unitree has launched a comprehensive software stack that manages the entire AI workflow. This includes data acquisition tools, task management, annotation systems, and real-time tracking. The platform supports distributed training and integrates with popular open-source frameworks such as GROOT and PI. It also includes a simulation environment for model evaluation and supports seamless export and deployment of trained models. In related news, Alibaba has recently unveiled its first self-developed AI glasses featuring swappable batteries, a POV camera, and the Qwen assistant. Meanwhile, an LSE study predicts that by 2028, Gen Alpha will rely on voice rather than keyboards at work. For more daily updates, please visit our News Section. Stay ahead in tech! Join our Telegram community and sign up for our daily newsletter of top stories! ð¡ (Source)
Images (1): 
|
|||||